Using grid index systems in Mosaic
[ ]:
from pyspark.sql.functions import *
from mosaic import enable_mosaic
enable_mosaic(spark, dbutils)
Set operations over big geospatial datasets become very expensive without some form of spatial indexing.
Spatial indexes not only allow operations like point-in-polygon joins to be partitioned but, if only approximate results are required, can be used to reduce these to deterministic SQL joins directly on the indexes.
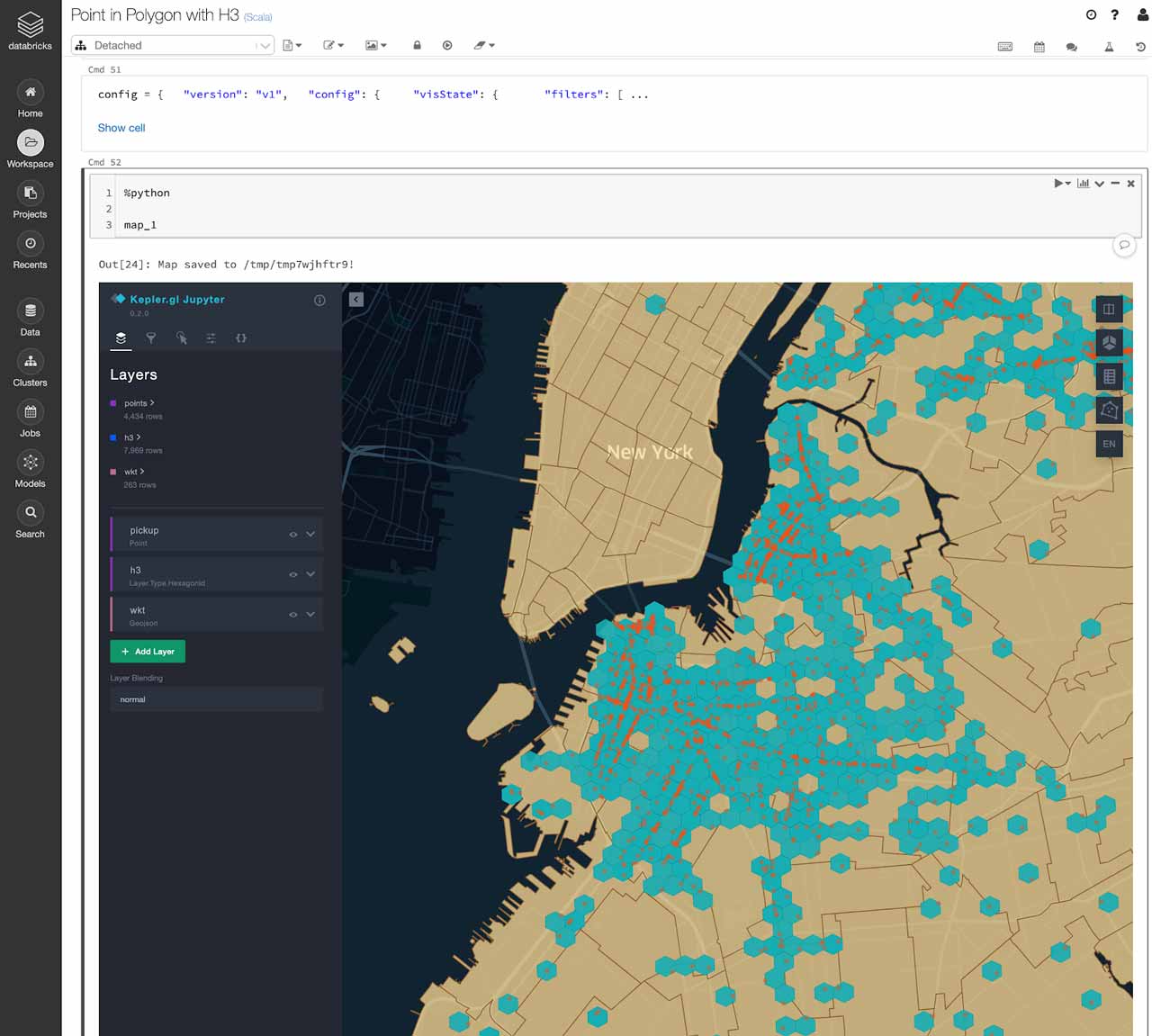
The workflow for a point-in-poly spatial join might look like the following:
1. Read the source point and polygon datasets.
[ ]:
drop_cols = [
"rate_code_id", "store_and_fwd_flag", "dropoff_longitude",
"dropoff_latitude", "payment_type", "fare_amount",
"extra", "mta_tax", "tip_amount", "tolls_amount",
"total_amount"
]
trips = (
spark.table("delta.`/databricks-datasets/nyctaxi/tables/nyctaxi_yellow`")
.drop(*drop_cols)
.limit(5_000_000)
.repartition(sc.defaultParallelism * 20)
)
trips.show()
+---------+-------------------+-------------------+---------------+-------------+----------------+---------------+
vendor_id| pickup_datetime| dropoff_datetime|passenger_count|trip_distance|pickup_longitude|pickup_latitude|
+---------+-------------------+-------------------+---------------+-------------+----------------+---------------+
CMT|2009-01-01 20:07:33|2009-01-01 20:12:28| 1| 0.8| -74.001041| 40.731|
CMT|2009-01-06 15:29:12|2009-01-06 15:51:57| 2| 3.3| -73.996489| 40.725742|
CMT|2010-02-14 17:42:16|2010-02-14 17:55:03| 1| 3.4| -74.002949| 40.734254|
CMT|2010-02-11 18:19:01|2010-02-11 18:27:54| 1| 1.5| -73.998133| 40.682463|
VTS|2009-04-29 12:26:00|2009-04-29 12:35:00| 3| 2.05| -74.001332| 40.72006|
VTS|2009-04-24 15:03:00|2009-04-24 15:23:00| 2| 2.89| -73.989952| 40.734625|
CMT|2010-02-28 13:55:44|2010-02-28 14:02:37| 1| 1.2| -74.006015| 40.735279|
VTS|2009-09-27 08:46:00|2009-09-27 08:59:00| 1| 3.97| -74.000148| 40.717468|
CMT|2010-02-18 09:48:52|2010-02-18 10:08:38| 1| 3.0| -73.995177| 40.725297|
CMT|2009-04-09 20:33:44|2009-04-09 20:39:33| 2| 0.6| -73.990133| 40.729321|
CMT|2010-02-13 22:41:10|2010-02-13 23:07:04| 1| 4.2| -74.009175| 40.706284|
CMT|2009-01-25 20:06:51|2009-01-25 20:12:37| 1| 1.3| -74.007384| 40.717929|
VTS|2010-02-27 18:19:00|2010-02-27 18:38:00| 1| 4.2| -74.011512| 40.710588|
VTS|2010-02-15 10:17:00|2010-02-15 10:24:00| 1| 1.74| -74.016442| 40.711617|
CMT|2009-12-26 18:45:49|2009-12-26 18:59:08| 1| 4.8| -74.01014| 40.712263|
CMT|2009-12-06 01:00:07|2009-12-06 01:11:41| 2| 4.2| -74.002505| 40.729001|
VTS|2009-10-04 14:36:00|2009-10-04 14:42:00| 1| 1.13| -74.006767| 40.718942|
CMT|2009-01-18 00:20:50|2009-01-18 00:36:29| 3| 2.1| -73.993258| 40.721401|
VTS|2009-05-18 13:24:00|2009-05-18 13:33:00| 1| 1.91| -73.992785| 40.730412|
VTS|2009-11-11 21:51:00|2009-11-11 22:13:00| 5| 4.71| -74.010065| 40.733383|
+---------+-------------------+-------------------+---------------+-------------+----------------+---------------+
only showing top 20 rows
[ ]:
from mosaic import st_geomfromgeojson
user = spark.sql("select current_user() as user").collect()[0]["user"]
neighbourhoods = (
spark.read.format("json")
.load(f"dbfs:/FileStore/shared_uploads/{user}/NYC_Taxi_Zones.geojson")
.repartition(sc.defaultParallelism)
.withColumn("geometry", st_geomfromgeojson(to_json(col("geometry"))))
