Pipeline_Management
Overwatch Data Promotion Process
Overwatch data is promoted from bronze - silver - gold - presentation to ensure data consistency and quality as the data is enriched between the stages. The presentation layer is composed of views that reference the latest schema version of the gold layer. This disconnects the consumption layer from the underlying data structure so that developers can transparently add and alter columns without user disruption. All tables in each layer (except consumption) are suffixed in the ETL database with _layer.
Note, the ETL database and consumption database are usually different, determined by the configuration.
Common Terms & Concepts
Snapshot
A snapshot is a point in time image of a context. For example, Cluster and Job definitions come and go in a Databricks workspace but at the time of an Overwatch run, there is a state and the snapshots capture this state.
Several snapshot tables can be found in the bronze layer such as clusters_snapshot_bronze. As a specific example, this snapshot is an entire capture of all existing clusters and definitions at the time of the Overwatch run. This is an important reference point, especially in the early days of running Overwatch, as depending on when the process and logging was begun, many of the existing clusters were created (and last edited) before the audit logs could capture it therefore, the existence and metadata of a cluster would be missing from Overwatch if not for the snapshot. The snapshots also serve as a good last resort lookup for any missing data through time, espeically as it pertains to assets that exist for a longer period of time.
Snapshots should not be the first choice when looking for data regarding slow changing assets (such as clusters) as the resolution is expectedly low, it’s much better to hit the slow changing dimensions in gold, cluster, or even in silver such as cluster_spec_silver. If the raw data you require has not been enriched from raw state then you likely have no other choice than to go directly to the audit logs, audit_log_bronze, and filter down to the relevant service_name and action.
Job
Be weary of the term JOB when working with Overwatch (and Spark on Databricks in general). A Databricks Job is a very different entity than a Spark Job. The documentation attempts to be very clear, please file a ticket if you find a section in which the difference is not made clear.
Spark Context Composition & Hierarchy
Data Ingestion and Resume Process
The specificities can vary slightly between cloud provider but the general methodology is the exact same.
Each module is responsible for building certain entities at each layer, bronze, silver, gold, and presentation. The mapping between module and gold entity can be found in the Modules section. Each module is also tracked individually in the primary tracking tabe, Pipeline_Report.
The Overwatch Execution Process
Each Overwatch Run takes a snapshot at a point in time and will be the uppermost timestamp for which any data will be captured. Each Overwatch Run also derives an associated GUID by which it can be globally identified throughout the run. Each record created during the run will have an associated Overwatch_RunID and Pipeline_SnapTS which can be used to determine exactly when a record was loaded.
The “from_time” will be derived dynamically for each module as per the previous run snapshot time for the given module plus one millisecond. If the module has never been executed, the primordialDateString will be used which is defined as current_date - 60 days, by default. This can be overridden in the config. Some modules can be very slow / time-consuming on the first run due to the data volume and/or trickle loads from APIs. Best practice is to set your primordialDateString (if desired > 60d) AND set “maxDaysToLoad” to a low number like 5. It’s important to balance sufficient data to fully build out the implicit schemas and small enough data to get through an initial valid test.
More best practices can be found in the Best Practices section; these are especially important to reference when getting started.
The Pipeline Report
The Pipeline_Report table is the state table for the Overwatch pipeline. This table controls the start/stop points for each module and tracks the status of each run. Manipulating this table will change the way Overwatch executes so be sure to read the rest of this page before altering this table.
The Pipeline Report is very useful for identifying issues in the pipeline. Each module, each run is detailed here. The structure of the table is outlined below.
