Pipeline Validation
Overview
Overwatch provides a special pipeline validation module to perform a number of data quality, data completeness, and referential integrity checks on its output. Pipeline validation may run as frequently as the regularly scheduled, automated Overwatch ETL pipeline runs/deployments or manually as a notebook command. It is used by the Overwatch maintainers to guard against data quality regressions when extending and enhancing Overwatch’s internal logic. Similarly, we are encouraging users to apply this tool to their deployments to provide data quality readouts and to assist with customer issue resolution. This page describes its functionality in detail and how to add a pipeline validation step to an Overwatch workflow.
Logical Flow
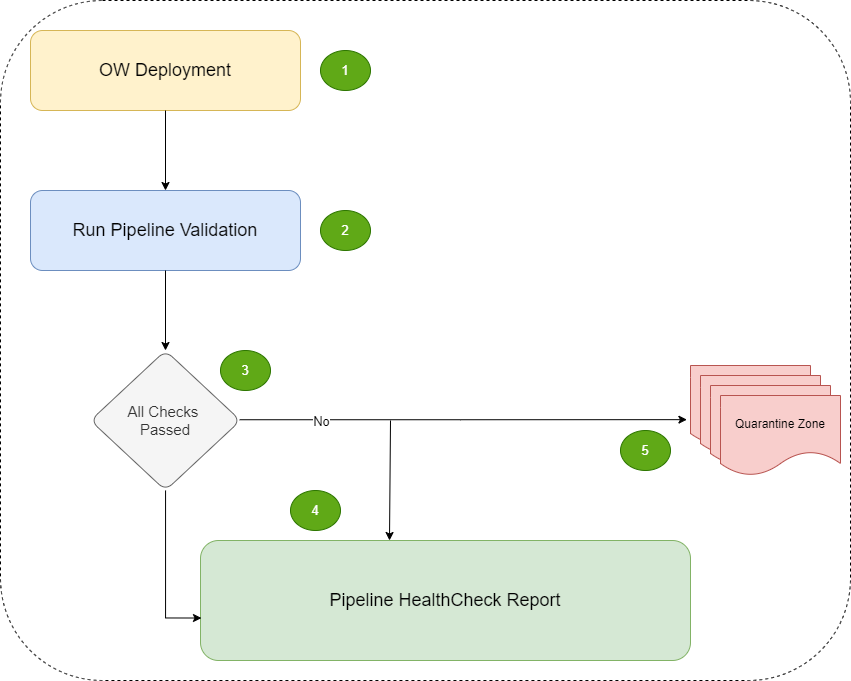
Here is the high-level logical flow of the Pipeline Validation module:
-
All workflow tasks of an Overwatch pipeline deployment run to completion.
-
An additional workflow task executes the Pipeline Validation module.
-
A health check report for the pipeline is generated with a record for each check that was performed.
-
Upon failure of any validation check, a snapshot of records that caused the failure are moved to a quarantine zone for debugging purpose.
The pipeline validation module is designed to perform its checks on records that it has not already validated in a previous run to avoid redundant validation checks. Given that validation has completed normally following a previous Overwatch pipeline deployment, only new records produced in one or more subsequent deployments are subject to validation.
Validation reports
Running the validation module produces two types of records:
- Health check reports
- Quarantine reports
Heath check reports
Each validation run produces one or more records in the pipeline health check report for each health check rule according to the number of Overwatch ETL tables associated with that rule. Each record contains a reference to the corresponding Overwatch ETL run and its snapshot timestamp.
