Spatial grid indexing
Spatial grid indexing is the process of mapping a geometry (or a point) to one or more cells (or cell ID) from the selected spatial grid.
The grid system can be specified by using the spark configuration spark.databricks.labs.mosaic.index.system before enabling Mosaic.
- The valid values are:
H3 - Good all-rounder for any location on earth
BNG - Local grid system Great Britain (EPSG:27700)
- CUSTOM(minX,maxX,minY,maxY,splits,rootCellSizeX,rootCellSizeY) - Can be used with any local or global CRS
minX,`maxX`,`minY`,`maxY` can be positive or negative integers defining the grid bounds
splits defines how many splits are applied to each cell for an increase in resolution step (usually 2 or 10)
rootCellSizeX,`rootCellSizeY` define the size of the cells on resolution 0
Example
spark.conf.set("spark.databricks.labs.mosaic.index.system", "H3") # Default
# spark.conf.set("spark.databricks.labs.mosaic.index.system", "BNG")
# spark.conf.set("spark.databricks.labs.mosaic.index.system", "CUSTOM(-180,180,-90,90,2,30,30)")
import mosaic as mos
mos.enable_mosaic(spark, dbutils)
grid_longlatascellid
- grid_longlatascellid(lon, lat, resolution)
Returns the resolution grid index associated with the input lon and lat coordinates.
- Parameters:
lon (Column: DoubleType) – Longitude
lat (Column: DoubleType) – Latitude
resolution (Column: Integer) – Index resolution
