Configuration
Configuration Basics
The Overwatch configuration can be created as a case class of OverwatchParams or as a json string passed into
the main class com.databricks.labs.overwatch.BatchRunner. When passed in as a json string, it is
serialized into an instance of OverwatchParams. This provides strong validation on the input parameters
and strong typing for additional validation options. All configs attempt to be defaulted to a reasonable default
where possible. If a default is set, passing in a value will overwrite the default.
Config Examples
Below are some configurations examples of building the configuration parameters called params which is a variable set to contain an instance of the class OverwatchParams.
Once the config has been created according to your needs, refer back to the Getting Started - Run Via Notebook or Getting Started - Run Via Main Class section to see how it’s can be used when executing the Overwatch Run.
The configuration examples below use a data target prefix of /user/hive/warehouse. It is STRONGLY recommended that a data target with a prefix other than /user/hive/warehouse be used. Even though the tables are external, any spark database located within the default warehouse will drop all tables (including external) with certain drop database commands resulting in permanent data loss. This is default behavior and has nothing to do with Overwatch specifically but it’s called out here as a major precaution. If multiple workspaces are to be configured and someone with write access to this location invokes certain drop database commands, all tables will be permanently deleted for all workspaces.
Azure Example
Azure does require an event hub to be set up and referenced in the config as an AzureAuditLogEventhubConfig. More details for setting up this Event Hub can be found in the Azure Environment Setup page. An example notebook can be found here.
import com.databricks.labs.overwatch.pipeline.{Initializer, Bronze, Silver, Gold}
import com.databricks.labs.overwatch.utils._
private val storagePrefix = /mnt/overwatch_global
private val dataTarget = DataTarget(
Some(etlDB), Some(s"${storagePrefix}/${workspaceID}/${etlDB}.db"), Some(s"${storagePrefix}/global_share"),
Some(consumerDB), Some(s"${storagePrefix}/${workspaceID}/${consumerDB}.db")
)
private val tokenSecret = TokenSecret(secretsScope, dbPATKey)
// Use the format exactly replacing "scope" and "key" with the names of the scope and key where your
// Event Hub connection string is stored.
private val ehConnScopeKeyString = "{{secrets/scope/key}}"
private val ehStatePath = s"${storagePrefix}/${workspaceID}/ehState"
private val badRecordsPath = s"${storagePrefix}/${workspaceID}/sparkEventsBadrecords"
private val azureLogConfig = AzureAuditLogEventhubConfig(connectionString = ehConnScopeKeyString, eventHubName = ehName, auditRawEventsPrefix = ehStatePath)
private val interactiveDBUPrice = 0.56
private val automatedDBUPrice = 0.26
private val DatabricksSQLDBUPrice = 0.22
private val automatedJobsLightDBUPrice = 0.10
private val customWorkspaceName = workspaceID // customize this to a custom name if custom workspace_name is desired
val params = OverwatchParams(
auditLogConfig = AuditLogConfig(azureAuditLogEventhubConfig = Some(azureLogConfig)),
dataTarget = Some(dataTarget),
tokenSecret = Some(tokenSecret),
badRecordsPath = Some(badRecordsPath),
overwatchScope = Some(scopes),
maxDaysToLoad = maxDaysToLoad,
databricksContractPrices = DatabricksContractPrices(interactiveDBUPrice, automatedDBUPrice, DatabricksSQLDBUPrice, automatedJobsLightDBUPrice),
primordialDateString = Some(primordialDateString),
intelligentScaling = IntelligentScaling(enabled = true, minimumCores = 16, maximumCores = 64, coeff = 1.0), // Until further notice, recommend this to be disabled. Intelligent scaling is being re-examined as of 0.6.1.2
workspace_name = Some(customWorkspaceName), // as of 0.6.0
externalizeOptimize = false // as of 0.6.0
)
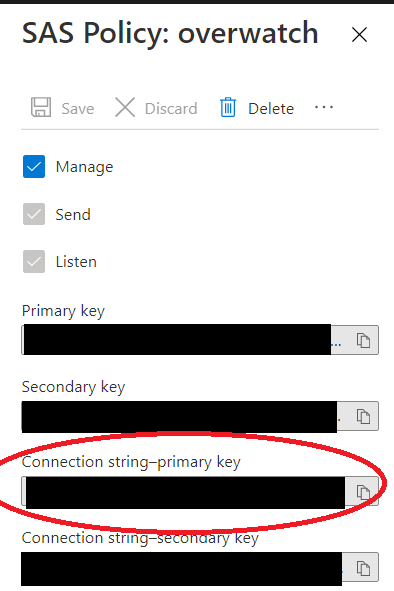
NOTE The connection string stored in the ehConnScopeKeyString above is stored as a secret since it contains sensitive information.