The schema of a health check report is as follows:
| Column Name | Type | Description | Example Value |
|---|---|---|---|
| healthcheck_id | uuid | Unique ID for this Healthcheck_Report record | 272b83eb-1362-456a-8dae-26c3083181ac |
| etl_database | string | Overwatch ETL database name | ow_etl_azure_0721 |
| table_name | string | Overwatch ETL table name | clusterstatefact_gold |
| healthcheck_rule | string | Description of health check rule applied to the table data | Driver_Node_Type_ID Should Not be NULL |
| rule_type | string | Type of validation rule (See enumerated values below.) | Pipeline_Report_Validation |
| healthcheckMsg | string | health check status of the table data for this health check rule | health check Failed: got 63 driver_node_type_ids which are null |
| overwatch_runID | string | Overwatch run ID of the corresponding snapshot | b8985023d6ae40fa88bb6daef7f46725 |
| snap_ts | long | Snapshot timestamp in yyyy-mm-dd hh:mm:ss format | 2023-09-27 07:43:39 |
| quarantine_id | uuid | Unique ID for Quarantine Report | cd6d7ecc-b72d-4c16-b8ca-01a6df4fba9c |
Quarantine reports
Table rows that do not satisfy the rules configured in the pipeline validation module appear in the quarantine report using this schema:
| Column Name | Type | Description | Example Value |
|---|---|---|---|
| quarantine_id | uuid | Unique ID for this Quarantine_Report record | cd6d7ecc-b72d-4c16-b8ca-01a6df4fba9c |
| etl_database | string | Overwatch ETL database name | ow_etl_azure_0721 |
| table_name | string | Overwatch table name | clusterstatefact_gold |
| healthcheck_rule_failed | string | Description of health check rule causing the row having keys to be quarantined | Driver_Node_Type_ID Should Not be NULL |
| rule_type | string | Type of validation rule (See enumerated values below.) | Pipeline_Report_Validation |
| healthcheck_type | string | Denote the failure type of the health check rule. | Warning or Failure |
| keys | string | JSON of primary (possibly compound) key value | {“cluster_id”:“0831-200003-6bhv8y0u”,“state”:“TERMINATING”,“unixTimeMS_state_start”:1693514245329} |
| snap_ts | long | Snapshot timestamp in yyyy-mm-dd hh:mm:ss format | 2023-09-27 07:43:39 |
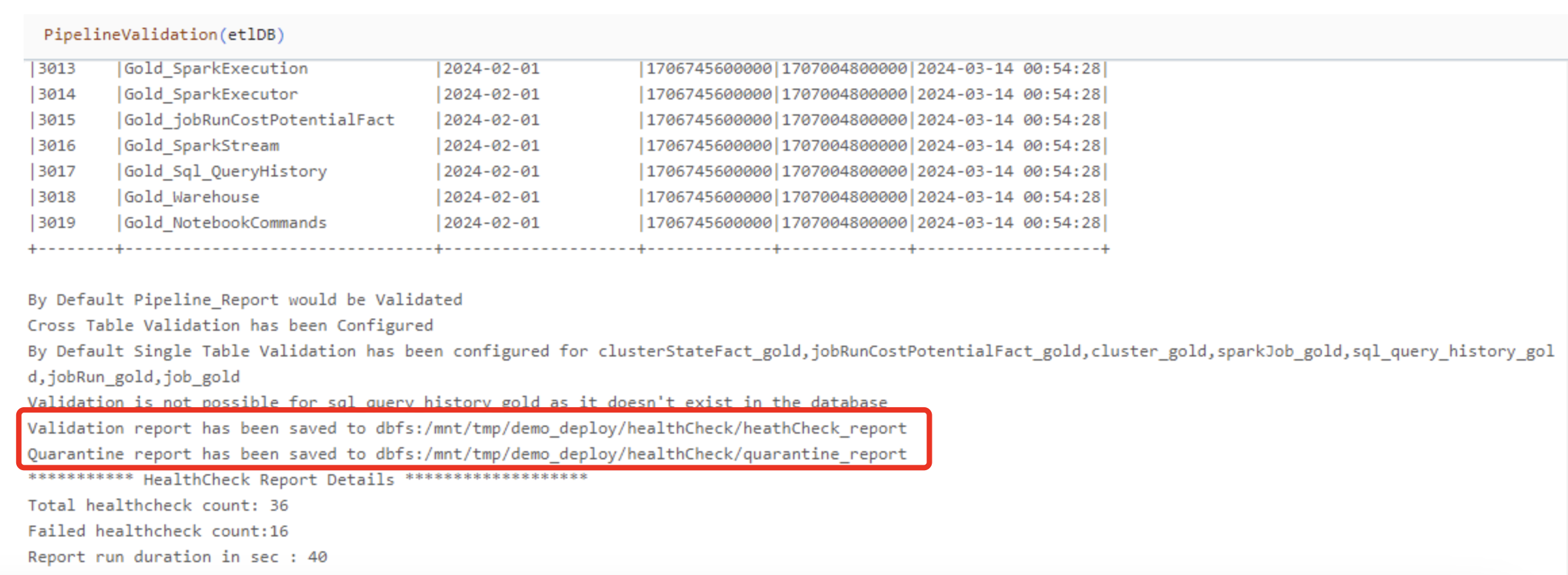
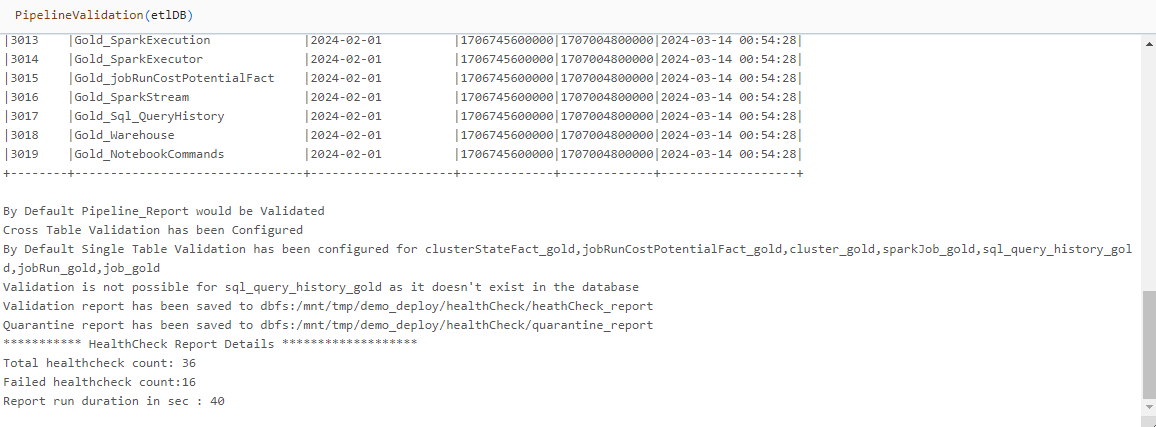
These reports are persisted to cloud storage as Delta tables. The output of the validation module reveals the location of these tables as shown withing the stack trace in the following screenshot:
Rule types
The rule_type field mentioned in the Heath Check Report schema above currently has three possible values:
'Pipeline_Report_Validation''Single_Table_Validation''Cross_Table_Validation'
By default the validation module applies health check rules of all three rule types. Rules may applied selectively by providing parameters to the module. More on this will be discussed in a later section.
The following sections describe each of these rule types in detail.
Pipeline report validation
This rule type validates records in the Overwatch pipeline_report table.
