FAQ
Using the FAQs
The answers and examples to the questions below assume that a workspace is instantiated and ready to use. There are many ways to instantiate a workspace, below is a simple way but it doesn’t matter how you create the Workspace, just so long as the state of the workspace and/or pipeline can be referenced and utilized. A simple example is below. There are much more verbose details in the Advanced Topics Section if you’d like a deeper explanation.
import com.databricks.labs.overwatch.utils.Upgrade
import com.databricks.labs.overwatch.pipeline.Initializer
val params = OverwatchParams(...)
val prodArgs = JsonUtils.objToJson(params).compactString
// A more verbose example is available in the example notebooks referenced above
val prodWorkspace = Initializer(prodArgs, debugFlag = true)
val upgradeReport = Upgrade.upgradeTo042(prodWorkspace)
display(upgradeReport)
Q1: How To Clean Re-Deploy
I just deployed Overwatch and made a mistake and want to clean up everything and re-deploy. I can’t seem to get a clean state from which to begin though.
Overwatch tables are intentionally created as external tables. When the etlDataPathPrefix is configured (as recommended) the target data does not live underneath the database directory and as such is not deleted when the database is dropped. This is considered an “external table” and this is done by design to protect the org from someone accidentally dropping all data globally. For a FULL cleanup you may use the functions below but these are destructive, be sure that you review it and fully understand it before you run it.
CRITICAL: CHOOSE THE CORRECT FUNCTION FOR YOUR ENVIRONMENT If Overwatch is configured on multiple workspaces, use the multi-workspace script otherwise, use the single workspace functions. Please do not remove the safeguards as they are there to protect you and your company from accidents.
SINGLE WORKSPACE DEPLOYMENT DESTROY AND REBUILD
single_workspace_cleanup.dbc | single_workspace_cleanup.html
MULTI WORKSPACE DEPLOYMENT DESTROY AND REBUILD
First off, don’t practice deploy a workspace to the global Overwatch data target as it’s challenging to clean-up; nonetheless, the script below will remove the data from this workspace from the global dataset and reset this workspace for a clean run.
multi_workspace_cleanup.dbc | multi_workspace_cleanup.html
Q2: The incorrect costs were entered for a specific time range, I’d like to correct them, how should I do that?
Please refer to the Configuring Custom Costs to baseline your understanding. Also, closely review the details of the instanceDetails table definition as that’s where costs are stored and this is what will need to be accurate. Lastly, please refer to the Pipeline_Management section of the docs as you’ll likely need to understand how to move the pipeline through time.
Now that you have a good handle on the costs and the process for restoring / reloading data, note that there are ultimately two options after you reconfigure the instancedetails table to be accurate. There are two tables that are going to have inaccurate data in them:
- jobruncostpotentialfact_gold
- clusterstatefact
Options
- Completely drop tables, delete their underlying data and rebuild them from the primordial date
- Delete all records where Pipeline_SnapTS >= the time where the data became inaccurate.
Both options will require a corresponding appropriate update to the pipeline_report table for the two modules that write to those tables (3005, 3015). Here are several examples on ways to update the pipeline_report to change update the state of a module.
Q3: What is the current guidance / state of customers who want to capture EC2 spot pricing?
The easiest way is to identify an “average” SPOT price and apply it to all compute cost calcuations. Going a bit further, calculate average spot price by region, average spot price by region by node type and lastly down to a time resolution like hour of day. Use the AWS APIs to get the historical spot price at by these dims.This can be automated via a little script they build but it require proper access to the AWS account.
display(
spark.table("overwatch.clusterstatefact")
.withColumn("compute_cost", applySpotDiscount('awsRegion, 'nodeTypeID)
)
where applySpotDiscount is the lookup function that either hits a static table of estimates or a live API endpoint from AWS.
