Getting Started
How It Works
- Build the Config (json string)
- The notebooks below are designed to simplify this and offer some basic best practices for constructed paths
- Instantiate Overwatch’s workspace object
- Use the workspace object to run the Pipelines (i.e. Bronze/Silver/Gold)
- e.g. - Bronze(workspace).run()
Run Methods
Overwatch is run via one of two methods:
- As a job controlling running a notebook
- As a job running the main class
Below are instructions for both methods. The primary difference is the way by which the configuration is implemented and the choice of which to use is entirely user preference. Overwatch is meant to control itself from soup to nuts meaning it creates its own databases and tables and manages all spark parameters and optimization requirements to operate efficiently. Beyond the config and the job run setup, Overwatch runs best as a black box – enable it and forget about it.
Cluster Requirements
- DBR 10.4LTS as of 0.6.1
- Overwatch will likely run on later versions but is built and tested on 10.4LTS since 0.6.1
- Overwatch < 0.6.1 – DBR 9.1LTS
- Overwatch version 0.6.1+ – DBR 10.4LTS
- Do not use Photon
- Photon optimization will begin with DBR 11.x LTS please wait on photon
- Disable Autoscaling - See Notes On Autoscaling
- External optimize cluster recommendations are different. See External Optimize for more details
- Add the relevant dependencies
Cluster Dependencies
Add the following dependencies to your cluster
- Overwatch Assembly (fat jar):
com.databricks.labs:overwatch_2.12:<latest> - (Azure Only) azure-eventhubs-spark - integration with Azure EventHubs
- Maven Coordinate:
com.microsoft.azure:azure-eventhubs-spark_2.12:2.3.21
- Maven Coordinate:
Cluster Config Recommendations
- Azure
- Node Type (Driver & Worker) - Standard_D16s_v3
- Use n Standard_E*d[s]_v4 for workers for historical loads
- Large / Very Large workspaces may see a significant improvement using Standard_E16d[s]_v4 workers but mileage varies, cost/benefit analysis required
- Node Count - 2
- This may be increased if necessary but note that bronze is not linearly scalable; thus, increasing core count may not improve runtimes. Please see Optimizing Overwatch for more information.
- Node Type (Driver & Worker) - Standard_D16s_v3
- AWS
- Node Type (Driver & Worker) - R5.4xlarge
- Use n i3.*xlarge for workers for historical loads
- Large / Very Large workspaces may see a significant improvement using i3.4xlarge workers but mileage varies, cost/benefit analysis required
- Node Count - 2
- This may be increased if necessary but note that bronze is not linearly scalable; thus, increasing core count may not improve runtimes. Please see Optimizing Overwatch for more information.
- Node Type (Driver & Worker) - R5.4xlarge
Notes On Autoscaling
- Auto-scaling compute – Not Recommended
- Note that autoscaling compute will not be extremely efficient due to some of the compute tails as a result of log file size skew and storage mediums. Additionally, some modules require thousands of API calls (for historical loads) and have to be throttled to protect the workspace.
- Auto-scaling Local Storage – Strongly Recommended for historical loads
- Some of the data sources can grow to be quite large and require very large shuffle stages which requires
sufficient local disk. If you choose not to use auto-scaling storage be sure you provision sufficient local
disk space.
- SSD or NVME (preferred) – It’s strongly recommended to use fast local disks as there can be very large shuffles
- Some of the data sources can grow to be quite large and require very large shuffle stages which requires
sufficient local disk. If you choose not to use auto-scaling storage be sure you provision sufficient local
disk space.
Environment Setup
There are some basic environment configuration steps that need to be enabled to allow Overwatch to do its job.
These activities include things like enabling Audit Logs, setting up security (as desired), etc. The setup activities are slightly different depending on your cloud provider, currently Overwatch can operate on aws and azure. Please reference the page that’s relevant for your deployment.
Estimated Spot Prices
Overwatch doesn’t automatically estimate or calculate spot prices. If spot price estimation is desired, best practice is to review the historical spot prices by node in your region and create a lookup table for referencing node type by historical spot price detail. This will have to be manually discounted from compute costs later.
Initializing the Environment
It’s best to run the first initialize command manually to validate the configuration and ensure the costs are built as desired. This should only be completed one time per target database (often many workspaces to one target database, the targets are then mounted on several workspaces to which they are appended by the Overwatch processes).
In a notebook, run the following commands (customized for your needs of course) to initialize the targets. For additional details on config customization options see configuration.