This rule type has two healthcheck_rule values:
'Check If Any Module is EMPTY''Check If Any Module is FAILED'
Single-table validation
The healthCheck_rules with this rule_type would be applied to single table. Basically it will check data quality of single tables. Currently, below tables are in scope of this rule type:
- clusterstatefact_gold
- jobruncostpotentialfact_gold
- cluster_gold
- sparkjob_gold
- sql_query_history_gold
- jobrun_gold
- job_gold
Different health check rules are defined for the following tables:
clusterstatefact_gold
- cluster_id should not be null
- driver_node_type_id should not be null
- node_type_id should not be null for multi-node cluster
- dbu_rate should be greater than zero for runtime engine is standard or photon
- total_cost should be greater than zero for Databricks billable
- check whether any single cluster state is running for multiple days
jobruncostpotentialfact_gold
- job_id should not be null
- driver_node_type_id should not be null
- job_run_cluster_util_value should not be more than one
- check whether any job is running for multiple days
cluster_gold
- cluster_id should not be null
- driver_node_type_id should not be null
- node_type_id should not be null for multi-node cluster
- cluster_type should be between serverless, SQL analytics, single-node, standard, high-concurrency
sparkjob_gold
- cluster_id should not be null
- job_id should not be null
- db_id_in_job should not be null when db_job_id is not null
sql_query_history_gold
- warehouse_id should not be null
- query_id should not be null
jobrun_gold
- job_id should not be null
- run_id should not be null
- job_run_id should not be null
- task_run_id should not be null
- cluster_id should not be null
job_gold
- job_id should not be null
- action should be one of snapimpute, create, reset, update, delete, resetJobAcl, or changeJobAcl
Cross-table validation
The health check rules for this rule type are applied to two or more tables. This rule type is used to validate data consistency across tables.
This rule type has the following healthcheck_rule values:
- job_id present in jobrun_gold but not in jobruncostpotentialfact_gold
- job_id present in jobruncostpotentialfact_gold but not in jobrun_gold
- cluster_id present in jobrun_gold but not in jobruncostpotentialfact_gold
- cluster_id present in jobruncostpotentialfact_gold but not in jobrun_gold
- notebook_id present in notebook_gold but not in notebookcommands_gold
- notebook_id present in notebookcommands_gold but not in notebook_gold
- cluster_id present in clusterstatefact_gold but not in jobruncostpotentialfact_gold
- cluster_id present in jobruncostpotentialfact_gold but not in clusterstatefact_gold
- cluster_id present in cluster_gold but not in clusterstatefact_gold
- cluster_id present in clusterstatefact_gold but not in cluster_gold
Pipeline Validation Workflow Integration
Currently the pipeline validation module runs in a Databricks notebook
cell. Therefore workflow integration requires adding a notebook task.