THIS IS NOT THE KEY but the actual connection string from the SAS Policy. To find this follow the path in the Azure portal below.
eh-namespace –> eventhub –> shared access policies –> Connection String-primary key
The connection string should begin with Endpoint=sb://. Note that the policy only needs the Listen permission
AWS Example
An example notebook can be found here.
import com.databricks.labs.overwatch.pipeline.{Initializer, Bronze, Silver, Gold}
import com.databricks.labs.overwatch.utils._
private val storagePrefix = /mnt/overwatch_global
private val dataTarget = DataTarget(
Some(etlDB), Some(s"${storagePrefix}/${workspaceID}/${etlDB}.db"), Some(s"${storagePrefix}/global_share"),
Some(consumerDB), Some(s"${storagePrefix}/${workspaceID}/${consumerDB}.db")
)
private val tokenSecret = TokenSecret(secretsScope, dbPATKey)
private val badRecordsPath = s"${storagePrefix}/${workspaceID}/sparkEventsBadrecords"
private val auditSourcePath = "/path/to/my/workspaces/raw_audit_logs" // INPUT: workspace audit log directory
private val interactiveDBUPrice = 0.56
private val automatedDBUPrice = 0.26
private val DatabricksSQLDBUPrice = 0.22
private val automatedJobsLightDBUPrice = 0.10
private val customWorkspaceName = workspaceID // customize this to a custom name if custom workspace_name is desired
val params = OverwatchParams(
auditLogConfig = AuditLogConfig(rawAuditPath = Some(auditSourcePath), auditLogFormat = "json"),
dataTarget = Some(dataTarget),
tokenSecret = Some(tokenSecret),
badRecordsPath = Some(badRecordsPath),
overwatchScope = Some(scopes),
maxDaysToLoad = maxDaysToLoad,
databricksContractPrices = DatabricksContractPrices(interactiveDBUPrice, automatedDBUPrice, DatabricksSQLDBUPrice, automatedJobsLightDBUPrice),
primordialDateString = Some(primordialDateString),
intelligentScaling = IntelligentScaling(enabled = true, minimumCores = 16, maximumCores = 64, coeff = 1.0),
workspace_name = Some(customWorkspaceName), // as of 0.6.0
externalizeOptimize = false // as of 0.6.0
)
Simplifying the Config
The simplest configuration possible is one that uses as many defaults as possible. A config with all defaults is likely just for testing and not sufficient for real-world application. As such, examples for the complete configs are illustrated above. Reference the defaults below to see which ones you may omit. Note that if you omit certain configs, their defaults will still be present in the json config.
OverwatchParams
The configuration structure required for Overwatch
| Config | Required Override | Default Value | Type | AsOfVersion | Description |
|---|---|---|---|---|---|
| auditLogConfig | Y | NULL | AuditLogConfig | 0.5.x | Databricks Audit Log delivery information. |
| tokenSecret | N | Execution Owner’s Token | Option[TokenSecret] | 0.5.x | Secret retrieval information |
| dataTarget | N | DataTarget(“overwatch”, “/user/hive/warehouse/{databaseName}.db”, “/user/hive/warehouse/{databaseName}.db”) | Option[DataTarget] | 0.5.x | What to call the database and where to store it |
| badRecordsPath | N | /tmp/overwatch/badRecordsPath | Option[String] | 0.5.x | When reading the log files, where should Overwatch store the records / files that cannot be parsed. Overwatch must have write permissions to this path |
| overwatchScope | N | all | Option[Seq[String]] | 0.5.x | List of modules in scope for the run. It’s important to note that there are many co-dependencies. When choosing a module, be sure to also enable it’s requisites. If not value provided, all modules will execute. |
| maxDaysToLoad | N | 60 | Int | 0.5.x | On large, busy workspaces 60 days of data may amount in 10s of TB of raw data. This parameter allows the job to be broken out into several smaller runs. Pipeline will load previous pipeline end time (or primordial_date if first_run) until lesser of [current timestamp or previous pipeline end time + maxDaysToLoad]. Ex: 1 year historical load, first run, don’t want to load full year, set maxDaysToLoad to 14 to test / validate load, when that works increase to 60 or 365 depending on confidence level and data size. |