Pipeline_Report Structure
KEY – organization_id + moduleID + Overwatch_RunID
Write Mode – Append
For the developers – This output is created as a DataSet via the Case Class com.databricks.labs.overwatch.utils.ModuleStatusReport
| Column | Type | Description |
|---|---|---|
| organization_id | string | Canonical workspace id |
| workspace_name | string | Customizable human-legible name of the workspace, should be globally unique within the organization |
| moduleId | int | Module ID – Unique identifier for the module |
| moduleName | string | Name of the module |
| primordialDateString | string | The date from which Overwatch will capture the details. The format should be yyyy-MM-dd ex: 2022-05-20 == May 20 2022 |
| runStartTS | long | Snapshot time of when the Overwatch run begins |
| runEndTS | long | Snapshot time of when the Overwatch run ends |
| fromTS | long | The snapshot start time from which data will be loaded for the module |
| untilTS | long | The snapshot final time from which data will be loaded for the module. This is also the epoch millis of Pipeline_SnapTS |
| status | string | Terminal Status for the module run (SUCCEEDED, FAILED, ROLLED_BACK, EMPTY, etc). When status is failed, the error message and stack trace that can be obtained is also placed in this field to assist in finding issues |
| writeOpsMetrics | map | Contains write metric for a particular chunk of data written to a table. It has information like number of files, Output Rows and Output bytes being written |
| lastOptimizedTS | long | Epoch millis of the last delta optimize run. Used by Overwatch internals to maintain healthy and optimized tables. |
| vacuumRetentionHours | int | Retention hours for delta – How long to retain deleted data |
| inputConfig | struct | Captured input of OverwatchParams config at time of module run |
| parsedConfig | struct | The config that was parsed into OverwatchParams through the json deserializer |
| Pipeline_SnapTS | timestamp | Timestamp when the module was completed as part of the pipeline. This timestamp is reported in server time. |
| Overwatch_RunID | string | GUID for the overwatch run |
The PipReport View
A pipReport view has been created atop the pipeline_report table to simplify reviewing the historical runs. The query most commonly used is below. If you are asked for the pipReport, please provide the output from the following
SCALA
table("overwatch_etl.pipReport")
.filter('organization_id === "<workspace_id>") // if you want to see the pipReport for only a specific workspace
.orderBy('Pipeline_SnapTS.desc)
SQL
select * from overwatch_etl.pipReport
where organization_id = '<workspace_id>' -- if you want to see the pipReport for only a specific workspace
order by Pipeline_SnapTS desc
The structure of the table is outlined below.
PipReport Structure
KEY – organization_id + moduleID + Overwatch_RunID
Write Mode – Append
| Column | Type | Description |
|---|---|---|
| organization_id | string | Canonical workspace id |
| workspace_name | string | Customizable human-legible name of the workspace, should be globally unique within the organization |
| module_id | int | Module ID – Unique identifier for the module |
| module_name | string | Name of the module |