.select("properties.*", "geometry")
.drop("shape_area", "shape_leng")
)
neighbourhoods.show()
+-------------+-----------+--------+-------------------+--------------------+
borough|location_id|objectid| zone| geometry|
+-------------+-----------+--------+-------------------+--------------------+
Brooklyn| 123| 123| Homecrest|{6, 4326, [[[-73....|
Manhattan| 153| 153| Marble Hill|{6, 4326, [[[-73....|
Brooklyn| 112| 112| Greenpoint|{6, 4326, [[[-73....|
Manhattan| 233| 233|UN/Turtle Bay South|{6, 4326, [[[-73....|
Manhattan| 43| 43| Central Park|{6, 4326, [[[-73....|
Queens| 201| 201| Rockaway Park|{6, 4326, [[[-73....|
Queens| 131| 131| Jamaica Estates|{6, 4326, [[[-73....|
Brooklyn| 111| 111|Green-Wood Cemetery|{6, 4326, [[[-73....|
Queens| 226| 226| Sunnyside|{6, 4326, [[[-73....|
Queens| 129| 129| Jackson Heights|{6, 4326, [[[-73....|
Manhattan| 120| 120| Highbridge Park|{6, 4326, [[[-73....|
Brooklyn| 76| 76| East New York|{6, 4326, [[[-73....|
Manhattan| 24| 24| Bloomingdale|{6, 4326, [[[-73....|
Manhattan| 202| 202| Roosevelt Island|{6, 4326, [[[-73....|
Manhattan| 100| 100| Garment District|{6, 4326, [[[-73....|
Staten Island| 251| 251| Westerleigh|{6, 4326, [[[-74....|
Manhattan| 74| 74| East Harlem North|{6, 4326, [[[-73....|
Queens| 98| 98| Fresh Meadows|{6, 4326, [[[-73....|
Manhattan| 211| 211| SoHo|{6, 4326, [[[-74....|
Bronx| 174| 174| Norwood|{6, 4326, [[[-73....|
+-------------+-----------+--------+-------------------+--------------------+
only showing top 20 rows
2. Compute the resolution of index required to optimize the join.
[ ]:
from mosaic import MosaicFrame
neighbourhoods_mdf = MosaicFrame(neighbourhoods, "geometry")
help(neighbourhoods_mdf.get_optimal_resolution)
Help on method get_optimal_resolution in module mosaic.core.mosaic_frame:
get_optimal_resolution(sample_rows: Union[int, NoneType] = None, sample_fraction: Union[float, NoneType] = None) -> int method of mosaic.core.mosaic_frame.MosaicFrame instance
Analyzes the geometries in the currently selected geometry column and proposes an optimal
grid-index resolution.
Provide either `sample_rows` or `sample_fraction` parameters to control how much data is passed to the analyzer.
(Providing too little data to the analyzer may result in a `NotEnoughGeometriesException`)
Parameters
----------
sample_rows: int, optional
The number of rows to sample.
sample_fraction: float, optional
The proportion of rows to sample.
Returns
-------
int
The recommended grid-index resolution to apply to this MosaicFrame.
[ ]:
(resolution := neighbourhoods_mdf.get_optimal_resolution(sample_fraction=1.))
Out[15]: 9
3. Apply the index to the set of points in your left-hand dataframe.
This will generate an index value that corresponds to the grid ‘cell’ that this point occupies.
