Advanced Topics
Quick Reference
- Externalize Optimize & Z-Order
- Interacting With Overwatch and its State
- Joining With Slow Changing Dimensions (SCD)
- Optimizing Overwatch
Optimizing Overwatch
Expectation Check Note that Overwatch analyzes nearly all aspects of the Workspace and manages its own pipeline among many other tasks. This results in 1000s of spark job executions and as such, the Overwatch job will take some time to run. For small/medium workspaces, 20-40 minutes should be expected for each run. Larger workspaces can take longer, depending on the size of the cluster, the Overwatch configuration, and the workspace.
The optimization tactics discussed below are aimed at the “large workspace”; however, many can be applied to small / medium workspaces.
Large Workspace is generally defined “large” due to one or more of the following factors
- 250+ clusters created / day – common with external orchestrators such as airflow, when pools are heavily used, and many other reasons
- All clusters logging and 5000+ compute hours / day
Optimization Limitations (Bronze)
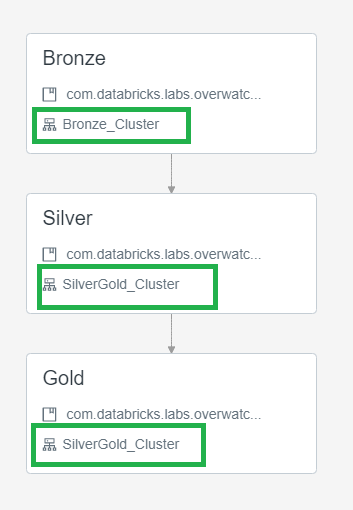
Note that there are two modules that simply cannot be linearly parallelized for reasons beyond the scope of this write-up. These limiting factors are only present in Bronze and thus one optimization is to utilize one cluster spec for bronze and another for silver/gold. To do this, utilize Databricks' multi-task jobs feature to run into three steps and specify two cluster. To split the Overwatch Pipeline into bronze/silver/gold steps refer to the Main Class Setup Configuration
- Bronze - small static (no autoscaling) cluster to trickle load slow modules
- Silver/Gold - slightly larger (autoscaling enabled as needed) - cluster to blaze through the modules as silver and gold modules are nearly linearly scalable. Overwatch developers will continue to strive for linear scalability in silver/gold.
Below is a screenshot illustrating the job definition when broken apart into a multi-task job.
Utilize External Optimize
Externalizing the optimize and z-order functions is critical for reducing daily Overwatch runtimes and increasing efficiency of the optimize and z-order functions. Optimize & z-order are more efficient the larger the dataset and the larger the number of partitions to be optimized. Furthermore, optimize functions are very parallelizable and thus should be run on a larger, autoscaling cluster. Lastly, by externalizing the optimize functions, this task only need be carried out on a single workspace per Overwatch output target (i.e. storage prefix target).
Additional Optimization Considerations
- As of 0.6.1 disable Photon
- Photon will be the focus of optimization in DBR 11.xLTS+
- 0.6.1+ Use DBR 10.4 LTS
- < 0.6.1 Use DBR 9.1 LTS
- This is critical as there are some regressions in 10.4LTS that have been handled in Overwatch 0.6.1 but not in previous versions
- (Azure) Follow recommendations for Event Hub. If using less than 32 partitions, increase this immediately.
- If workspace is VERY large or has 50+ concurrent users, suggest increasing
minEventsPerTriggerin the audit log config. This is defaulted to 10, increase it to 100+. TLDR, this is the minimum number of events in Event Hub allowed before Overwatch will progress past the audit log events module. If the workspace is generating more than 10 events faster than Overwatch can complete the streaming batch then the module may never complete or may get stuck here for some time. - Consider increasing
maxEventsPerTriggerfrom default of 10000 to 50000 to load more audit logs per batch. This will only help if there are 10K+ audit events per day on the workspace.
- If workspace is VERY large or has 50+ concurrent users, suggest increasing
- Ensure direct networking routes are used between storage and compute and that they are in the same region
- Overwatch target can be in separate region for multi-region architectures but sources should be co-located with compute.