It’s a very simple API call,just need the token to do it.It’s extremely powerful for shaping/optimizing job run timing, node types, AZs, etc
Sample Request:
&StartTime=2020-11-01T00:00:00.000Z
&EndTime=2020-11-01T23:59:59.000Z
&AvailabilityZone=us-west-2a
&AUTHPARAMS
Sample Response:
<requestId>59dbff89-35bd-4eac-99ed-be587EXAMPLE</requestId>
<spotPriceHistorySet>
<item>
<instanceType>m3.medium</instanceType>
<productDescription>Linux/UNIX</productDescription>
<spotPrice>0.287</spotPrice>
<timestamp>2020-11-01T20:56:05.000Z</timestamp>
<availabilityZone>us-west-2a</availabilityZone>
</item>
<item>
<instanceType>m3.medium</instanceType>
<productDescription>Windows</productDescription>
<spotPrice>0.033</spotPrice>
<timestamp>2020-11-01T22:33:47.000Z</timestamp>
<availabilityZone>us-west-2a</availabilityZone>
</item>
</spotPriceHistorySet>
<nextToken/>
</DescribeSpotPriceHistoryResponse>
More Details: https://docs.aws.amazon.com/AWSEC2/latest/APIReference/API_DescribeSpotPriceHistory.html
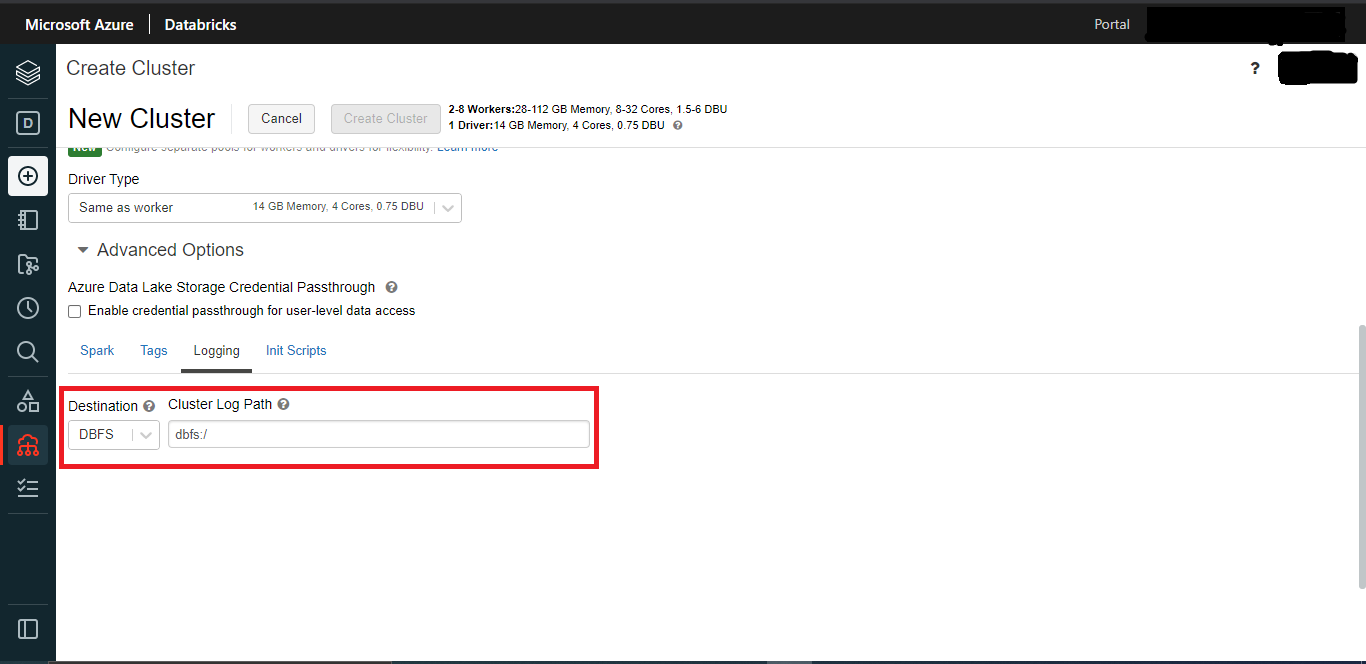
Q4: How to config the cluster logs path?
