Modules
Modules
Modules are the method by which Overwatch is segmented; currently, the modules available include:
The default is to use all modules so if none are specified in the configuration, all modules will be enabled. Currently, under normal, daily operations, there no significant cost to any of these modules. It’s likely best to leave them all turned on unless there’s a specific reason not to.
The very first run can be an exception to “no significant cost”. The historical load of 60+ days can take some time to load depending on the size of the workspace and quantity of historical data to be loaded. See Advanced Topics for more details on optimizing the first run.
These modules control which parts of Overwatch are run when the Overwatch job executes. Many of the modules are dependent on other modules (details below). At present, the audit module is always required as it contains most of the metadata to enable the other overwatch modules.
A full list of which tables are ultimately made available by which module can be found in the Data Definitions section.
Upcoming modules include (in no particular order):
- security
- costs
- data-profiler
- recommendations
- real-time
Hard dates have not been set for these but will be delivered as soon as available. Please star the GitHub repo for release updates.
Audit
Requires: None
Enables: All
Audit is the base, fundamental module from which the other modules build upon. This module is required.
For details on how to configure audit logging please refer to the Databricks docs online and/or the environment setup details for your cloud provider.
The source data is landed in the bronze layer table audit_log_bronze. The schema is ultimately inferred but a minimum
base, required schema is defined to ensure requisite data fields are present. Additional data will land in the audit
table as events occur in the workspace and the schema will evolve as necessary to accommodate the new events.
Events for entities such as clusters and jobs are only recorded when a user creates, edits, deletes the entity. As such, if the audit logging begins on Day 10, but the cluster and/or job were created and last edited before Day 10 it’s likely that much or all of the metadata will be missing for the particular job. This is the reason the entity snapshots are so important. The entity snapshots significantly close this gap for existing workspace entities but there may still be missing data in the early days of Overwatch runs. It’s important to ensure Overwatch runs periodically to reduce/eliminate data gaps.
Clusters
Requires: Audit
Enables: All
Gold Entities: Cluster
The clusters module is pretty low-level. The cluster_id field throughout the layers is the primary method through which users can tie spark-side data to databricks-side data. Additionally, cluster_ids are required to calculated costs for clusters and for jobs since they are the basis for the compute. Without this metadata, the value of Overwatch is signifcantly stifled.
In addition to cluster_id, the clusters module also provides the cluster logging path of all clusters identified by Overwatch. From the logging path the SparkEvents (event log) locations can be extrapolated and consumed; without the clusters module, the sparkEvents cannot function.
ClusterEvents
Requires: Clusters
Enables: ClusterStateFact|JobRunCostPotentialFact
Gold Entities: ClusterStateFact
Cluster Events are just what they sound like, events that occur on a cluster which usually result in a cluster state
change. All of these events can be seen in the UI if you navigate to a spcific cluster and click on eEvent Log.
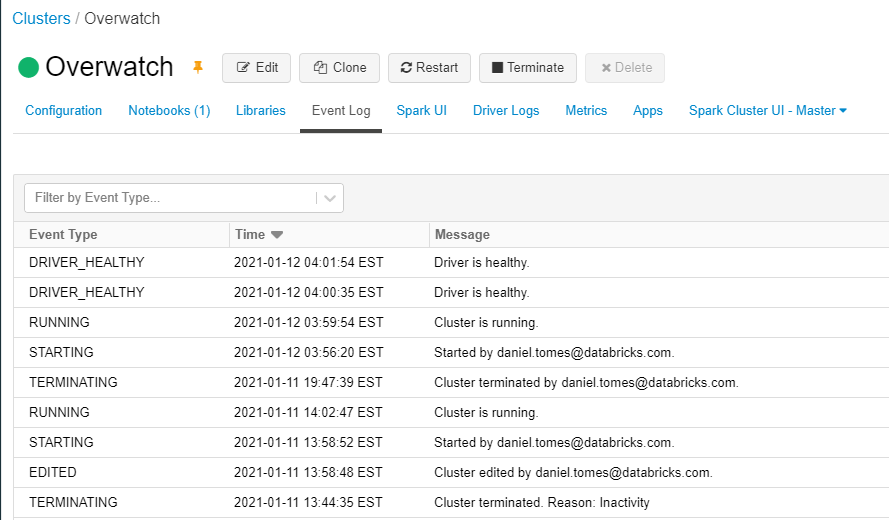 This data acquisition is driven from a paginated API calls and can only go back 30 days. Note that a large, autoscaling
cluster with many users is likely to have MANY EVENTS. The api can return 500 results (max) per call and the
process for getting all the results are via pagination. This is particularly relevant on the first run. The API
can only go so fast so the first run will take quite a while for larger workspaces with a lot of cluster events,
plan your initial load cluster size appropriately.
