AWS
Configuring Overwatch on AWS - Databricks
Reach out to your Customer Success Engineer (CSE) to help you with these tasks as needed. To get started, the Basic Deployment configuration. As more modules are enabled, additional environment configuration may be required in addition to the Basic Deployment.
There are two primary sources of data that need to be configured:
- Audit Logs
- These will be delivered to the configured bucket. These buckets are configured on a per-workspace basis and can be delivered to the same target bucket, just ensure that the prefixes are different to avoid collisions. We don’t want multiple workspaces delivering into the same prefix. The audit logs contain data for every interaction within the environment and are used to track the state of various objects through time along with which accounts interacted with them. This data is relatively small and delivery occurs infrequently which is why it’s rarely of any consequence to deliver audit logs to buckets even outside of the control plane region.
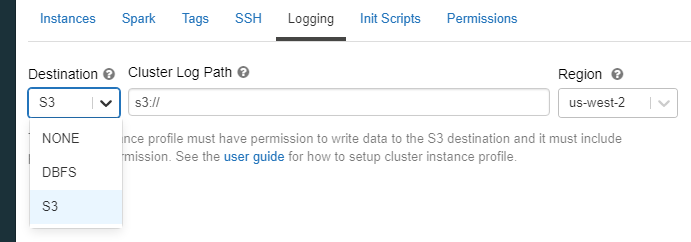
- Cluster Logs - Crucial to get the most out of Overwatch
- Cluster logs delivery location is configured in the cluster spec –> Advanced Options –> Logging. These logs can get quite large and they are stored in a very inefficient format for query and long-term storage. As such, it’s crucial to store these logs in the same region as the worker nodes for best