AWS
Configuring Overwatch on AWS - Databricks
Reach out to your Customer Success Engineer (CSE) to help you with these tasks as needed.
There are two primary sources of data that need to be configured:
- Audit Logs-AWS
- The audit logs contain data for every interaction within the environment and are used to track the state of various objects through time along with which accounts interacted with them. This data is relatively small and delivery occurs infrequently which is why it’s rarely of any consequence to deliver audit logs to buckets even outside of the control plane region.
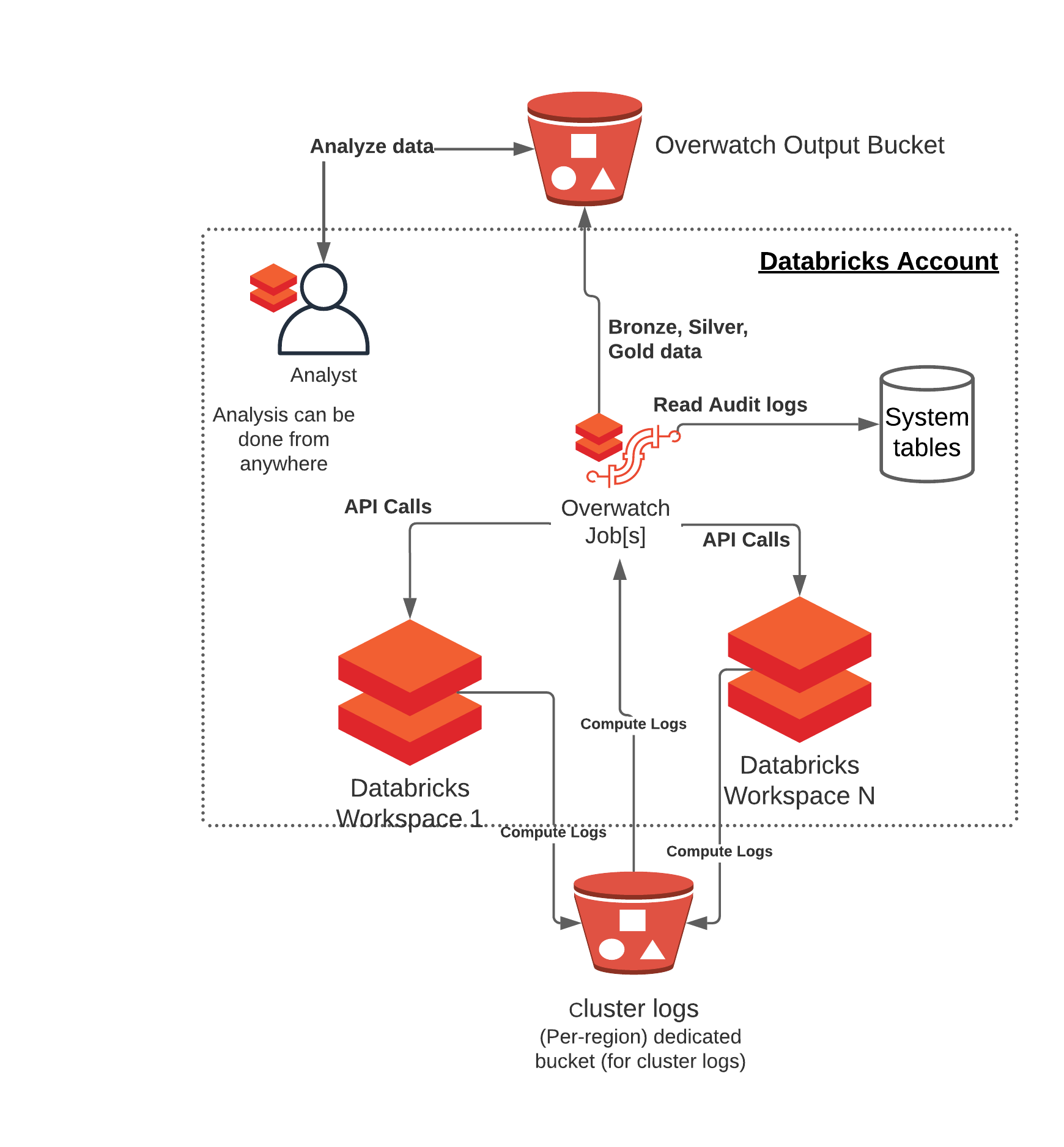
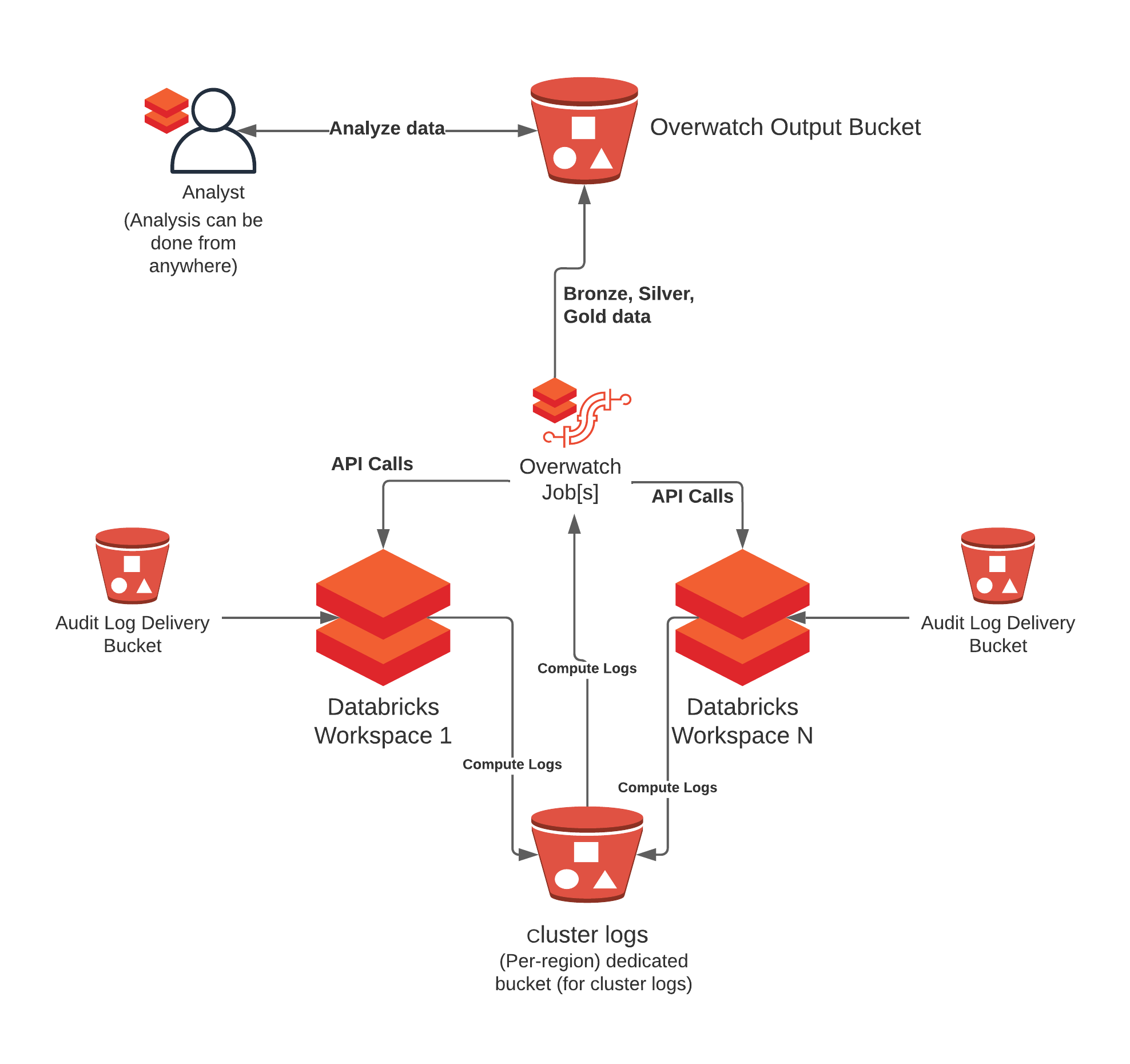
- For ingesting this data, you have the option of using System tables (RECOMMENDED) or you can configure the audit logs to be delivered to the configured bucket. These buckets are configured on a per-workspace basis and can be delivered to the same target bucket, just ensure that the prefixes are different to avoid collisions. We don’t want multiple workspaces delivering into the same prefix.
- Cluster Logs - Crucial to get the most out of Overwatch
- Cluster logs delivery location is configured in the cluster spec –> Advanced Options –> Logging. These logs can get quite large and they are stored in a very inefficient format for query and long-term storage. As such, it’s crucial to store these logs in the same region as the worker nodes for best results. Additionally, using dedicated buckets provides more flexibility when configuring TTL (time-to-live) to minimize long-term, unnecessary costs. It’s not recommended to store these on DBFS directly.
- Best Practice - Multi-Workspace – When multiple workspaces are using Overwatch within a single region it’s best to ensure that each are going to their own prefix, even if sharing a storage account. This greatly reduces Overwatch scan times as the log files build up. If scan times get too long, the TTL can be reduced or additional storage accounts can be created to increase read IOPS throughput (rarely necessary) intra-region.
Reference Architecture
As of 0.7.1 Overwatch can be deployed on a single workspace and retrieve data from one or more workspaces. For more details on requirements see Multi-Workspace Consideration. There are many cases where some workspaces should be able to monitor many workspaces and others should only monitor themselves. Additionally, co-location of the output data and who should be able to access what data also comes into play, this reference architecture can accommodate all of these needs. To learn more about the details walk through the deployment steps
| Using System tables | Using S3 Delivery |
|---|---|
 |
 |
With Databricks Billable Usage Delivery Logs/billing system table
Detailed costs data directly from Databricks. This data can significantly enhance deeper level cost metrics, and t’s easy to join these up with the Overwatch data for cost validation and / or exact cost break down by dimensions not supported in the usage logs/billing system table.