Jump Start Notebooks
The following notebooks will demonstrate a typical best practice for multi-workspace (and stand-alone) configurations. Simply populate the necessary variables for your environment.
- AZURE (HTML 0.7.0+ / DBC 0.7.0+)
- AWS (HTML 0.7.0+ / DBC 0.7.0+)
- AZURE (HTML 0.6.0+ / DBC 0.6.0+)
- AWS (HTML 0.6.0+ / DBC 0.6.0+)
- AZURE (HTML 0.5.0.4+ / DBC 0.5.0.4+)
- AWS (HTML 0.5.x / DBC 0.5.x)
The code snippet below will initialize the workspace (simple aws example).
private val storagePrefix = "/mnt/global/Overwatch/working/directory"
private val workspaceID = ??? //automatically generated in the runner scripts referenced above
private val dataTarget = DataTarget(
Some(etlDB), Some(s"${storagePrefix}/${workspaceID}/${etlDB}.db"), Some(s"${storagePrefix}/global_share"),
Some(consumerDB), Some(s"${storagePrefix}/${workspaceID}/${consumerDB}.db")
)
private val tokenSecret = TokenSecret(secretsScope, dbPATKey)
private val badRecordsPath = s"${storagePrefix}/${workspaceID}/sparkEventsBadRecords"
private val auditSourcePath = "/path/to/my/workspaces/raw_audit_logs" // INPUT: workspace audit log directory
private val interactiveDBUPrice = 0.56
private val automatedDBUPrice = 0.26
private val customWorkspaceName = workspaceID // customize this to a custom name if custom workspace_name is desired
val params = OverwatchParams(
auditLogConfig = AuditLogConfig(rawAuditPath = Some(auditSourcePath)),
dataTarget = Some(dataTarget),
tokenSecret = Some(tokenSecret),
badRecordsPath = Some(badRecordsPath),
overwatchScope = Some(scopes),
maxDaysToLoad = maxDaysToLoad,
databricksContractPrices = DatabricksContractPrices(interactiveDBUPrice, automatedDBUPrice),
primordialDateString = Some(primordialDateString),
workspace_name = Some(customWorkspaceName), // as of 0.6.0
externalizeOptimize = false // as of 0.6.0
)
// args are the full json config to be used for the Overwatch workspace deployment
val args = JsonUtils.objToJson(params).compactString
// the workspace object contains everything Overwatch needs to build, run, maintain its pipelines
val workspace = Initializer(args) // 0.5.x+
If this is the first run and you’d like to customize compute costs to mirror your region / contract price, be sure to run the following to initialize the pipeline which will in turn create some costing tables, which you can customize according to your needs. This is only necessary for first-time init with custom costs. More information below in the Configuring Custom Costs section.
Bronze(workspace)
This is also a great time to materialize the JSON configs for use in the Databricks job the main class (not notebook) is to be used to execute the job.
val escapedConfigString = JsonUtils.objToJson(params).escapedString // used for job runs using main class
val compactConfigString = JsonUtils.objToJson(params).compactString // used to instantiate workspace in a notebook
val prettyConfigString = JsonUtils.objToJson(params).prettyString // human-readable json config
The target database[s] (defined in the dataTarget variable above) should now be visible from the data tab in Databricks. Additionally, the ETL database should contain the custom costing tables, instanceDetails and dbuCostDetails. This is a good time to customize compute prices if you so desire; after first init but before first pipeline run.
Executing The Pipeline
Don’t load years worth of data on your first attempt. There are very simple workspace cleanup scripts in the docs to allow you to quickly start fresh. Best practice is to load the latest 5 or so days (i.e. set primordial date to today minus 5) and let the entire pipeline run, review the pipReport and validate everything. If all looks good, now you can begin your historical loading journey. NOTE cluster events are only available for 30 days thus clusterStateFact and jobRunCostPotentialFact will not load for data older than 30 days.