| primordialDateString | N | Today’s date minus 60 days, format = “yyyy-mm-dd” | String | 0.5.x | Date from which data collection was to begin. This is the earliest date for which data should attempted to be collected. |
| databricksContractPrices | N | DatabricksContractPrices() | DatabricksContractPrices | 0.5.x | Allows the user to globally configure Databricks contract prices to improve dollar cost estimates where referenced. Additionally, these values will be added to the instanceDetails consumer table for custom use. They are also available in com.databricks.labs.overwatch.utils.DBContractPrices(). |
| IntelligentScaling | N | IntelligentScaling() | IntelligentScaling | 0.5.x | Until further notice, recommend this to be disabled. Intelligent scaling is being re-examined as of 0.6.1.2 |
| workspace_name | N | <organization_id> | Option[String] | 0.6.x | Allows the user to specify the workspace_name to be different than the default, canonical workspace_id (i.e. organization_id). This is helpful during analysis as it provides a human-legible reference for the workspace |
| externalizeOptimize | N | false | Boolean | 0.6.x | Allows the user to externalize the optimize and zorders done on the delta tables. This can be run as a secondary job with different cluster configs at different intervals increasing efficiency |
| tempWorkingDir | N | /tempWorkingDir/<organization_id> | String | 0.6.1 | Provides ability to override temporary working directory. This directory gets cleaned up before and after each run. |
| apiEnvConfig | N | ApiEnvConfig() | Option[ApiEnvConfig] | 0.7.x | Allows the user to configure api calls. |
AuditLogConfig
Config to point Overwatch to the location of the delivered audit logs
| Config | Required Override | Default Value | Type | Description |
|---|---|---|---|---|
| rawAuditPath | Y | None | Option[String] | Top-level path to directory containing workspace audit logs delivered by Databricks. The Overwatch user must have read access to this path |
| auditLogFormat | N | json | String | AWS ONLY - When using AWS and audit logs are delivered in a format other than json (default) this can be changed to reflect the audit log source data type. Supported types are json, parquet, delta |
| azureAuditLogEventhubConfig | Y (only on Azure) | None | OptionAzureAuditLogEventhubConfig | Required configuration when using Azure as Azure must deliver audit logs via LogAnalytics via Eventhub |
TokenSecret
Overwatch must have permission to perform its functions; these are further discussed in AdvancedTopics. The token secret stores the Databricks Secret scope / key for Overwatch to retrieve. The key should store the token secret to be used which usually starts with “dapi…”
If no TokenSecret is passed into the config, the operation owner’s token will be used. If Overwatch is being executed in a notebook the notebook user’s token will be used. If Overwatch is being executed through a job the token of the job owner will be used. Whatever token is used, it must have the appropriate access or it will result in missing data, or an Overwatch run failure.
| Config | Required Override | Default Value | Type | Description |
|---|---|---|---|---|
| scope | N | NA | String | Databricks secret scope |
| key | N | NA | String | Databricks secret key within the scope defined in the Scope parameter |
DataTarget
Where to create the database and what to call it. This must be defined on first run or Overwatch will create a database named “Overwatch” at the default location which is “/user/hive/warehouse/overwatch.db”. This is challenging to change later, so be sure you choose a good starting point. After the initial run, this must not change without and entire database migration. Overwatch can perform destructive tasks within its own database and this is how it protects itself against harming existing data. Overwatch creates specific metadata inside the database at creation time to ensure the database is created and owned by the Overwatch process. Furthermore, metadata is managed to track schema versions and other states.