| primodialDate | date | The date from which Overwatch will capture the details. The format should be yyyy-MM-dd ex: 2022-05-20 == May 20 2022 |
| fromTS | long | The snapshot start time from which data will be loaded for the module |
| untilTS | long | The snapshot final time from which data will be loaded for the module. This is also the epoch millis of Pipeline_SnapTS |
| status | string | Terminal Status for the module run (SUCCEEDED, FAILED, ROLLED_BACK, EMPTY, etc). When status is failed, the error message and stack trace that can be obtained is also placed in this field to assist in finding issues |
| write_metrics | string | Contains write metric for a particular chunk of data written to a table. It has information like number of files, Output Rows and Output bytes being written. |
| Pipeline_SnapTS | timestamp | Timestamp when the module was completed as part of the pipeline. This timestamp is reported in server time. |
| Overwatch_RunID | string | GUID for the overwatch run |
Overwatch Time
Overwatch will default timezone to that of the server / cluster on which it runs. This is a critical point to be aware of when aggregating Overwatch results from several workspaces across different regions.
Module Dependencies
Several modules depend on other modules as source input; as such, as you can imagine, we don’t want modules to progress if one of their dependencies is erroring out and not populating any data. To handle this, Modules have dependencies such that upstream failures will cause downstream modules to be ineligible to continue. There are several types of errors that result in a module failure, and those errors are written out in the pipeline_report when they occur. Sometimes, there will truly be no new data in an upstream Module, this is ok and will not stop the progression of the “until” time as no data is not considered an error. Below are the ETL Modules and their dependencies
Module Dependencies Diagram
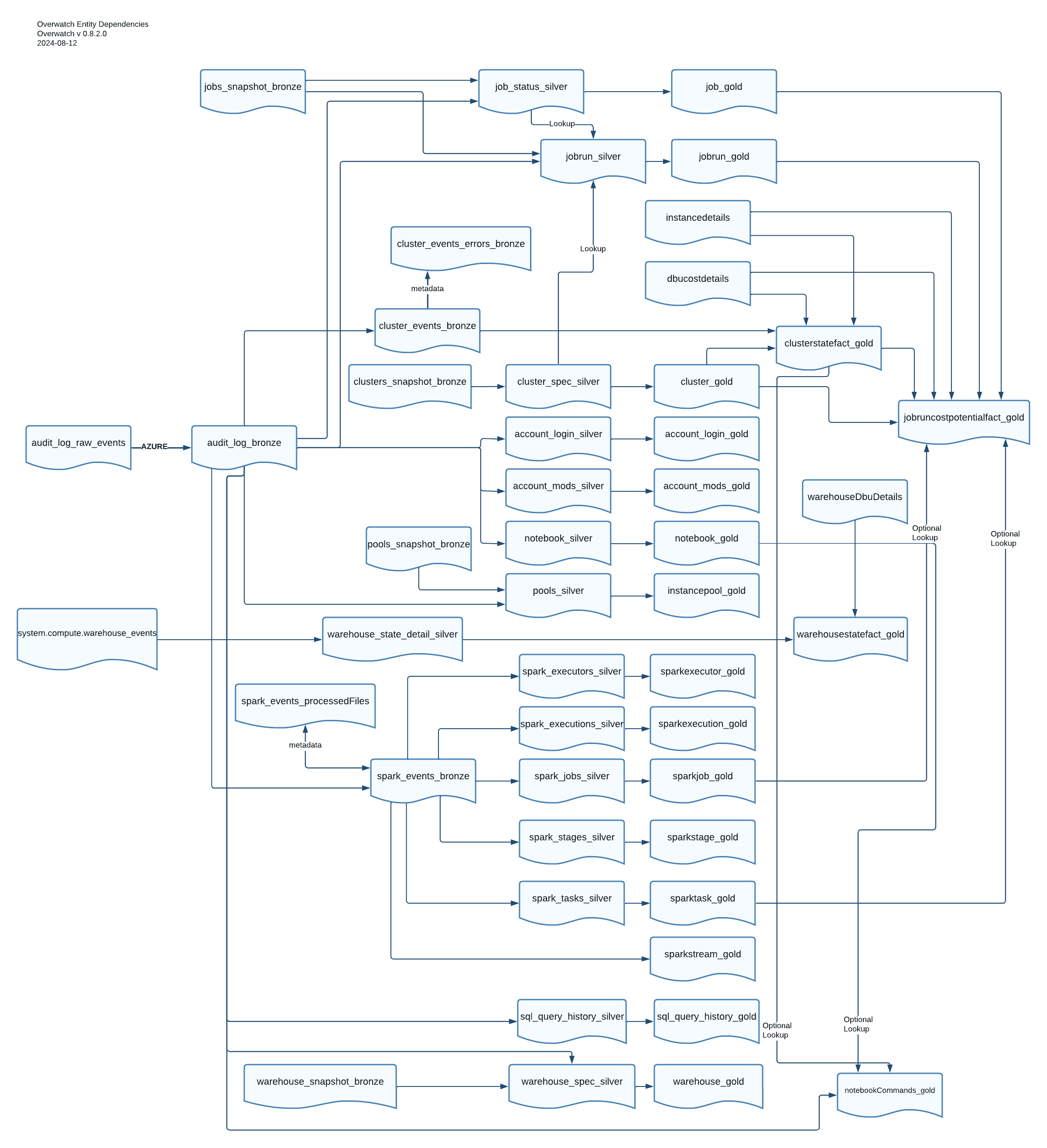
| Module ID | Module Name | Target Table Name | Module ID Dependencies | As Of |
|---|---|---|---|---|
| 1001 | Bronze_Jobs_Snapshot | jobs_snapshot_bronze | 0.6.0 | |
| 1002 | Bronze_Clusters_Snapshot | clusters_snapshot_bronze | 0.6.0 | |
| 1003 | Bronze_Pools | pools_snapshot_bronze | 0.6.0 | |
| 1004 | Bronze_AuditLogs | audit_log_bronze | 0.6.0 | |
| 1005 | Bronze_ClusterEventLogs | cluster_events_bronze | 1004 | 0.6.0 |
| 1006 | Bronze_SparkEventLogs | spark_events_bronze | 1004 | 0.6.0 |
| 1007 | Bronze_Libraries_Snapshot | libs_snapshot_bronze | 0.7.1.1 | |
| 1008 | Bronze_Policies_Snapshot | policies_snapshot_bronze | 0.7.1.1 | |
| 1009 | Bronze_Instance_Profile_Snapshot | instance_profiles_snapshot_bronze | 0.7.1.1 | |
| 1010 | Bronze_Token_Snapshot | tokens_snapshot_bronze | 0.7.1.1 | |
| 1011 | Bronze_Global_Init_Scripts_Snapshot | global_inits_snapshot_bronze | 0.7.1.1 | |
| 1012 | Bronze_Job_Runs_Snapshot* | job_runs_snapshot_bronze | 0.7.1.1 | |
| 1013 | Bronze_Warehouses_Snapshot | warehouses_snapshot_bronze | 0.7.2 | |
| 2003 | Silver_SPARK_Executors | spark_executors_silver | 1006 | 0.6.0 |
| 2005 | Silver_SPARK_Executions | spark_executions_silver | 1006 | 0.6.0 |
| 2006 | Silver_SPARK_Jobs | spark_jobs_silver | 1006 | 0.6.0 |