This data acquisition is driven from a paginated API calls and can only go back 30 days. Note that a large, autoscaling
cluster with many users is likely to have MANY EVENTS. The api can return 500 results (max) per call and the
process for getting all the results are via pagination. This is particularly relevant on the first run. The API
can only go so fast so the first run will take quite a while for larger workspaces with a lot of cluster events,
plan your initial load cluster size appropriately.
A lot of work has been done to optimize this speed and across nodes in your cluster but remember that there workspace API limits and Overwatch will not exceed them but can put significant pressure on them so it’s best to not do a full scale first-run of clusterEvents during times when other resources are heavily utilizing api calls.
Pools
Requires: Audit
Gold Entities: InstancePool Simple module that offers observability to configuration changes (not state) of an instance pool. Databricks does not yet publish the state change data for instance pools; thus Overwatch cannot deliver metrics for how long a node was used, how long it was idle, when it became idle, when it was terminated, etc. When Databricks makes this data available, Overwatch will add this to the data model in a release shortly thereafter.
Jobs
Requires: Audit|Clusters|ClusterEvents Enables: JobRunCostPotentialFact
Gold Entities: Job|JobRun|JobRunCostPotentialFact
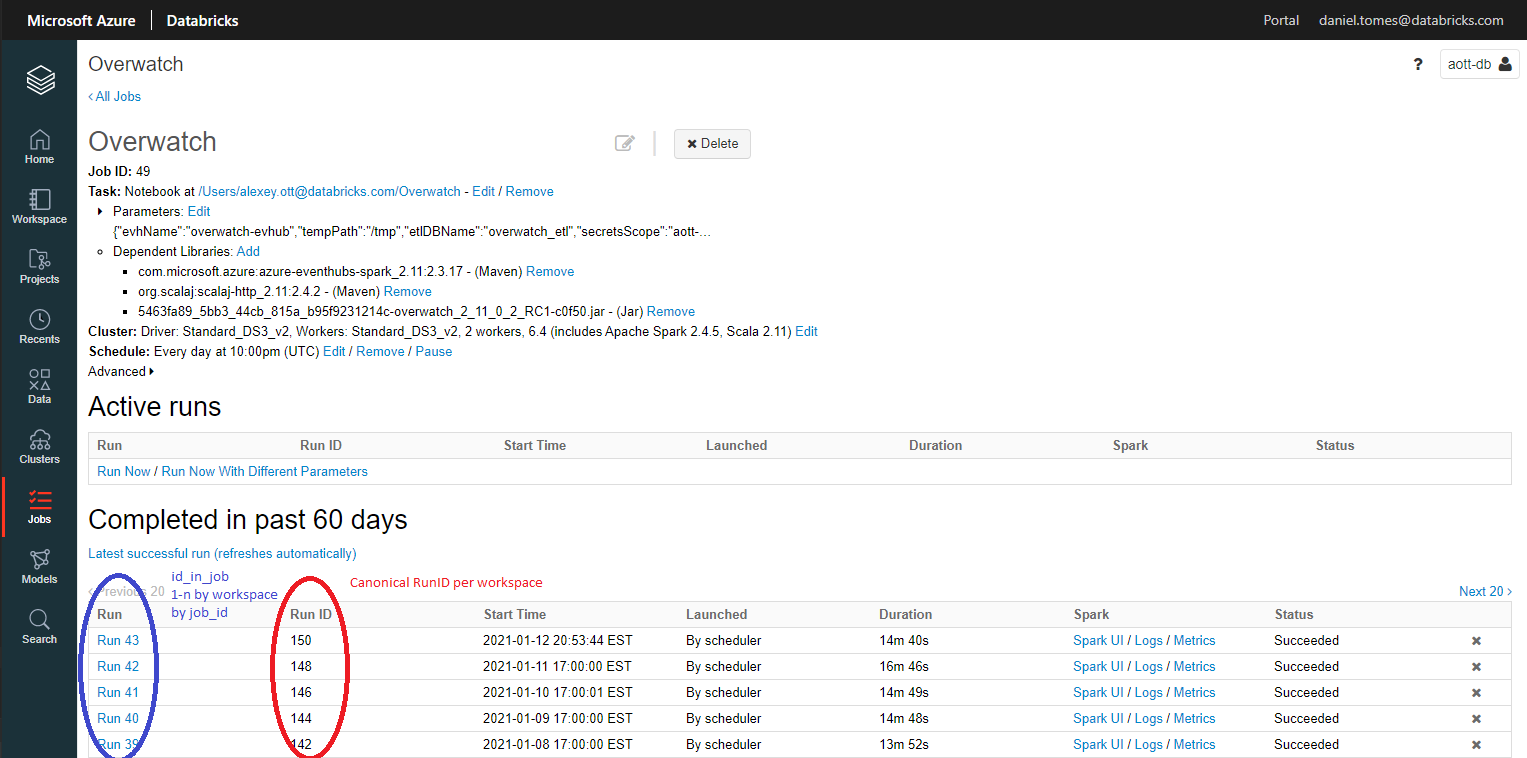
Overwatch curates all the job definitions through time, capturing as much metadata about these job definitions as
possible. In addition to the job definition metadata, Overwatch also captures each run and ties the run to a cluster_id
and a run_id. There are two types of *run_id" in Databricks, a global, canonical run_id and an id_in_job which
starts at 1 for each job and increments by 1 for each of that job’s runs. Remember that the job definition can change
between runs including important aspects such as the cluster definition, name, schedule, notebook, jar, etc. A job_id
can be completely different from day to day and combining the point-in-time definition of a job along with the
point-in-time cluster definition and run-times can be very powerful, and very hard to curate without Overwatch.
Accounts
Requires: Audit
Gold Entities: AccountModificationFact|AccountLoginFact