results. Additionally, using dedicated buckets provides more flexibility when configuring TTL (time-to-live) to minimize long-term, unnecessary costs. It’s not recommended to store these on DBFS directly (dbfs mount points are ok).
- Best Practice - Multi-Workspace – When multiple workspaces are using Overwatch within a single region it’s best to ensure that each are going to their own prefix, even if sharing a bucket. This greatly reduces Overwatch scan times as the log files build up.
- Best Practice - Sharding – When many clusters send their logs to the same prefix it reduces the AWS read parallelism for these small files. It’s best to find a methodology for log prefixes that works for your org. One example would be to have each workspace and each team store their logs in a specific prefix, etc to break up the number of log files buried inside a single prefix. Overwatch will do all the work to aggregate these logs and deliver the data to the data model.
| Basic Deployment | Multi-Region Deployment |
|---|---|
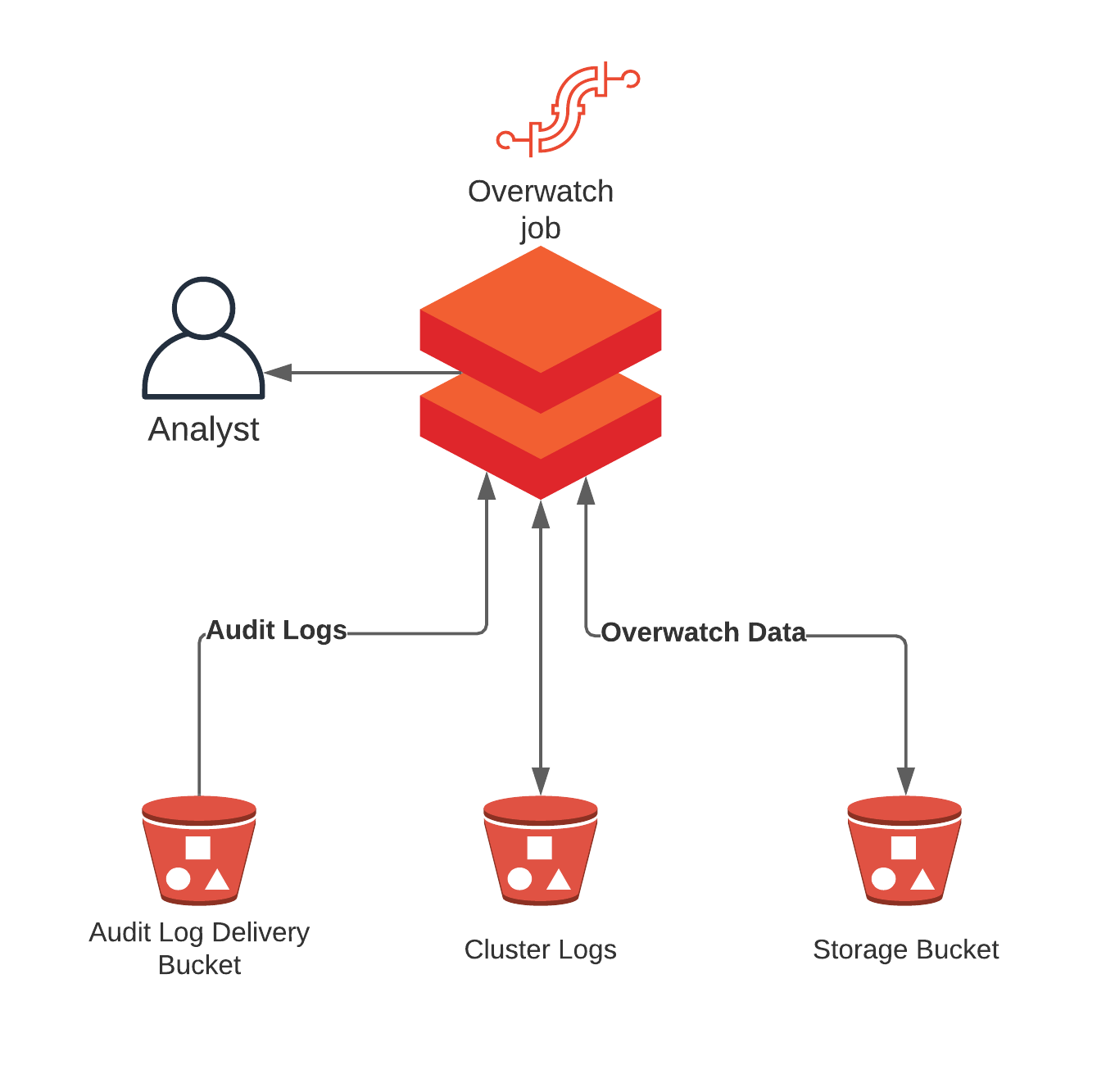 |
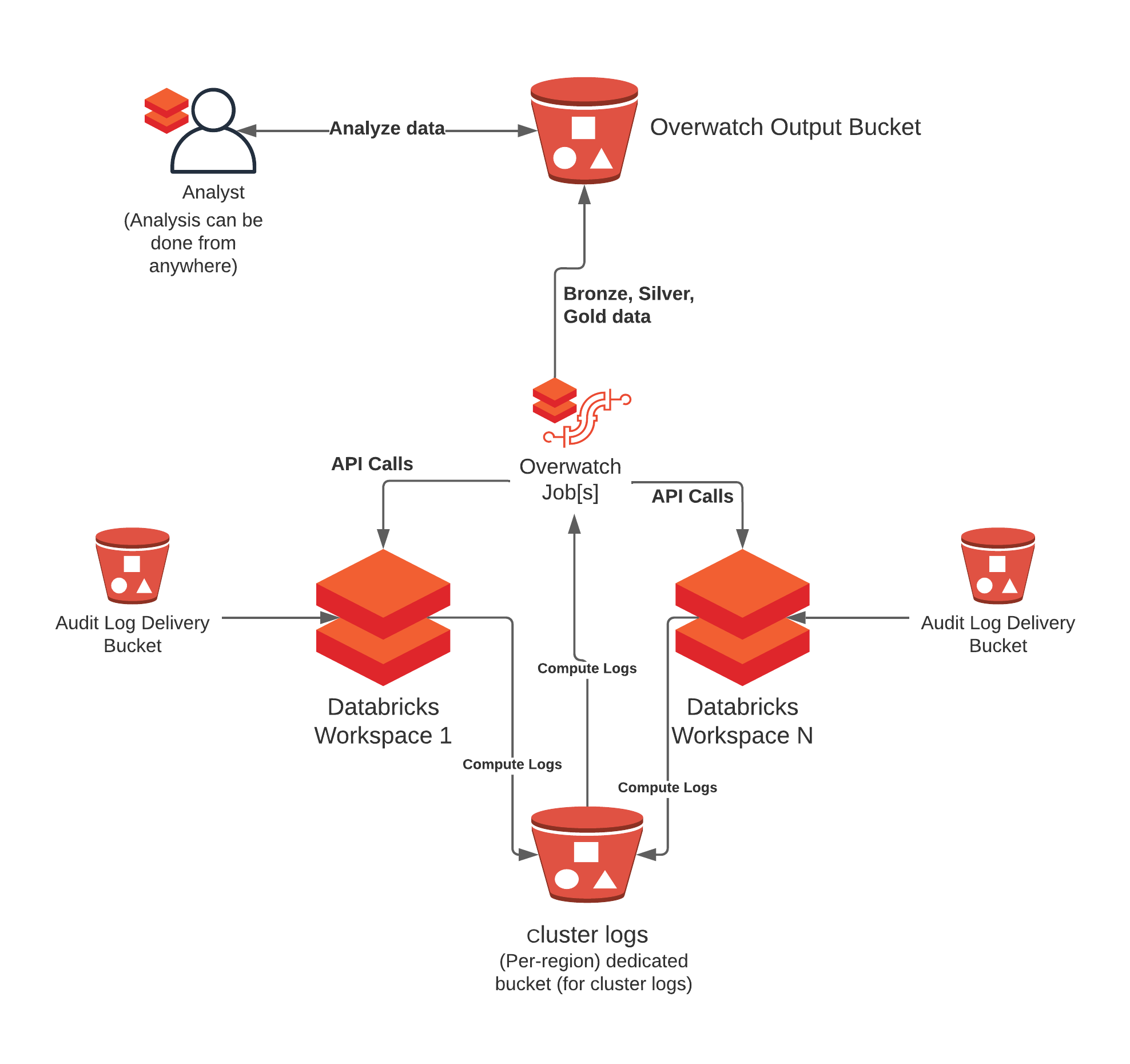 |
With Databricks Billable Usage Delivery Logs
Detailed costs data directly from Databricks. This data can significantly enhance deeper level cost metrics. Even though Overwatch doesn’t support this just yet, if you go ahead and configure the delivery of these reports, when Overwatch begins supporting it, it will be able to load all the historical data from the day that you began receiving it.
In the meantime, it’s easy to join these up with the Overwatch data for cost validation and / or exact cost break down by dimensions not supported in the usage logs.
With Cloud Provider Costs
There can be substantial cloud provider costs associated with a cluster. Databricks (and Overwatch) has no visibility to this by default. The plan here is to work with a few pilot customers to build API keys with appropriate permissions to allow Overwatch to capture the compute, storage, etc costs associated with cluster machines. The primary focus here would be to help customers visualize and optimize SPOT markets by illuminating costs and opportunities across different AZs in your region given you machine types. Additionally, Overwatch could make recommendations on:
- Actual compute/disk costs associated with clusters
- Optimal time of day for large jobs
- Small adjustments to node type by hour of day (i.e. i3.4xlarge instead of i3.2xlarge)
The goal is to go even deeper than compute by looking at disk IO as well to determine the benefit/need of NVMEs vs SSDs vs HDDs. Picking the right storage type and amount can save large sums over the course of a year. Picking the wrong type (or not enough) can result in elevated compute bills due to inefficiencies. If you’re interested in this feature and would like to participate, please inform your CSE and/or Databricks Account Team.
Targeted 2021