[ ]:
from mosaic import grid_longlatascellid
indexed_trips = trips.withColumn("ix", grid_longlatascellid(lon="pickup_longitude", lat="pickup_latitude", resolution=lit(resolution)))
indexed_trips.show()
+---------+-------------------+-------------------+---------------+-------------+----------------+---------------+------------------+
vendor_id| pickup_datetime| dropoff_datetime|passenger_count|trip_distance|pickup_longitude|pickup_latitude| ix|
+---------+-------------------+-------------------+---------------+-------------+----------------+---------------+------------------+
DDS|2009-01-17 18:49:57|2009-01-17 18:56:29| 3| 1.2| -74.004043| 40.733409|617733151092113407|
DDS|2009-12-01 00:47:52|2009-12-01 01:00:16| 1| 3.4| -73.991702| 40.726342|617733151087132671|
CMT|2009-02-09 16:50:21|2009-02-09 17:02:47| 1| 2.6| -73.999673| 40.733586|617733123805806591|
CMT|2009-12-07 07:15:47|2009-12-07 07:32:07| 1| 3.8| -74.01211| 40.716893|617733151084773375|
VTS|2009-10-16 22:02:00|2009-10-16 22:08:00| 1| 1.1| -74.010903| 40.71624|617733151084773375|
VTS|2009-12-23 22:13:00|2009-12-23 22:18:00| 1| 0.37| -74.002343| 40.73366|617733151092113407|
VTS|2009-12-12 01:24:00|2009-12-12 01:38:00| 2| 3.55| -74.002565| 40.728188|617733151091326975|
CMT|2009-12-07 13:10:37|2009-12-07 13:13:45| 1| 0.5| -73.999184| 40.73428|617733123805806591|
CMT|2009-11-08 22:20:44|2009-11-08 22:31:23| 1| 1.9| -74.003029| 40.733385|617733151092113407|
VTS|2009-12-27 20:01:00|2009-12-27 20:04:00| 1| 1.04| -74.000227| 40.732603|617733151092375551|
VTS|2009-02-13 14:33:00|2009-02-13 14:50:00| 3| 1.59| -74.006535| 40.732303|617733151092637695|
CMT|2009-11-15 21:13:32|2009-11-15 21:25:56| 3| 3.0| -73.998795| 40.730621|617733151092375551|
VTS|2009-01-08 18:13:00|2009-01-08 18:33:00| 2| 4.18| -74.0079| 40.712012|617733151021334527|
CMT|2009-11-30 13:30:13|2009-11-30 13:41:55| 1| 1.6| -74.004487| 40.734072|617733151092637695|
CMT|2009-01-11 20:02:22|2009-01-11 20:08:15| 1| 1.0| -74.004493| 40.713349|617733151020810239|
CMT|2009-12-30 18:46:08|2009-12-30 19:02:23| 1| 2.3| -74.010798| 40.716717|617733151084773375|
CMT|2009-11-18 21:50:12|2009-11-18 22:05:19| 1| 5.8| -73.992515| 40.694106|617733151038111743|
VTS|2009-11-21 12:51:00|2009-11-21 13:27:00| 1| 14.18| -73.9923| 40.715218|617733151109414911|
CMT|2009-01-20 09:34:49|2009-01-20 09:37:15| 1| 0.4| -74.0027| 40.733479|617733151092113407|
VTS|2009-01-03 07:07:00|2009-01-03 07:18:00| 1| 7.81| -73.994358| 40.690345|617733151037325311|
+---------+-------------------+-------------------+---------------+-------------+----------------+---------------+------------------+
only showing top 20 rows
4. Compute the set of indices that fully covers each polygon in the right-hand dataframe
This is commonly referred to as a polyfill operation.