The accounts module is very simple and is meant to assist the IT Admin team in keeping track of users. The Accounts module includes some very useful auditing information as well as enables authorized users to tie user_ids back to user_emails. The Accounts module includes two key entities:
- userLoginFact - identifies a user login, method, sourceIPAddress, and any authorizing groups.
- user - Slow changing dimension of a user entity through time including create, edit, delete. The user table also records the source IP address of any add/edit/delete action performed on a user.
These tables (which are actually views) have been purposely maintained in the ETL database not the consumer database. This is because these are considerably sensitive tables and it’s best to simplify the security around these tables. If desired, views, can be created manually in the consumer database to publish these more broadly.
Overwatch should not be used as single source of truth for any audit requirements.
Notebooks
Requires: Audit
Gold Entities: Notebook
Currently a very simple module that just enables the materialization of notebooks as slow changing dimensions.
DBSQL (Preview)
Preview as of 0.7.0 Requires: Audit
Gold Entities: sqlQueryHistory
Additional DBSQL entities will be coming shortly to enable users to join with warehouses and other assets. As of 0.7.0 this is a preview; we’re looking for feedback, so please submit a new git issue if you identify an issue with the data.
SparkEvents
Requires: Clusters
Gold Entities: SparkExecution|SparkJob|SparkStage|SparkTask|SparkExecutor|SparkStream|SparkJDBC
Databricks captures all “SparkEvents” captured by Open Source Spark (OSS) AND some additional events that are proprietary to Databricks. These events are captured and persisted in event log files when cluster logging is enabled. Below are screenshots of the cluster logs configuration and the resulting event log parent directories.
When the SparkEvents module is enabled and a cluster is configured to capture cluster logs, Overwatch will dive into the cluster logging folder and find the event logs that were created since the previous run. This is why the clusters module is required for the SparkEvents module to function. Overwatch will remember which files it’s processed and only process new files captured within the relevant timeframe.