Running as JAR task as the regular pipeline deployment does is planned
as a future enhancement. Its execution starts with default behavior
by calling the PipelineValidation() method with the name of the
target ETL database as its sole mandatory parameter:
PipelineValidation( "overwatch_etl")
The module’s behavior can be altered by providing one or more of the following optional parameters:
| Parameter | Type | Optional | Default Value | Description |
|---|---|---|---|---|
| etlDB | string | No | NA | Overwatch ETL database name to validate |
| allRun | boolean | Yes | true | Validate all runs in pipeline_report? |
| table | array | Yes | [] | Subset of default tables to validate. |
| crossTableValidation | Boolean | Yes | true | Perform Cross Table Validation? |
Below are example pipeline validation runs, first with default behavior followed by demonstrations of the optional paramaters.
Default behavior
val etlDB = "overwatch_etl"
PipelineValidation( etlDB)
 Here we can see from the above screenshot that:
Here we can see from the above screenshot that:
-
Performs validation on all runs present in the
pipeline_reporttable. -
Performs single-table validation for all pre-defined target tables.
-
Performs cross-table validation for all pre-defined table pairs.
Restrict validation to unvalidated runs
PipelineValidation( etlDB, allRun = false)
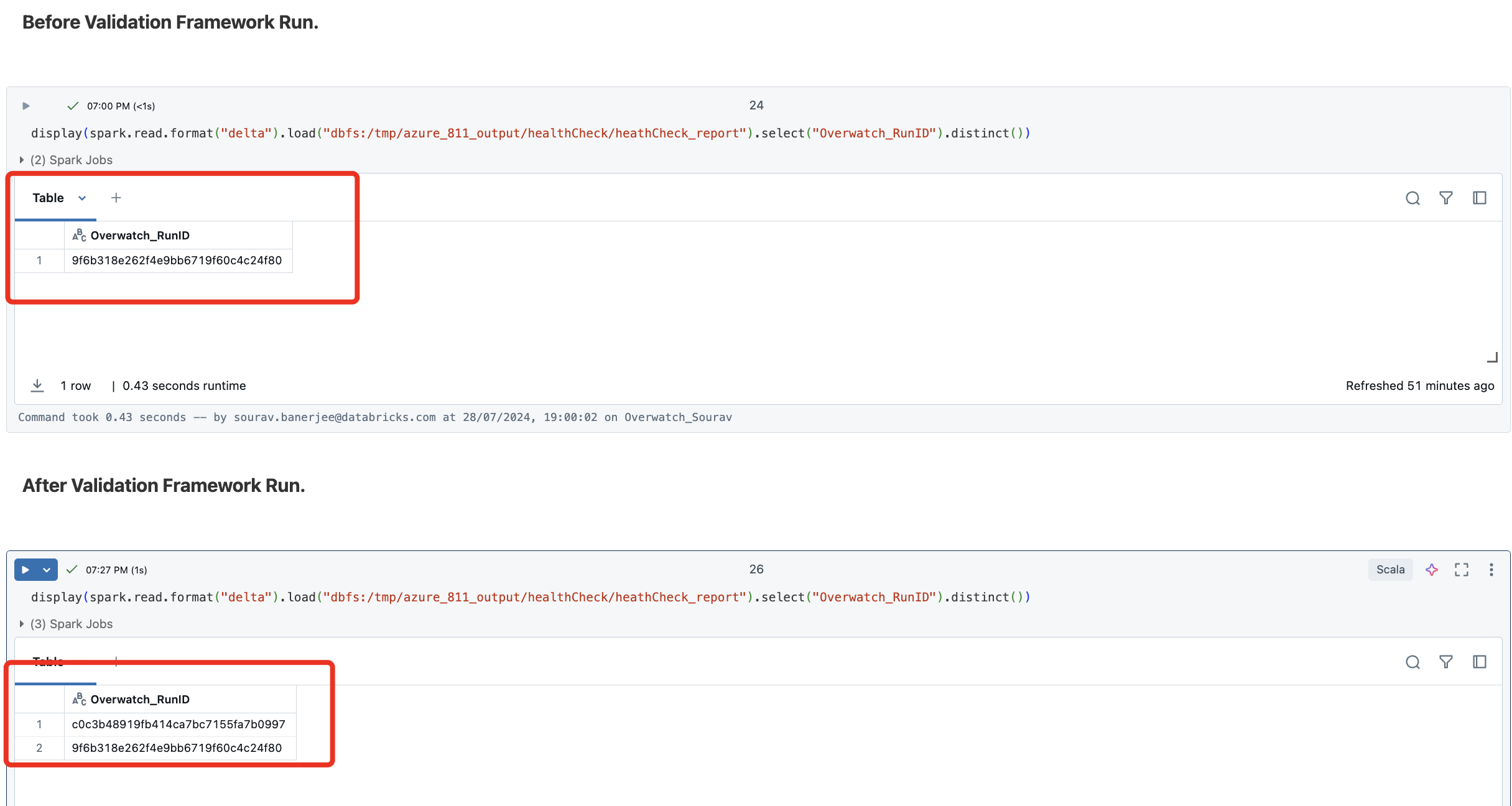
-
Performs validation only on runs in the
pipeline_reporttable not previously validated. -
Performs single-table validation for all pre-defined target tables.