[ ]:
from mosaic import grid_polyfill
indexed_neighbourhoods = (
neighbourhoods
.select("*", grid_polyfill("geometry", lit(resolution)).alias("ix_set"))
.drop("geometry")
)
indexed_neighbourhoods.show()
+-------------+-----------+--------+-------------------+--------------------+
borough|location_id|objectid| zone| ix_set|
+-------------+-----------+--------+-------------------+--------------------+
Brooklyn| 123| 123| Homecrest|[6177331514226769...|
Manhattan| 153| 153| Marble Hill|[6177331229858201...|
Brooklyn| 112| 112| Greenpoint|[6177331237832622...|
Manhattan| 233| 233|UN/Turtle Bay South|[6177331238679347...|
Manhattan| 43| 43| Central Park|[6177331225792348...|
Queens| 201| 201| Rockaway Park|[6177331357831659...|
Queens| 131| 131| Jamaica Estates|[6177331242658693...|
Brooklyn| 111| 111|Green-Wood Cemetery|[6177331522277212...|
Queens| 226| 226| Sunnyside|[6177331238566625...|
Queens| 129| 129| Jackson Heights|[6177331243222302...|
Manhattan| 120| 120| Highbridge Park|[6177331231976325...|
Brooklyn| 76| 76| East New York|[6177331236938711...|
Manhattan| 24| 24| Bloomingdale|[6177331226458193...|
Manhattan| 202| 202| Roosevelt Island|[6177331237777571...|
Manhattan| 100| 100| Garment District|[6177331509717893...|
Staten Island| 251| 251| Westerleigh|[6177331466128588...|
Manhattan| 74| 74| East Harlem North|[6177331226508001...|
Queens| 98| 98| Fresh Meadows|[6177331242448977...|
Manhattan| 211| 211| SoHo|[6177331510784819...|
Bronx| 174| 174| Norwood|[6177331205497159...|
+-------------+-----------+--------+-------------------+--------------------+
only showing top 20 rows
5. ‘Explode’ the polygon index dataframe, such that each polygon index becomes a row in a new dataframe.
[ ]:
exploded_indexed_neighbourhoods = (
indexed_neighbourhoods
.withColumn("ix", explode("ix_set"))
.drop("ix_set")
)
exploded_indexed_neighbourhoods.show()
+--------+-----------+--------+---------+------------------+
borough|location_id|objectid| zone| ix|
+--------+-----------+--------+---------+------------------+
Brooklyn| 123| 123|Homecrest|617733151422676991|
Brooklyn| 123| 123|Homecrest|617733151503417343|
Brooklyn| 123| 123|Homecrest|617733151502893055|
Brooklyn| 123| 123|Homecrest|617733151502368767|
Brooklyn| 123| 123|Homecrest|617733151492407295|
Brooklyn| 123| 123|Homecrest|617733151488737279|
Brooklyn| 123| 123|Homecrest|617733151484542975|
Brooklyn| 123| 123|Homecrest|617733151484018687|
Brooklyn| 123| 123|Homecrest|617733151483494399|
Brooklyn| 123| 123|Homecrest|617733151425560575|
Brooklyn| 123| 123|Homecrest|617733151424511999|
Brooklyn| 123| 123|Homecrest|617733151423463423|
Brooklyn| 123| 123|Homecrest|617733151511019519|
Brooklyn| 123| 123|Homecrest|617733151505776639|
Brooklyn| 123| 123|Homecrest|617733151505252351|
Brooklyn| 123| 123|Homecrest|617733151504203775|
Brooklyn| 123| 123|Homecrest|617733151503679487|
Brooklyn| 123| 123|Homecrest|617733151503155199|
Brooklyn| 123| 123|Homecrest|617733151502630911|
Brooklyn| 123| 123|Homecrest|617733151502106623|
+--------+-----------+--------+---------+------------------+
only showing top 20 rows
6. Join the new left- and right-hand dataframes directly on the index.
[ ]:
joined_df = (
indexed_trips.alias("t")
.join(exploded_indexed_neighbourhoods.alias("n"), on="ix", how="inner"))
joined_df.count()
Out[25]: 4934937
Final notes
Mosaic provides support for Uber’s H3 spatial indexing library as a core part of the API, but we plan to add support for other index systems, including S2 and British National Grid in due course.