Via A Notebook
Now that we understand our config and have a valid workspace object, the Overwatch pipeline can be run. It’s often a good idea to run the first run from a notebook to validate the configuration and the pipeline.
private val args = JsonUtils.objToJson(params).compactString
val workspace = Initializer(Array(args), debugFlag = false)
Bronze(workspace).run()
Silver(workspace).run()
Gold(workspace).run()
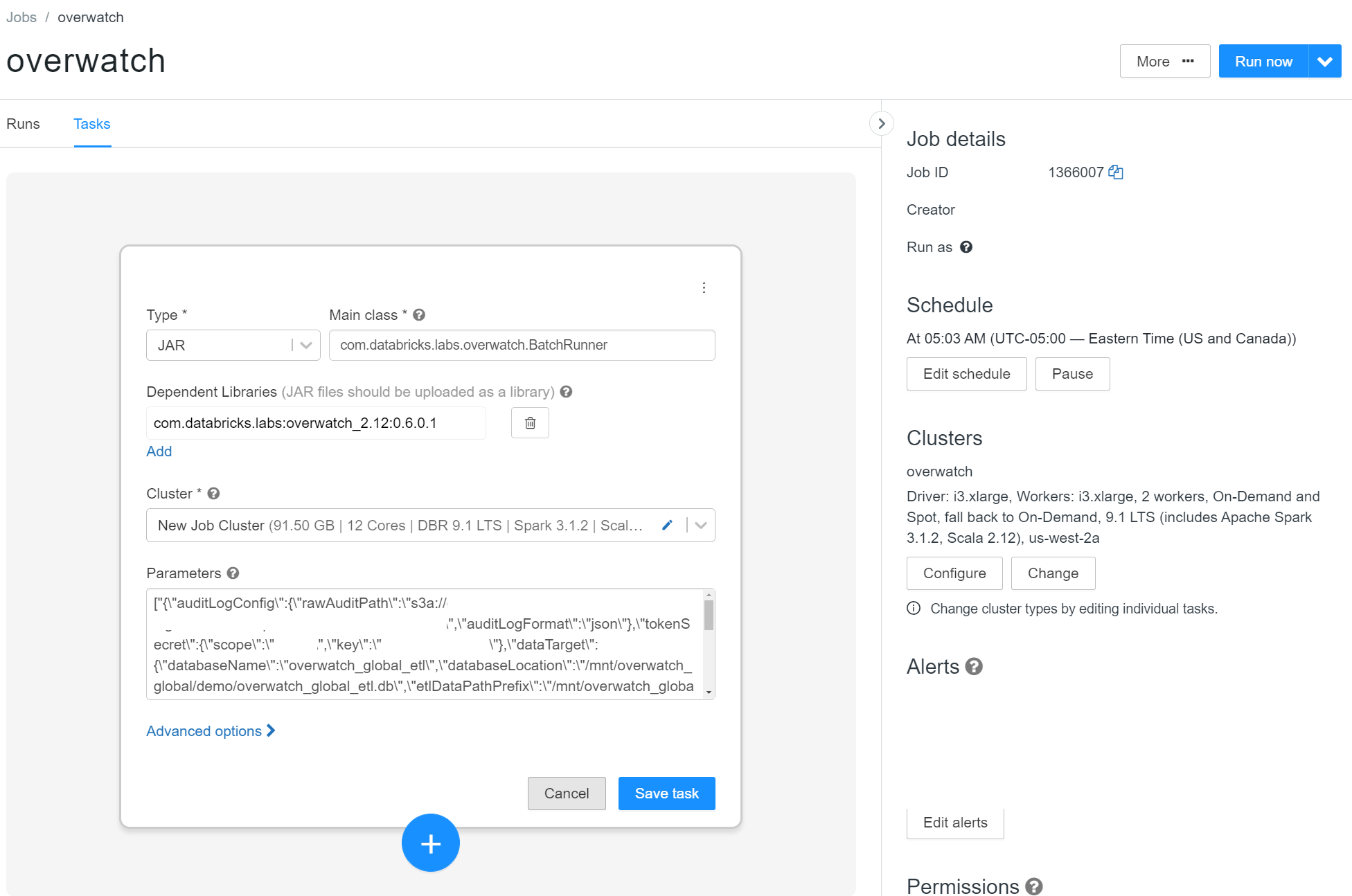
Via Main Class
AZURE Must use version 0.5.0.4 or later so as not to pass EH connection string credentials into arguments in clear text.
The Main class version does the same thing as the notebook version the difference is just how it’s kicked off and
configured. The tricky party about the main class is that the parameters must be passed in as a json array of
escaped strings (this is why the JsonUtils above have the option for escapedString.
The “OverwatchParams” object gets serialized and passed into the args of the Main Class. To
simplify the creation of this string simply follow the example above Initializing The Environment
and use the escapedConfigString. Now that you have the string, setup the job with that string as the Parameters.