- Return type:
Column: LongType
- Example:
df = spark.createDataFrame([{'lon': 30., 'lat': 10.}])
df.select(grid_longlatascellid('lon', 'lat', lit(10))).show(1, False)
+----------------------------------+
|grid_longlatascellid(lon, lat, 10)|
+----------------------------------+
| 623385352048508927|
+----------------------------------+
val df = List((30.0, 10.0)).toDF("lon", "lat")
df.select(grid_longlatascellid(col("lon"), col("lat"), lit(10))).show()
+----------------------------------+
|grid_longlatascellid(lon, lat, 10)|
+----------------------------------+
| 623385352048508927|
+----------------------------------+
SELECT grid_longlatascellid(30d, 10d, 10)
+----------------------------------+
|grid_longlatascellid(lon, lat, 10)|
+----------------------------------+
| 623385352048508927|
+----------------------------------+
df <- createDataFrame(data.frame(lon = 30.0, lat = 10.0))
showDF(select(df, grid_longlatascellid(column("lon"), column("lat"), lit(10L))), truncate=F)
+----------------------------------+
|grid_longlatascellid(lon, lat, 10)|
+----------------------------------+
| 623385352048508927|
+----------------------------------+
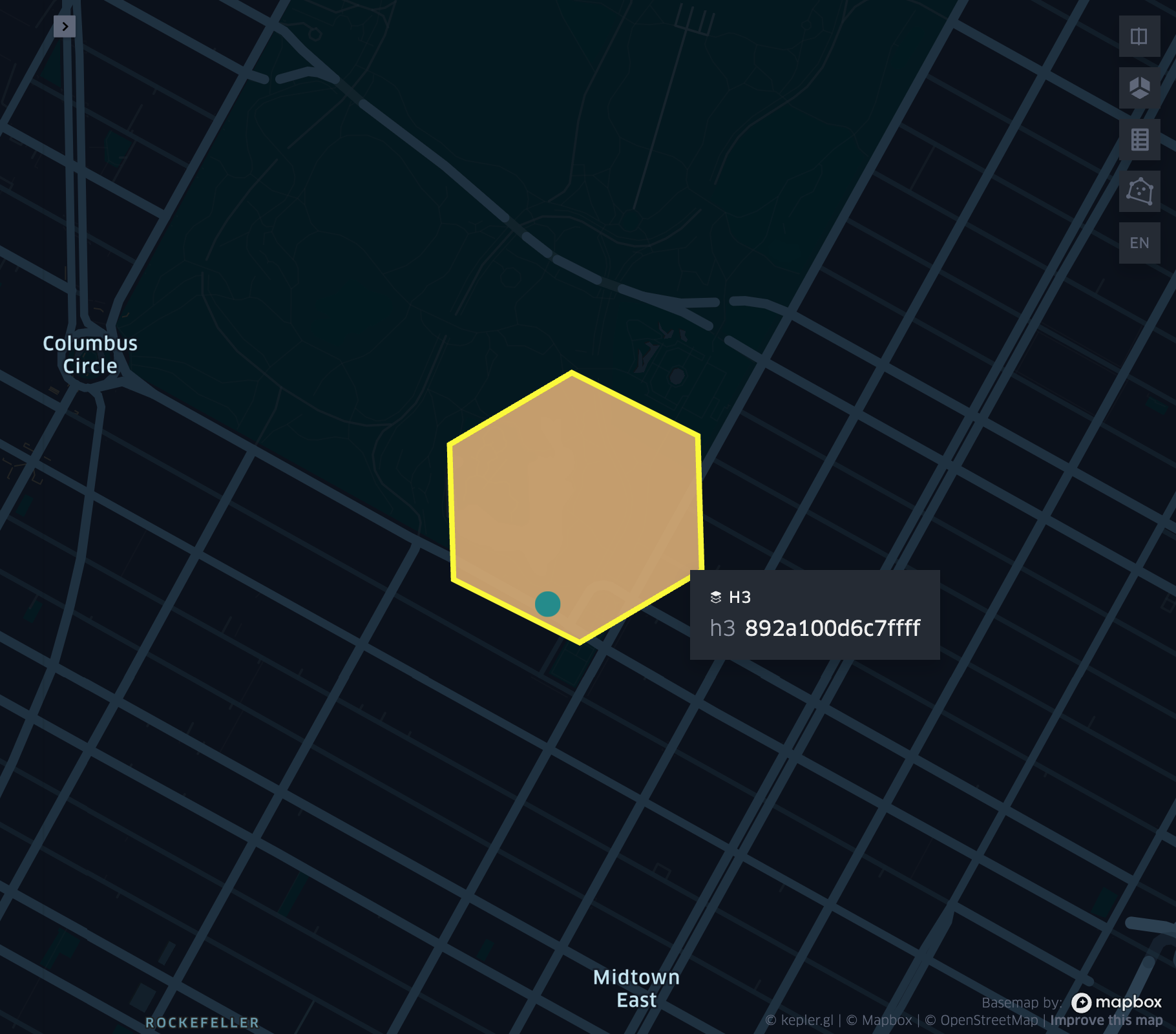
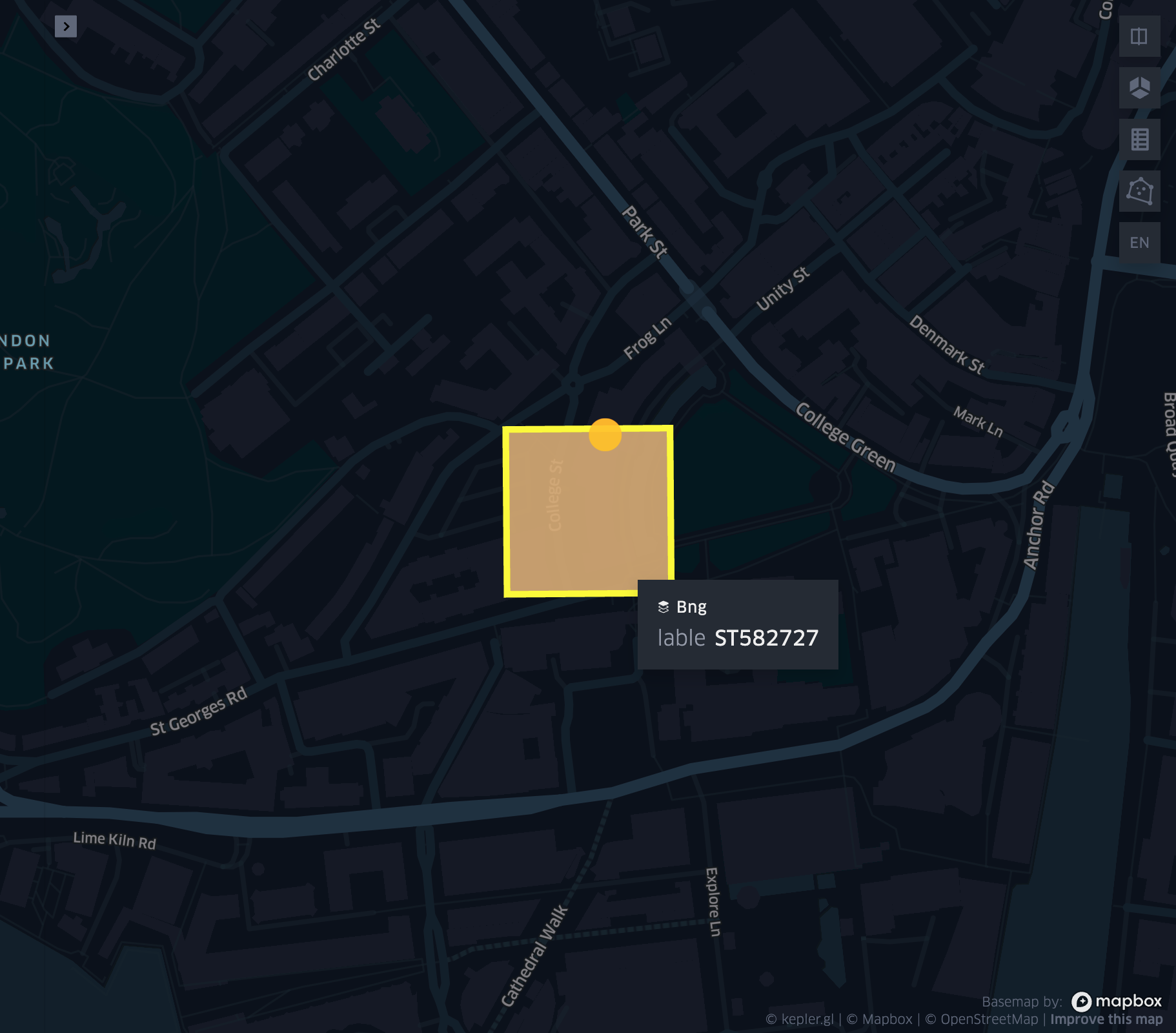
grid_pointascellid
- grid_pointascellid(geometry, resolution)
Returns the resolution grid index associated with the input point geometry geometry.