Using External Metastores
If you’re using an external metastore for your workspaces, pay close attention to the Database Paths configured in the DataTarget. Notice that the workspaceID has been removed for the external metastore in the db paths. This is because when using internal metastores and creating databases in multiple workspaces you are actually creating different instances of databases with the same name; conversely, when you use an external metastore, the database truly is the same and will already exist in subsequent workspaces. This is why we remove the workspaceID from the path so that the one instance of the database truly only has one path, not one per workspace.
// DEFAULT
private val dataTarget = DataTarget(
Some(etlDB), Some(s"${storagePrefix}/${workspaceID}/${etlDB}.db"), Some(s"${storagePrefix}/global_share"),
Some(consumerDB), Some(s"${storagePrefix}/${workspaceID}/${consumerDB}.db")
)
// EXTERNAL METASTORE
private val dataTarget = DataTarget(
Some(etlDB), Some(s"${storagePrefix}/${etlDB}.db"), Some(s"${storagePrefix}/global_share"),
Some(consumerDB), Some(s"${storagePrefix}/${consumerDB}.db")
)
Externalize Optimize & Z-Order (as of 0.6.0)
The Overwatch pipeline has always included the Optimize & Z-Order functions. By default all targets are set to be optimized once per week which resulted in very different runtimes once per week. As of 0.6.0, this can be removed from the Overwatch Pipeline (i.e. externalized). Reasons to externalize include:
- Lower job runtime variability and/or improve consistency to hit SLAs
- Utilize a more efficient cluster type/size for the optimize job
- Optimize & Zorder are extremely efficient but do heavily depend on local storage; thus Storage Optimized compute
nodes are highly recommended for this type of workload.
- Azure: Standard_L*s series
- AWS: i3.*xLarge
- Optimize & Zorder are extremely efficient but do heavily depend on local storage; thus Storage Optimized compute