The Main Class for historical batch is com.databricks.labs.overwatch.BatchRunner
Notice that the escaped Overwatch Json config goes inside the array of strings parameter config
["<overwatch_escaped_params>"]
["bronze", "<overwatch_escaped_params>"]
["silver", "<overwatch_escaped_params>"]
["gold", "<overwatch_escaped_params>"]
If a single argument passed to main class: Arg(0) is Overwatch Parameters json string (escaped if sent through API). If TWO arguments are passed to main class: Arg(0) must be ‘bronze’, ‘silver’, or ‘gold’ corresponding to the Overwatch Pipeline layer you want to be run. Arg(1) will be the Overwatch Parameters json string.
Configuring Custom Costs
There are three essential components to the cost function:
- The node type and its associated contract price
- The node type and its associated DBUs per hour
- The DBU contract prices for the SKU under which your DBUs are charged such as:
- Interactive
- Automated
- DatabricksSQL
- JobsLight
The DBU contract costs are captured from the Overwatch Configuration maintained as a slow-changing-dimension in the dbuCostDetails table. The compute costs and dbu to node associations are maintained as a slow-changing-dimension in the instanceDetails table.
- IMPORTANT These tables are automatically created in the dataTarget upon first initialization of the pipeline.
- DO NOT try to manually create the target database outside of Overwatch as that will lead to database validation errors.
To customize costs generate the workspace object as demonstrated in the Jump Start Notebooks above. Once the configs are built out and the workspace object is ready, the Bronze pipeline can be instantiated (but not ran) to initialize the custom cost tables for customization.
Note that each subsequent workspace referencing the same dataTarget will append default compute prices to instanceDetails
table if no data is present for that organization_id (i.e. workspace).
If you would like to customize compute costs for all workspaces,
export the instanceDetails dataset to external editor (after first init), add the required metrics referenced above
for each workspace, and update the target table with the customized cost information. Note that the instanceDetails
object in the consumer database is just a view so you must edit/overwrite the underlying table in the ETL database. The view
will automatically be recreated upon first pipeline run.
IMPORTANT These cost tables are slow-changing-dimensions and thus they have specific rule requirements; familiarize yourself with the details at the links below. If the rules fail, the Gold Pipeline will fail with specific costing errors to help you resolve it.
Helpful Tool (AZURE_Only) to get pricing by region by node.
Sample compute details available below. These are only meant for reference, they do not have all required fields. Follow the instruction above for how to implement custom costs. AWS Example | Azure Example
Overwatch Scopes
The Overwatch parameters take in scopes which reference an abstract Databricks component that can be enabled/disabled for Overwatch observability. If a scope such as jobs is disabled, none of the bronze/silver/gold modules that materialize databricks jobs will be created. Furthermore, neither will any of their dependencies. For example, if jobs is disabled, jobs, jobRuns and jobRunCostPotentialFact will all be missing from the data model as they were disabled. It’s recommended to just leave them all enabled unless there’s a specific need to disable a scope. For more information on scopes and modules please refer to Modules
Security Considerations
Overwatch Read Requirements
The account that owns/runs the Overwatch process must have access to read all objects that are desired to be captured in the Overwatch Data Model. For example, if jobs,clusters,pools modules are enabled, it’s imperative that the Overwatch user have access to read the jobs, job runs, clusters, and pools and their histories and definitions to properly populate the Overwatch data model. The same is true with regard to input/output paths, Overwatch must have access to all configured input/output paths.
Overwatch Output Data
Overwatch, by default, will create a single database that, is accessible to everyone in your organization unless you specify a location for the database in the configuration that is secured. Several of the modules capture fairly sensitive data such as users, userIDs, etc. It is suggested that the configuration specify two databases in the configuration:
- ETL database – hold all raw and intermediate transform entities. This database can be secured allowing only the necessary data engineers direct access.
- Consumer database – Holds views only and is easy to secure using Databricks' table ACLs (assuming no direct scala access). The consumer database holds only views that point to tables so additional security can easily be attributed at this layer.
For more information on how to configure the separation of ETL and consumption databases, please reference the configuration page.
Additional steps can be taken to secure the storage location of the ETL entities as necessary. The method for securing access to these tables would be the same as with any set of tables in your organization.
Accessing the Secret[s]
The owner of the Overwatch Run must have access to the secret[s] that store the sensitive info. For example, if John runs a notebook, John must have access to the secrets used in the config. The same is true if John creates a scheduled job and sets it to run on a schedule. This changes when it goes to production though and John sends it through production promotion process and the job is now owned by the etl-admin principle. Since the job is now owned by the etl-admin principle, etl-admin must have access to the relevant secrets.