| Config | Required Override | Default Value | Type | Description |
|---|---|---|---|---|
| databaseName | N | Overwatch | Option[String] | Name of the primary database to be created on first run or to which will be appended on subsequent runs. This database is typically used as the ETL database only as the consumer database is also usually specified to have a different name. If consumerDatabase is also specified in the configuration, on the ETL entities will be stored in this datbase. |
| databaseLocation | N | /user/hive/warehouse/{databaseName}.db | Option[String] | Location of the Overwatch database. Any compatible fully-qualified URI can be used here as long as Overwatch has access to write the target. Most customers, however, mount the qualified path and reference the mount point for simplicity but this is not required and may not be possible depending on security requirements and environment. |
| etlDataPathPrefix | N | {databaseLocation} | Option[String] | The location the data will actually be stored. This is critical as data (even EXTERNAL) stored underneath a database path can be deleted if a user call drop database or drop database cascade. This is even more significant when working with multiple workspaces as the risk increases with the breadth of access. |
| consumerDatabaseName | N | {databaseName} | Option[String] | Will be the same as the databaseName if not otherwise specified. Holds the user-facing entities and separates them from all the intermediate ETL entities for a less cluttered experience, easy-to-find entities, and simplified security. |
| ConsumerDatabaseLocation | N | /user/hive/warehouse/{consumerDatabaseName}.db | Option[String] | See databaseLocation above |
AzureAuditLogEventhubConfig
Not Required when using AWS Eventhub streaming environment configurations
| Config | Required Override | Default Value | Type | Description |
|---|---|---|---|---|
| connectionString | Y | NA | String | Should be stored in a secret. The value format here should be {{secrets/scope/key}}. Replace scope and key with the names of the scope and key where the EventHub connection string with primary key is stored. |
| eventHubName | Y | NA | String | Retrieve from Azure Portal Event Hub |
| auditRawEventsPrefix | Y | NA | String | Path prefix for checkpoint directories |
| maxEventsPerTrigger | N | 10000 | Int | Events to pull for each trigger, this should be increased during initial cold runs or runs that have very large numbers of audit log events. |
| minEventsPerTrigger | N | 10 | Int | Large workspaces can send events faster than batches can complete thus a minimum threshold for new events is needed. Optional override as of v0603 |
| auditRawEventsChk | N | {auditRawEventsPrefix}/rawEventsCheckpoint | Option[String] | Checkpoint Directory name for the raw dump of events from Eventhub. This directory gets overwritten upon successful pull into Overwatch. |
| auditLogChk | N | {auditRawEventsPrefix}/auditLogBronzeCheckpoint | Option[String] | DEPRECATED Checkpoint Directory name for the audit log stream target. This target will continuously grow as more audit logs are created and delivered |
DatabricksContractPrices
| Config | Required Override | Default Value | Type | Description |
|---|---|---|---|---|
| interactiveDBUCostUSD | N | 0.56 | Double | Approximate list price of interactive DBU |
| automatedDBUCostUSD | N | 0.26 | Double | Approximate list price of automated DBU |
| sqlComputeDBUCostUSD | N | 0.22 | Double | Approximate list price of DatabricksSQL DBU |
| jobsLightDBUCostUSD | N | 0.10 | Double | Approximate list price of JobsLight Automated DBU |
IntelligentScaling
Until further notice, recommend this to be disabled. Intelligent scaling is being re-examined as of 0.6.1.2
| Config | Required Override | Default Value | Type | Description |
|---|---|---|---|---|
| enabled | N | false | Double | Approximate list price of interactive DBU |
| minimumCores | N | 4 | Int | Minimum number of cores to be used during Overwatch run |
| maximumCores | N | 512 | Int | Maximum number of cores to be used during Overwatch run |
| coeff | N | 1.0 | Double | Scaler, each module has a scale based on it’s size relative to the other modules. This variable acts as a scaler to the scaler, if the modules are scaling too fast (or not fast enough), this can be tweaked to increase the variability of the scaling from the starting core count. |
ApiEnvConfig
Configurations of Api calls.
| Config | Required Override | Default Value | Type | Description |
|---|---|---|---|---|
| successBatchSize | N | 200 | Int | Responce of successful api calls are stored into the disk.This config signifies the batch size. |
| errorBatchSize | N | 500 | Int | Failed api calls are stored into disk.This config signifies the batch size of failed api calls. |
| enableUnsafeSSL | N | false | Boolean | Enable unasfe SSL. |
| threadPoolSize | N | 4 | Int | Number of threads to perform api calls in parallel. |
| apiWaitingTime | N | 300000 | milliseconds | Api waiting time incase of delay in response. |
| apiProxyConfig | N | ApiProxyConfig() | Option[ApiProxyConfig] | Allows user to configure proxy. |
ApiProxyConfig
Configurations of proxy.
| Config | Required Override | Default Value | Type | Description |
|---|---|---|---|---|
| proxyHost | N | None | Option[String] | Proxy host. |
| proxyPort | N | None | Option[Int] | Proxy port. |
| proxyUserName | N | None | Option[String] | Proxy user name. |
| proxyPasswordScope | N | None | Option[String] | Secret Scope which contain key for password. |
| proxyPasswordKey | N | None | Option[String] | Key for password(This should be present in the secret scope). |