| 2007 | Silver_SPARK_Stages | spark_stages_silver | 1006 | 0.6.0 |
| 2008 | Silver_SPARK_Tasks | spark_tasks_silver | 1006 | 0.6.0 |
| 2009 | Silver_PoolsSpec | pools_silver | 1003,1004 | 0.6.0 |
| 2010 | Silver_JobsStatus | job_status_silver | 1004 | 0.6.0 |
| 2011 | Silver_JobsRuns | jobrun_silver | 1004,2010,2014 | 0.6.0 |
| 2014 | Silver_ClusterSpec | cluster_spec_silver | 1004 | 0.6.0 |
| 2016 | Silver_AccountLogins | accountlogin | 1004 | 0.6.0 |
| 2017 | Silver_ModifiedAccounts | account_mods_silver | 1004 | 0.6.0 |
| 2018 | Silver_Notebooks | notebook_silver | 1004 | 0.6.0 |
| 2019 | Silver_ClusterStateDetail | cluster_state_detail_silver | 1005 | 0.6.0 |
| 2020 | Silver_SQLQueryHistory | sql_query_history_silver | 1004 | 0.7.0 |
| 2021 | Silver_WarehouseSpec | warehouse_spec_silver | 1004,1013 | 0.7.2 |
| 2022 | Silver_WarehouseStateDetail | warehouse_state_detail_silver | 1004,1013 | 0.8.2 |
| 3001 | Gold_Cluster | cluster_gold | 2014 | 0.6.0 |
| 3002 | Gold_Job | job_gold | 2010 | 0.6.0 |
| 3003 | Gold_JobRun | jobrun_gold | 2011 | 0.6.0 |
| 3004 | Gold_Notebook | notebook_gold | 2018 | 0.6.0 |
| 3005 | Gold_ClusterStateFact | clusterstatefact_gold | 1005,2014 | 0.6.0 |
| 3007 | Gold_AccountMod | account_mods_gold | 2017 | 0.6.0 |
| 3008 | Gold_AccountLogin | account_login_gold | 2016 | 0.6.0 |
| 3009 | Gold_Pools | instancepool_gold | 2009 | 0.6.0 |
| 3010 | Gold_SparkJob | sparkjob_gold | 2006 | 0.6.0 |
| 3011 | Gold_SparkStage | sparkstage_gold | 2007 | 0.6.0 |
| 3012 | Gold_SparkTask | sparktask_gold | 2008 | 0.6.0 |
| 3013 | Gold_SparkExecution | sparkexecution_gold | 2005 | 0.6.0 |
| 3014 | Gold_SparkExecutor | sparkexecutor_gold | 2003 | 0.6.0 |
| 3016 | Gold_SparkStream | sparkstream_gold | 1006,2005 | 0.7.0 |
| 3015 | Gold_jobRunCostPotentialFact | jobruncostpotentialfact_gold | 3001,3003,3005,3010,3012 | 0.6.0 |
| 3017 | Gold_Sql_QueryHistory | sql_query_history_gold | 2020 | 0.7.0 |
| 3018 | Gold_Warehouse | warehouse_gold | 2021 | 0.7.2.1 |
| 3019 | Gold_NotebookCommands | notebookCommands_gold | 1004,3004,3005 | 0.7.2.1 |
| 3020 | Gold_WarehouseStateFact | warehousestatefact_gold | 2021, 2022 | 0.8.2 |
* Bronze_Job_Runs_Snapshot is experimental as of 0711. The module works as expected but the API can only pull
25 runs per API call; therefore, for some customers with many runs per day (i.e. thousands) this module can take
several hours. If you truly want this module enabled you can enable it but additional optimization work may be
required to make it efficient if your workspace executes thousands of job runs per day. TO ENABLE set the
following as a cluster spark config overwatch.experimental.enablejobrunsnapshot true
Reloading Data
CAUTION Be very careful when attempting to reload bronze data, much of the bronze source data expires to minimize storage costs. Reloading bronze data should be a very rare task (hopefully never necessary)
The need may arise to reload data. This can be easily accomplished by setting the “Status” column to “ROLLED_BACK” for the modules you wish to reload where:
- fromTime column > some point in time OR
- Overwatch_RunID === some Overwatch_Run_ID (useful if duplicates get loaded)
Remember to specify the ModuleID for which you want to reload data.