nodes are highly recommended for this type of workload.
- Allow a single job to efficiently optimize Overwatch for all workspaces
- Note that the scope of “all workspaces” above is within the scope of a data target. All workspaces that send data to the same dataset can be optimized from a single workspace.
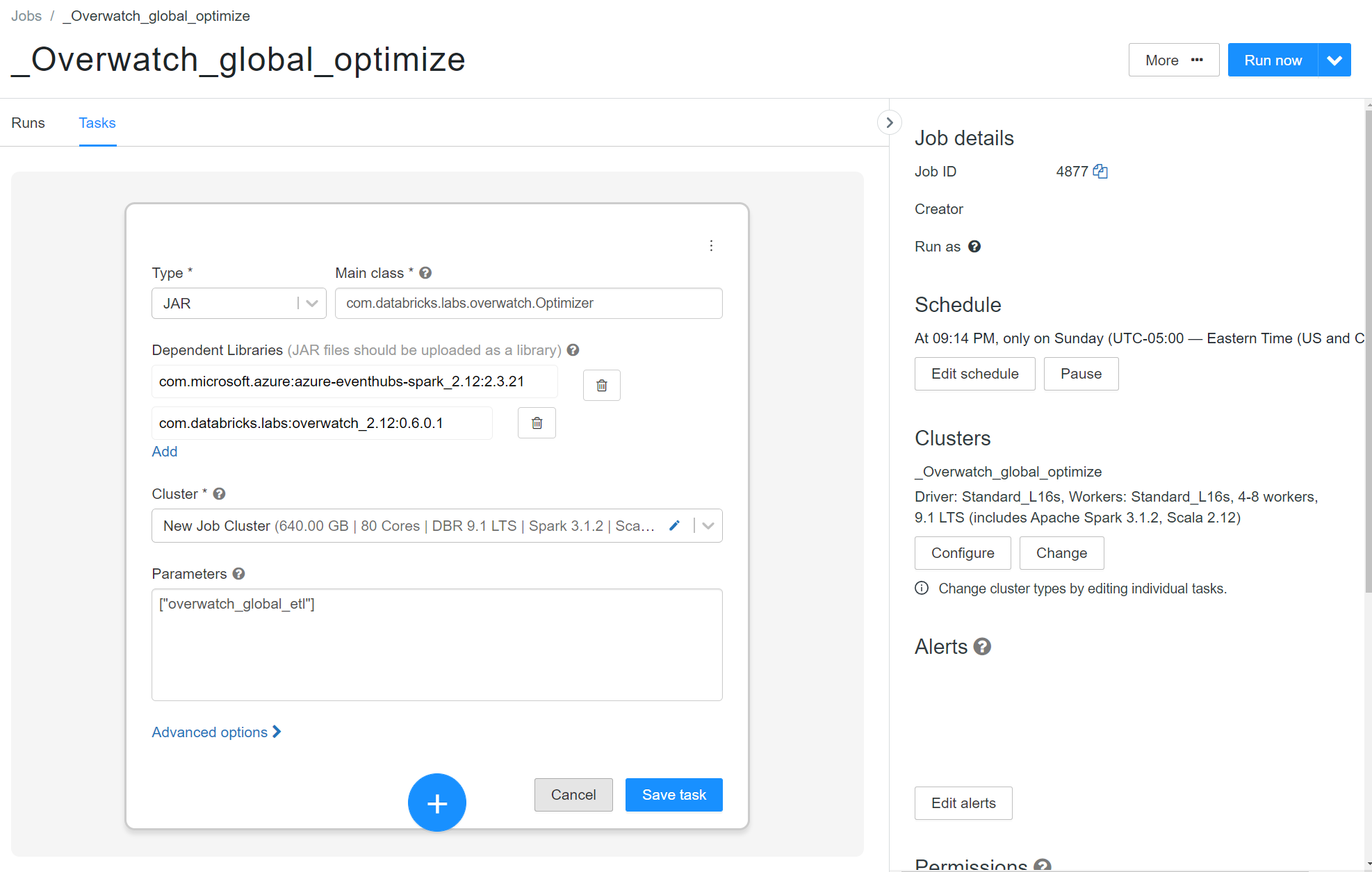
To externalize the optimize and z-order tasks:
- Set externalizeOptimize to true in the runner notebook config (All Workspaces)
- If running as a job don’t forget to update the job parameters with the new escaped JSON config string
- Create a job to execute the optimize on the workspace you wish (One Workspace - One Job)
- Type: JAR
- Main Class:
com.databricks.labs.overwatch.Optimizer - Dependent Libraries:
com.databricks.labs:overwatch_2.12:0.6.0.1 - Parameters:
["<Overwatch_etl_database_name>"] - Cluster Config: Recommended
- DBR Version: 9.1LTS
- Enable Autoscaling Compute with enough nodes to go as fast as you want. 4-8 is a good starting point
- AWS – Enable autoscaling local storage
- Worker Nodes: Storage Optimize
- Driver Node: General Purpose with 16+ cores
- The driver gets very busy on these workloads - recommend 16 - 64 cores depending on the max size of the cluster
Interacting With Overwatch and its State
Use your production notebook (or equivallent) to instantiate your Overatch Configs.
From there use JsonUtils.compactString to get the condensed parameters for your workspace.
NOTE you cannot use the escaped string, it needs to be the compactString.
Below is an example of getting the compact string. You may also refer to the example runner notebook for your cloud provider.
val params = OverwatchParams(...)
print(JsonUtils.objToJson(params).compactString)
Instantiating the Workspace
As Of 0.6.0.4 Utilize Overwatch Helper functions get the workspace object for you. The workspace object returned will be the Overwatch config and state of the current workspace at the time of the last successful run.