It’s best practice to configure cluster logs to be delivered to a location with time-to-live (TTL) properties set up (sometimes referred to as lifecycle properties). This allows for files to age out and not continue to eat up space. Files can be configured to be deleted or moved to cold storage after some defined timeframe. The raw files are very inefficient to store long-term and once the data has been captured by Overwatch, it’s stored in an efficient way; therefore, there’s little to no reason to keep the files in warm/hot storage for greater than some a few weeks. More information can be found on this topic in the Advanced Topics section.
The eventlog schema is very complex and implicit. Each event is categorized by “Event” and the columns populated are contingent upon the event. This method causes chaos when trying to analyze the logs manually and yet another reason Overwatch was created. The schema ultimately contains every single piece of information that can be found in the Spark UI and it can be accessed and analyzed programmatically. The most common data points have been curated and organized for consumption. The Overwatch team has grand plans to dig deeper and curate additional sources as they are created by Spark and Databricks.
The cluster_id is the primary method through which Spark data can be tied to Databricks metadata such as jobs, costs, users, core count, pools, workspaces, etc. Once the Spark operation data is combined with a cluster it’s relatively easy to tie it back to any dimension.
Custom SparkEvents published through Spark Streaming and custom eventListeners can also be identified here for
more advanced users. The custom events will not be curated for you but they can be found in the spark_events_bronze
etl table
SparkEvents Organization
Tying the SparkEvents together and using only the data necessary is the key to success when working in these large datasets. It’s best to identify the highest level that has the measure you need and work your way up to the ClusterID and over to Databricks Environment metadata. The image below attempts to depict the relationships visually to simplify the interactions. A few bullet points have been provided below to help you digest the visual. Additionally, if you’re familiar with the SparkUI, the hierarchy and encapsulations are identical.
Additional clarification of the Spark Hierachy can be found on this Spark+AI Summit YT Video
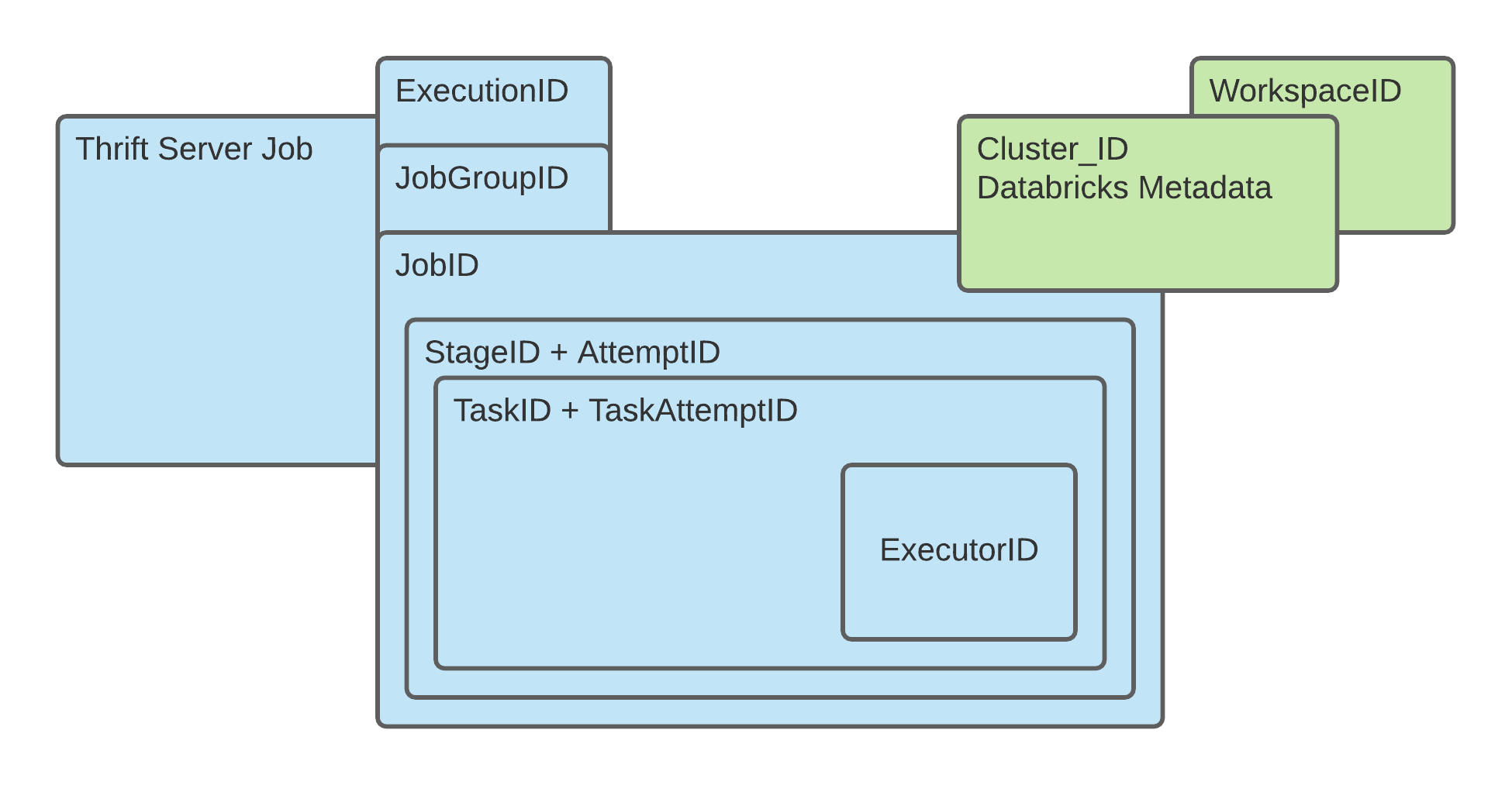
- A SparkExecutionID is only present when the spark job[s] are spawned from a SparkSQL command. RDD and Delta
metadata commands are not encapsulated by an ExecutionID; as such, JobGroupIDs and JobIDs can exist without the
presence of an ExecutionID.
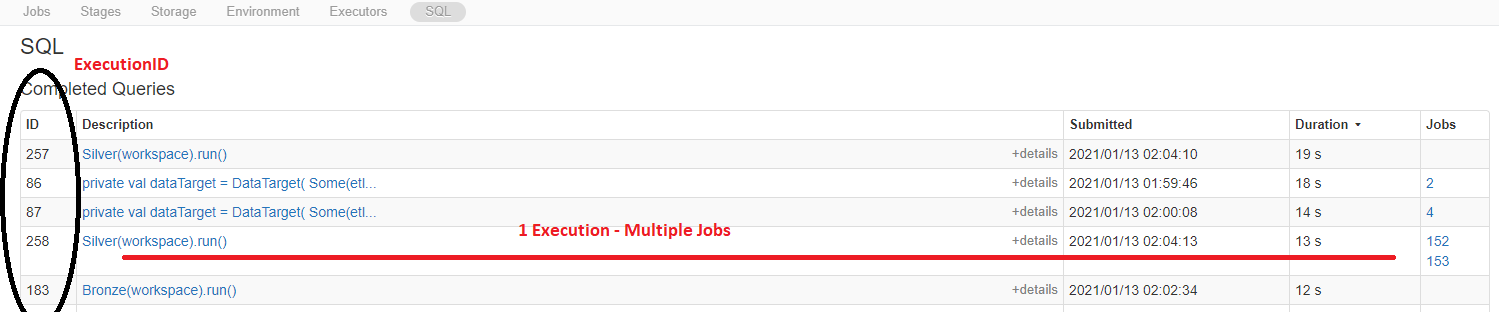
- A JobGroupID is present anytime a single spark DAG requires multiple Spark Jobs to complete the action. A
JobGroupID has 0:m ExecutionIDs and 1:m JobIDs.
- Another very important note about the JobGroupID is that if the jobGroupID was launched from a Databricks Job,
the Databricks JobID and Id_in_Job (i.e. Run 43) are captured as a portion of the jobGroupID. This means that
any Spark Job can be directly tied back to a specific Databricks Job Run.