-
Performs cross-table validation for all pre-defined table pairs.
Restrict validation to a subset of tables
PipelineValidation(
etlDB,
table = Array(
"clusterstatefact_gold",
"jobruncostpotentialfact_gold"))
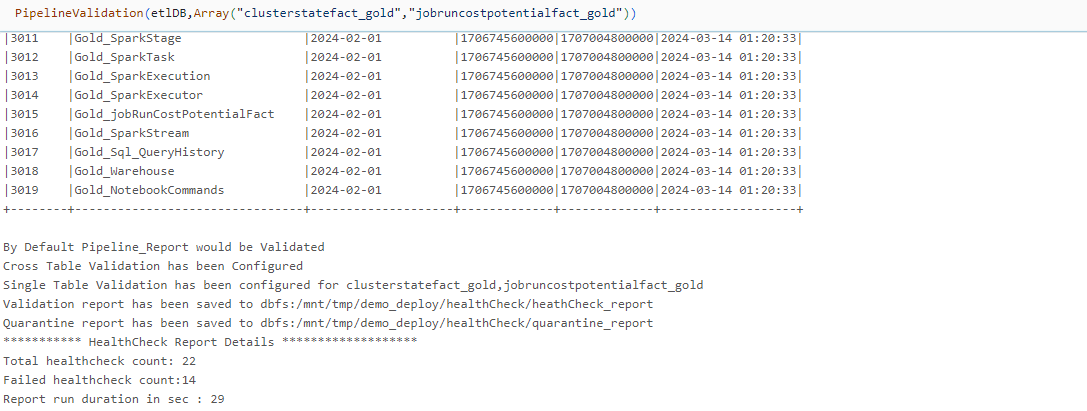
-
Performs validation on all runs present in the
pipeline_reporttable. -
Performs single-table validation for the specified subset of target tables.
-
Performs cross-table validation.
Disable cross-table validation
PipelineValidation(
etlDB,
table = Array(
"clusterstatefact_gold",
"jobruncostpotentialfact_gold"),
crossTableValidation = false)
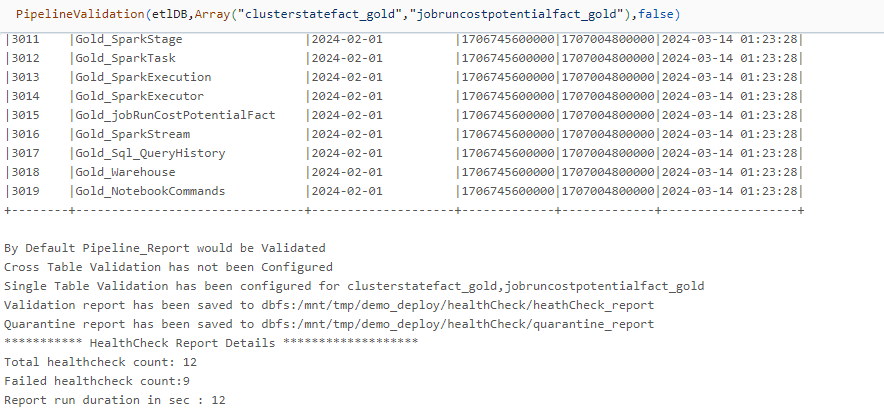
-
Performs validation on all runs present in the
pipeline_reporttable. -
Performs single-table validation for the specified subset of target tables.
-
Disables cross-table validation.