The cluster logging paths are automatically acquired within Overwatch. There’s no need to tell Overwatch where to load those from.
Click here for more details.
Q5: Can I configure custom log4j appender settings
Yes, Overwatch does not ingest from log4j output files; thus this can be edited as per customer needs without any impact on Overwatch. Overwatch utilizes the spark event logs from the cluster logs direction, not the stdout, stderr, or the log4j.
Q6: I’d like to add or update workspace_name on my Overwatch deployment, is there an easy way to do that?
Yes, follow the instructions in the script posted below. DBC | HTML
Q7: I’d like to have cluster policies to ensure all future interactive and automated clusters have an appropriate logging location
Use the Databricks Docs on Cluster Policies to define appropriate cluster policies as per your requirements. To enforce logging location on interactive, automated, or both use the examples below and apply them to your cluster policies appropriately.
- Interactive Cluster Policy Only
- Automated Cluster Policy Only
- Interactive AND Automated Cluster Policy
Q8: Can I deploy Overwatch on Unity Catalog (UC)
Yes!
As of v0.7.2.0 You can deploy Overwatch on your UC-enabled workspace.
We have also provided a step-by-step migration guide to help you migrate your existing Overwatch data.
hint: On top of the added security benefits of UC, deploying Overwatch onto it will significantly improve the deployment process
for Azure customers in the future, since Overwatch will soon leverage System Tables as the bronze layer source of data when applicable.
Q9: How to enable user-email tracking in sparkJob Table for DBR versions < 11.3
Until DBR 11.3+ the user_email field in sparkJob table was incomplete as Databricks did not begin publishing this
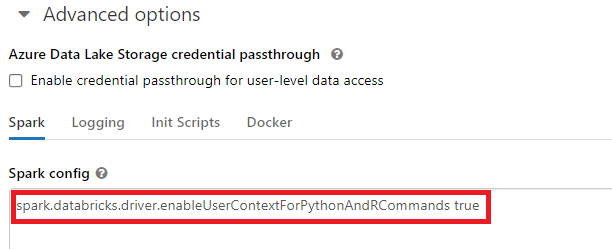
in all cases until that version. To enable event log reporting for user_email in DBR versions < 11.3, set the following
command to true in the cluster’s spark config. This can be done in the cluster config or through an init script. Any
clusters running on DBR < 11.3 without this config will not report user_email for Python and R interactive workloads.
spark.databricks.driver.enableUserContextForPythonAndRCommands
To enable this globally, it’s recommended to utilize cluster policies or global_init scripts.
If you set this property and someone in your org depends on one of these fields for their workflow this will overwrite their value. They should not be doing this and if they are they need to stop before 11.3 as this will be part of DBR by then. For example if a dev team is using something like “if not sc.getLocalProperty(“user”): doThing()” then this will now be set so their code would break.
Q10: My view is giving me some strange error when I try to select from it, how do I fix it?
Occasionally the views have an issue with their refresh and get stuck. If you’re having a strange error with your view, try the following code snipped to try and repair it.
import com.databricks.labs.overwatch.pipeline.Gold
import com.databricks.labs.overwatch.utils.Helpers
val myETLDB = "overwatch_etl" // CHANGE ME
val nameOfMisbehavingView = "jobrun" // CHANGE ME
spark.sql(s"drop view ${myETLDB}.${nameOfMisbehavingView}")
val workspace = Helpers.getWorkspaceByDatabase(myETLDB)
val gold = Gold(workspace)
gold.refreshViews()
Q11: An API call is resulting in Job Aborted what can I do
This can be due to a large resulting dataset. To validate download the appropriate logs and search for
spark.rpc.message.maxSize. If you don’t find skip ahead, if you do find it, add the following parameter to
the spark config of the Overwatch cluster. spark.rpc.message.maxSize 1024.
If the issue wasn’t the RPC size reduce the size of the “SuccessBatchSize” in the APIENV configuration (as of 0.7.0)