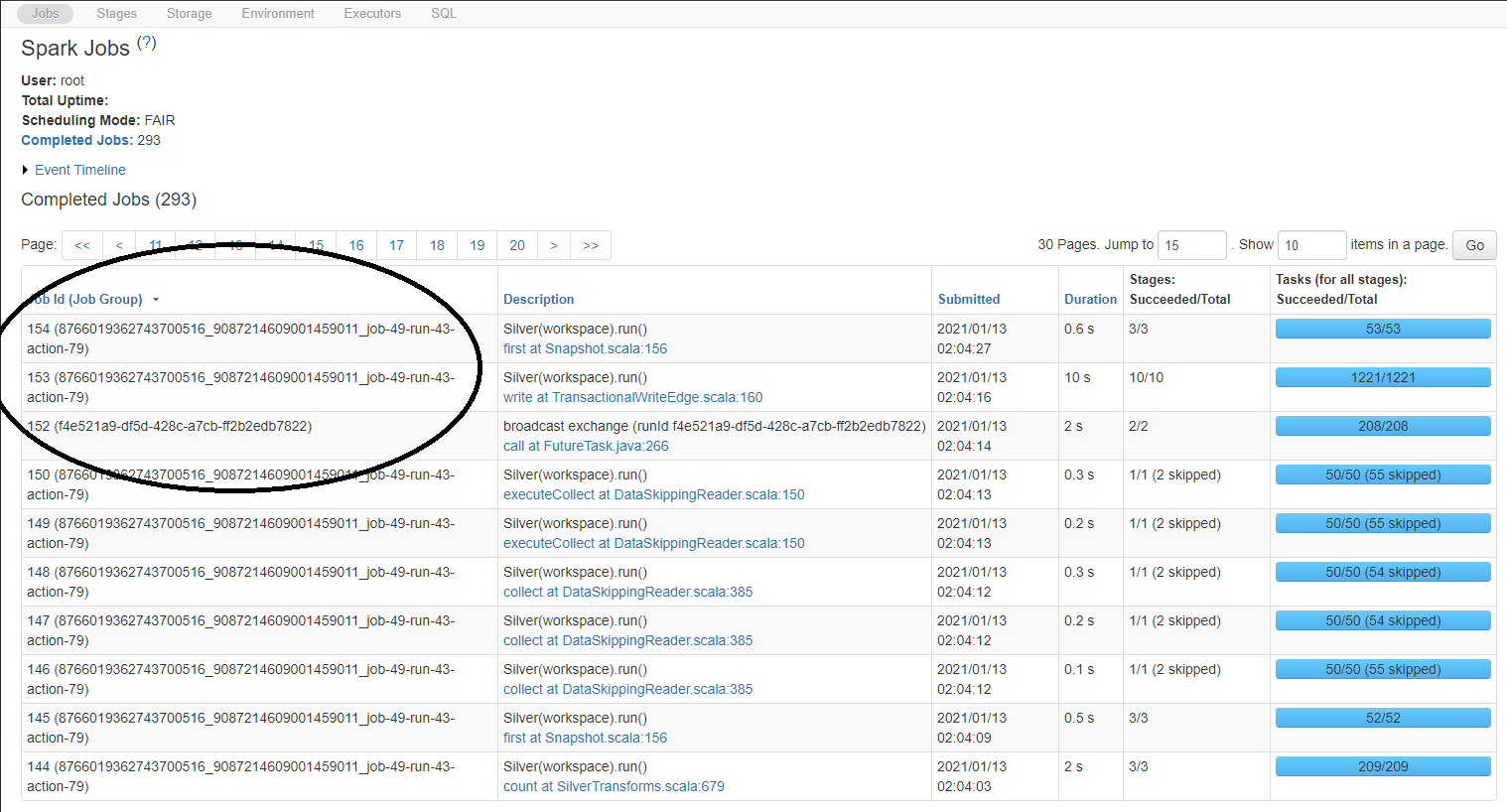
- Another very important note about the JobGroupID is that if the jobGroupID was launched from a Databricks Job,
the Databricks JobID and Id_in_Job (i.e. Run 43) are captured as a portion of the jobGroupID. This means that
any Spark Job can be directly tied back to a specific Databricks Job Run.
- A SparkJobID IS required for every spark job and has 1:m Spark StageIDs. The SparkJobID has a 0:1 to a Spark
JobGroupID and a 1:m to StageID. SparkJobIDs are also special because they provide the Databricks metadata such as
user and cluster_id. Spark_events_bronze also has many additional Databricks properties published in certain circumstances.
