As A JAR
Deploying Overwatch As A JAR On Databricks Workflows
This deployment method requires Overwatch Version 0.7.1.0+
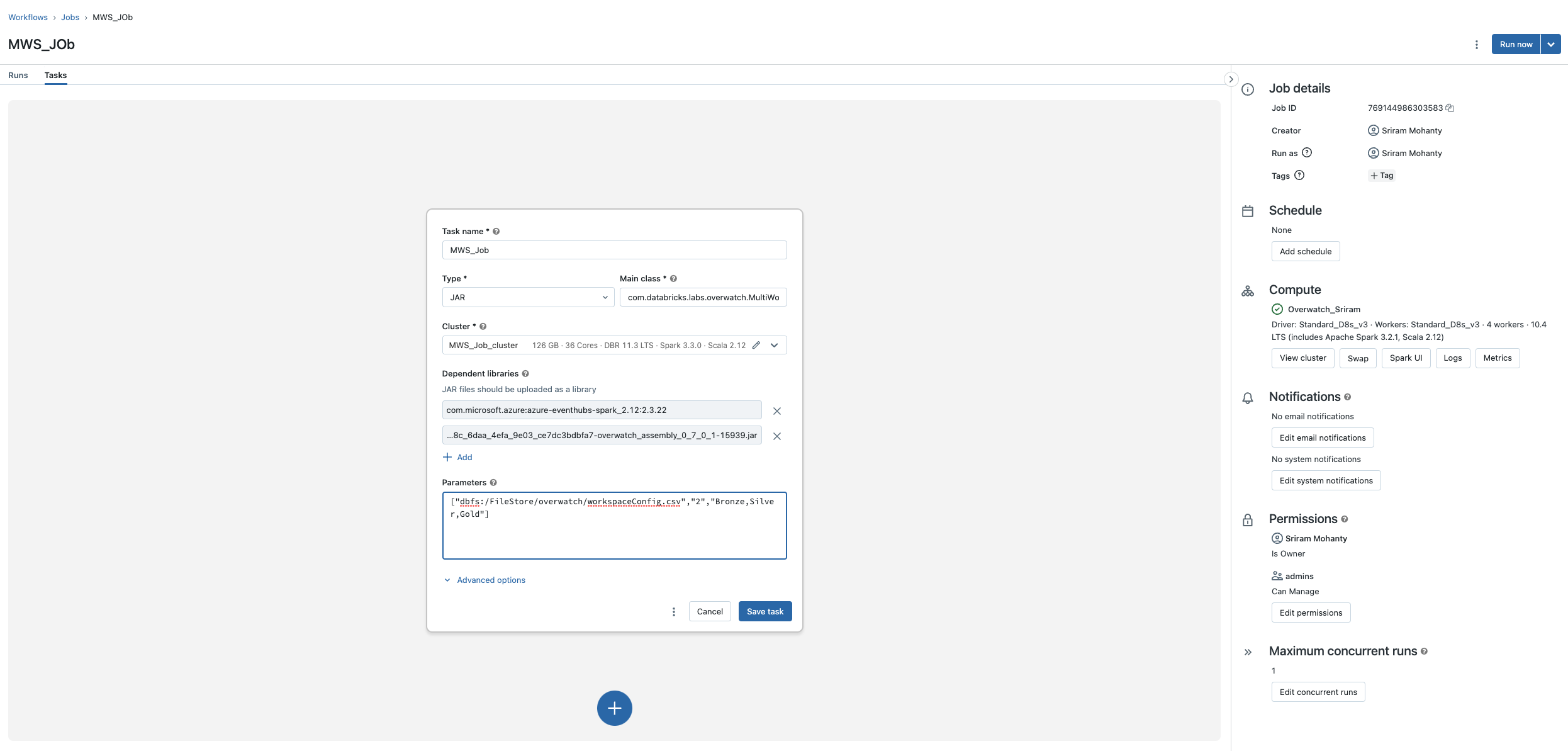
Main Class
The main class for job is com.databricks.labs.overwatch.MultiWorkspaceRunner
Dependent Library
com.databricks.labs:overwatch_2.12:0.8.x.x
com.microsoft.azure:azure-eventhubs-spark_2.12:2.3.21 (Azure only - If not using system tables)
com.microsoft.azure:msal4j:1.10.1 (Azure Only - With AAD Auth For EH, if not using system tables)
Parameters
As of 0.7.1.1 the config.csv referenced below can be any one of the following
- “dbfs:/path/to/config.csv” – original config csv approach still works (must end with .csv)
- “dbfs:/path/to/deltaTable” – path to a delta table containing the config
- “myDatabase.myConfigTable” – name of delta table that contains the config
Note: any of the paths in examples above may be on any supported storage, dbfs:/ is not required.
Job can take upto 3 arguments
- Args(0): Path of Config.csv (Mandatory)
- EX:
["dbfs:/path/to/config.csv"]
- EX:
- Args(1): Number of threads to complete the task in parallel. Default == 4. (Optional)
- EX:
["dbfs:/path/to/config.csv", "4"]
- EX:
- Args(2): Pipelines to be executed. Default == “Bronze,Silver,Gold”
- If you wanted to split Bronze into one task and Silver/Gold into another task the arguments would look like
the examples below.
- Bronze Only Task -
["dbfs:/path/to/config.csv", "4", "Bronze"] - Silver/Gold Task -
["dbfs:/path/to/config.csv", "4", "Silver,Gold"]
- Bronze Only Task -
- Running all the pipelines together will maximize cluster utilization but there are often reasons to split the pipelines thus we’ve added support.
- If you wanted to split Bronze into one task and Silver/Gold into another task the arguments would look like
the examples below.