Reloading Data Example
Scenario Something has occurred and has corrupted the jobrun entity after 01-01-2021 but the issue wasn’t identified until 02-02-2021. To fix this, all data from 12-31-2020 forward will be rolled back. Depending on the details, the untilTime for the run on 12-31-2020 to ensure no data gaps or overlaps (for the examples below we’ll assume the untilTime was midnight on 12-31-2020); for this scenario we will go back an extra day and use Pipeline_SnapTS as the incremental time column. Since we’re using delta, we are safe to perform updates and deletes without fear of losing data (In the event of an issue the table could be restored to a previous version using delta time travel).
Reloading spark silver requires one extra step. If reloading spark silver data click the link.
Steps – Automatic Method As Of version 0.7.0 The following example will automatically detect the point in time at which the modules had a break point in the pipeline to ensure there are no data gaps or overlaps.
import com.databricks.labs.overwatch.utils.Helpers
val workspace = Helpers.getWorkspaceByDatabase("overwatch_etl")
val rollbackToTS = 1609416000000L // unix millis midnight Dec 31 2020
val modulesToRollback = Array(3005, 3015) // gold cost tables
val isDryRun = true // switch to false when you're ready to run
val rollbackStatusText = "DataRepair_Example" // text to appear in the status column after the rollback
val workspaceIDs = Array("123", "456") // two workspaces to rollback the modules in
// val workspaceIDs = Array("global") // use "global" to rollback all workspaces
// Putting it all together
Helpers.rollbackPipelineForModule(workspace, rollbackToTS, modulesToRollback, workspaceIDs, isDryRun, rollbackStatusText)
Steps – Manual Method: The method below is completely viable and the method used for years prior to the automated method above. It can be challenging to rollback each module to exactly the right timestamp to ensure no data gaps or overlaps. The method below assumes that the pipeline’s untilTime (from pipReport) for the run ended exactly at midnight to ensure zero gaps or overlaps.
- Verify Overwatch isn’t currently running and isn’t about to kick off for this workspace.
- Delete from jobRun_silver table where Pipeline_SnapTS >= “2020-12-31”
spark.sql("delete from overwatch_etl.jobRun_Silver where organization_id = '<ord_id>' and cast(Pipeline_SnapTS as date) >= '2020-12-31' ")
- Delete from jobRun_gold table where Pipeline_SnapTS >= “2020-12-31”
spark.sql("delete from overwatch_etl.jobRun_Gold where organization_id = '<ord_id>' and cast(Pipeline_SnapTS as date) >= '2020-12-31' ")
- Update the Pipeline_Report table set Status = “ROLLED_BACK” where moduleId in (2011,3003) and status in (‘SUCCESS’, ‘EMPTY’).
- Modules 2011 and 3003 are the Silver and Gold modules for jobRun respectively
- Only for Status values of ‘SUCCESS’ and ‘EMPTY’ because we want to maintain any ‘FAILED’ or ‘ERROR’ statuses that may be present from other runs
spark.sql(s"update overwatch_etl.pipeline_report set status = 'ROLLED_BACK' where organization_id = '<ord_id>' and moduleID in (2011,3003) and (status = 'SUCCESS' or status like 'EMPT%') ")
After performing the steps above, the next Overwatch run will load the data from 12-31 -> current.
Rebuilding Spark Bronze – If you want to reprocess data in the spark modules, it’s strongly recommended that you never truncate / rebuild spark_events_bronze as the data is quite large and the source log files have probably been removed from source due to retention policies. If you must spark bronze you must also update one other table; spark_events_processedfiles in the etl database. If you’re rolling back the spark modules from Feb 02, 2021 to Dec 31, 2020, you would need to delete the tracked files where Pipeline_SnapTS >= Dec 31, 2020 and failed = false and withinSpecifiedTimeRange = true.
For smaller, dimensional, silver/gold entities and testing, it’s often easier to just drop the table than it is to delete records after some date. Remember, though, it’s critical to set the primordialDateString from time if rebuilding entities with more than 60 days.
Running Only Specific Layers
As in the example above, it’s common to need to rerun only a certain layer for testing or reloading data. In the example above it’s inefficient to run the bronze layer repeatedly to reprocess two tables in silver and gold. If no new data is ingested into bronze, no modules outside of the two we rolled_back will have any new data and thus will essentially be skipped resulting in the re-processing of only the two tables we’re working on.
The main class parameters allows for a single pipeline (bronze, silver, or gold) or all to be run. Refer to the Getting Started - Run Via Main Class for more information on how to run a single pipeline from main class. The same can also be done via a notebook run, refer to Getting Started - Run Via Notebook for more information on this.