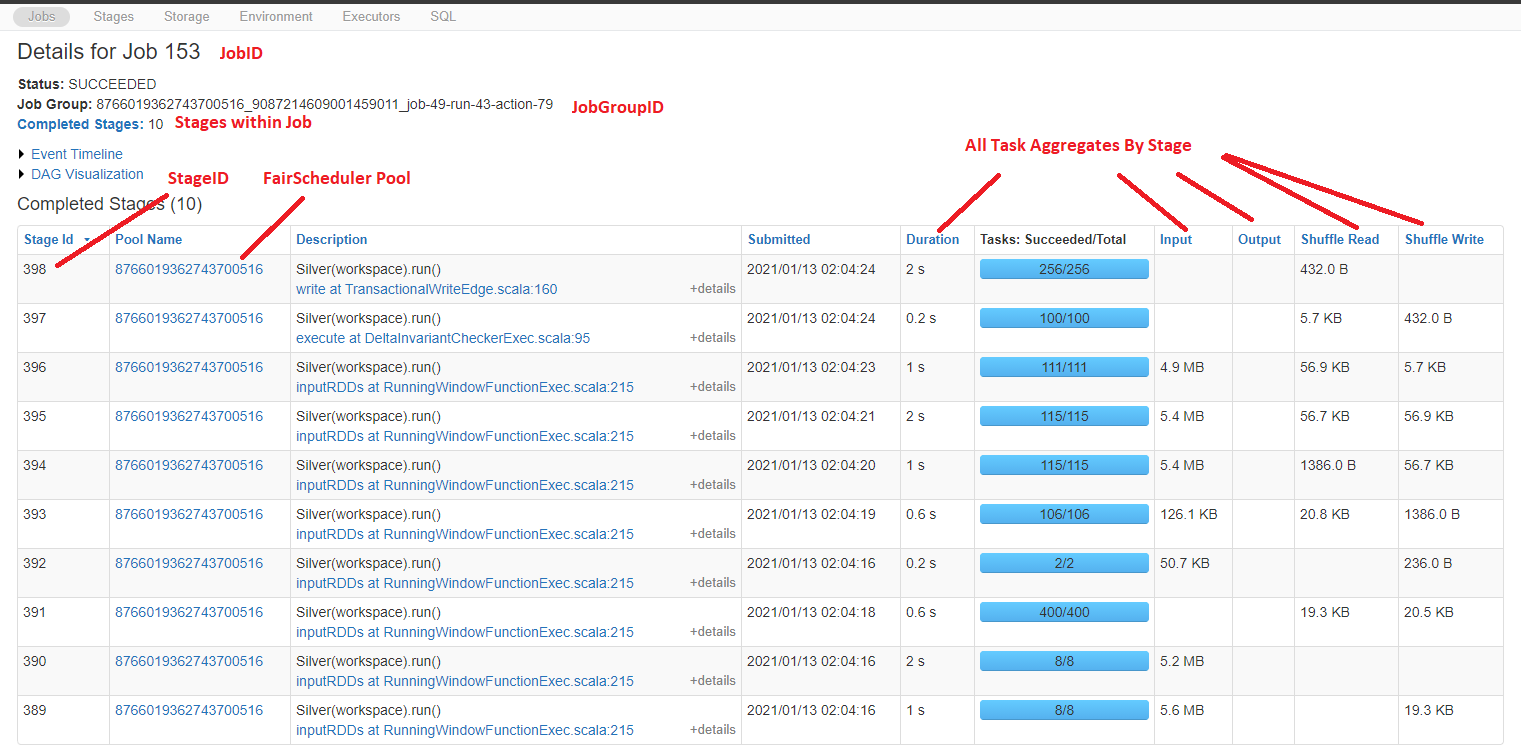
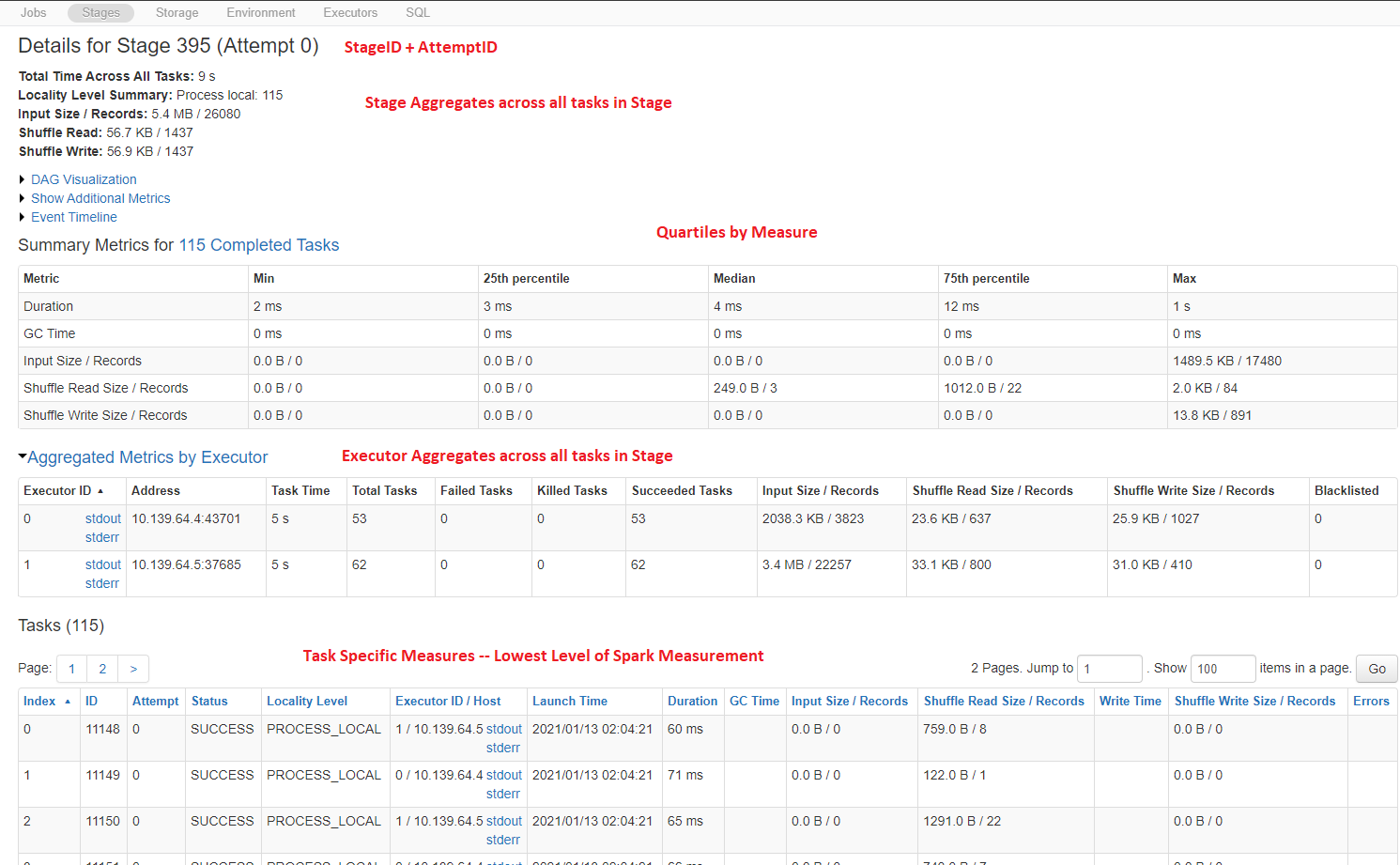
- A SparkStageID is required for all spark jobs and has a 1:1 relationship to JobID and a 1:m to TaskID.
- A SparkTaskID is the lowest level of a spark job, is the unit of work that is executed on a specific machine, and contains all the execution compute statistics for the tasks just as in the SparkUI.
- Every task much execute on one and only one SparkExecutorID. a TaskID has a 1:1 relationship to ExecutorID event
though a task can be retried because a unique Task is also identified by the AttemptID; thus, when a task fails on
due to node failure, the task + attempt is marked as failed and a new attempt is executed on another node. The
ExecutorID is the node on which the work was executed.