As of 0.6.1 this helper function is not expected to work across versions, meaning that if the last run was on 0.6.0.4 and the 0.6.1 JAR is attached, don’t expect this method to work
import com.databricks.labs.overwatch.utils.Helpers
val prodWorkspace = Helpers.getWorkspaceByDatabase("overwatch_etl")
// for olderVersions use the compact String
// import com.databricks.labs.overwatch.pipeline.Initializer
// Get the compactString from the runner notebook you used for your first run example BE SURE your configs are the same as they are in prod
// val workspace = Initializer("""<compact config string>""")
Using the Workspace
Now that you have the workspace you can interact with Overwatch very intuitively.
Exploring the Config
prodWorkspace.getConfig.*
After the last period in the command above, push tab and you will be able to see the entire derived configuratin and it’s state.
Interacting with the Pipeline
When you instantiate a pipeline you can get stateful Dataframes, modules, and their configs such as the timestamp from which a DF will resume, etc.
val bronzePipeline = Bonze(prodWorkspace)
val silverPipeline = Silver(prodWorkspace)
val goldPipeline = Gold(prodWorkspace)
bronzePipeline.*
Instantiating a pipeline gives you access to its public methods. Doing this allows you to navigate the pipeline and its state very naturally
Using Targets
A “target” is essentially an Overwatch-defined table with a ton of helper methods and attributes. The attributes are closed off in 0.5.0 but Issue 164 will expose all reasonably helpful attributes making the target definition even more powerful.
Note that the scala filter method below will be simplified in upcoming release, referenced in Issue 166
val bronzeTargets = bronzePipeline.getAllTargets
val auditLogTarget = bronzeTargets.filter(_.name === "audit_log_bronze") // the name of a target is the name of the etl table
// a workspace level dataframe of the table. It's workspace-level because "global filters" are automatically
// applied by defaults which includes your workspace id, thus this will return the dataframe of the audit logs
// for this workspace
val auditLogWorkspaceDF = auditLogTarget.asDF()
// If you want to get the global dataframe
val auditLogGlobalDF = auditLogTarget.asDF(withGlobalFilters = false)
Joining With Slow Changing Dimensions (SCD)
The nature of time throughout the Overwatch project has resulted in the need to for advanced time-series DataFrame management. As such, a vanilla version of databrickslabs/tempo was implemented for the sole purpose of enabling Scala time-series DataFrames (TSDF). TSDFs enable “asofJoin” and “lookupWhen” functions that also efficiently handle massive skew as is introduced with the partitioning of organization_id and cluster_id. Please refer to the Tempo documentation for deeper info. When Tempo’s implementation for Scala is complete, Overwatch plans to simply reference it as a dependency.
This is discussed here because these functionalities have been made public through Overwatch which means you can easily utilize “lookupWhen” and “asofJoin” when interrogating Overwatch. The details for optimizing skewed windows is beyond the scope of this documentation but please do reference the Tempo documentation for more details.
In the example below, assume you wanted the cluster name at the time of some event in a fact table. Since cluster names can be edited, this name could be different throughout time so what was that value at the time of some event in a driving table.
The function signature for “lookupWhen” is:
def lookupWhen(
rightTSDF: TSDF,
leftPrefix: String = "",
rightPrefix: String = "right_",
maxLookback: Long = Window.unboundedPreceding,
maxLookAhead: Long = Window.currentRow,
tsPartitionVal: Int = 0,
fraction: Double = 0.1
): TSDF = ???
import com.databricks.labs.overwatch.pipeline.TransformFunctions._
val metricDf = Seq(("cluster_id", 10, 1609459200000L)).toDF("partCol", "metric", "timestamp")
val lookupDf = Seq(
("0218-060606-rouge895", "my_clusters_first_name", 1609459220320L),
("0218-060606-rouge895", "my_clusters_new_name", 1609458708728L)
).toDF("cluster_id", "cluster_name", "timestamp")
metricDf.toTSDF("timestamp", "cluster_id")
.lookupWhen(
lookupDf.toTSDF("timestamp", "cluster_id")
)
.df
.show(20, false)
Coming Soon
- Getting through the historical load (first run)
- Overwatch unavoidable bottlenecks
- Job Run Optimizations