- Parameters:
geometry (Column) – Geometry
resolution (Column: Integer) – Index resolution
- Return type:
Column: LongType
- Example:
df = spark.createDataFrame([{'lon': 30., 'lat': 10.}])
df.select(grid_pointascellid(st_point('lon', 'lat'), lit(10))).show(1, False)
+------------------------------------------+
|grid_pointascellid(st_point(lon, lat), 10)|
+------------------------------------------+
|623385352048508927 |
+------------------------------------------+
val df = List((30.0, 10.0)).toDF("lon", "lat")
df.select(grid_pointascellid(st_point(col("lon"), col("lat")), lit(10))).show()
+------------------------------------------+
|grid_pointascellid(st_point(lon, lat), 10)|
+------------------------------------------+
|623385352048508927 |
+------------------------------------------+
SELECT grid_pointascellid(st_point(30d, 10d), 10)
+------------------------------------------+
|grid_pointascellid(st_point(lon, lat), 10)|
+------------------------------------------+
|623385352048508927 |
+------------------------------------------+
df <- createDataFrame(data.frame(lon = 30.0, lat = 10.0))
showDF(select(df, grid_pointascellid(st_point(column("lon"), column("lat")), lit(10L))), truncate=F)
+------------------------------------------+
|grid_pointascellid(st_point(lon, lat), 10)|
+------------------------------------------+
|623385352048508927 |
+------------------------------------------+
grid_polyfill
- grid_polyfill(geometry, resolution)
Returns the set of grid indices of which centroid is contained in the input geometry at resolution.
When using H3 <https://h3geo.org/> index system, this is equivalent to the H3 polyfill <https://h3geo.org/docs/api/regions/#polyfill> method
- Parameters:
geometry (Column) – Geometry
resolution (Column: Integer) – Index resolution
- Return type:
Column: ArrayType[LongType]
- Example:
df = spark.createDataFrame([{
'wkt': 'MULTIPOLYGON (((30 20, 45 40, 10 40, 30 20)), ((15 5, 40 10, 10 20, 5 10, 15 5)))'
}])
df.select(grid_polyfill('wkt', lit(0))).show(1, False)
+------------------------------------------------------------+
|grid_polyfill(wkt, 0) |
+------------------------------------------------------------+
|[577586652210266111, 578360708396220415, 577269992861466623]|
+------------------------------------------------------------+
val df = List(("MULTIPOLYGON (((30 20, 45 40, 10 40, 30 20)), ((15 5, 40 10, 10 20, 5 10, 15 5)))")).toDF("wkt")
df.select(grid_polyfill(col("wkt"), lit(0))).show(false)
+------------------------------------------------------------+
|grid_polyfill(wkt, 0) |
+------------------------------------------------------------+
|[577586652210266111, 578360708396220415, 577269992861466623]|
+------------------------------------------------------------+
SELECT grid_polyfill("MULTIPOLYGON (((30 20, 45 40, 10 40, 30 20)), ((15 5, 40 10, 10 20, 5 10, 15 5)))", 0)
+------------------------------------------------------------+
|grid_polyfill(wkt, 0) |
+------------------------------------------------------------+
|[577586652210266111, 578360708396220415, 577269992861466623]|
+------------------------------------------------------------+
df <- createDataFrame(data.frame(wkt = "MULTIPOLYGON (((30 20, 45 40, 10 40, 30 20)), ((15 5, 40 10, 10 20, 5 10, 15 5)))"))
showDF(select(df, grid_polyfill(column("wkt"), lit(0L))), truncate=F)
+------------------------------------------------------------+
|grid_polyfill(wkt, 0) |
+------------------------------------------------------------+
|[577586652210266111, 578360708396220415, 577269992861466623]|
+------------------------------------------------------------+
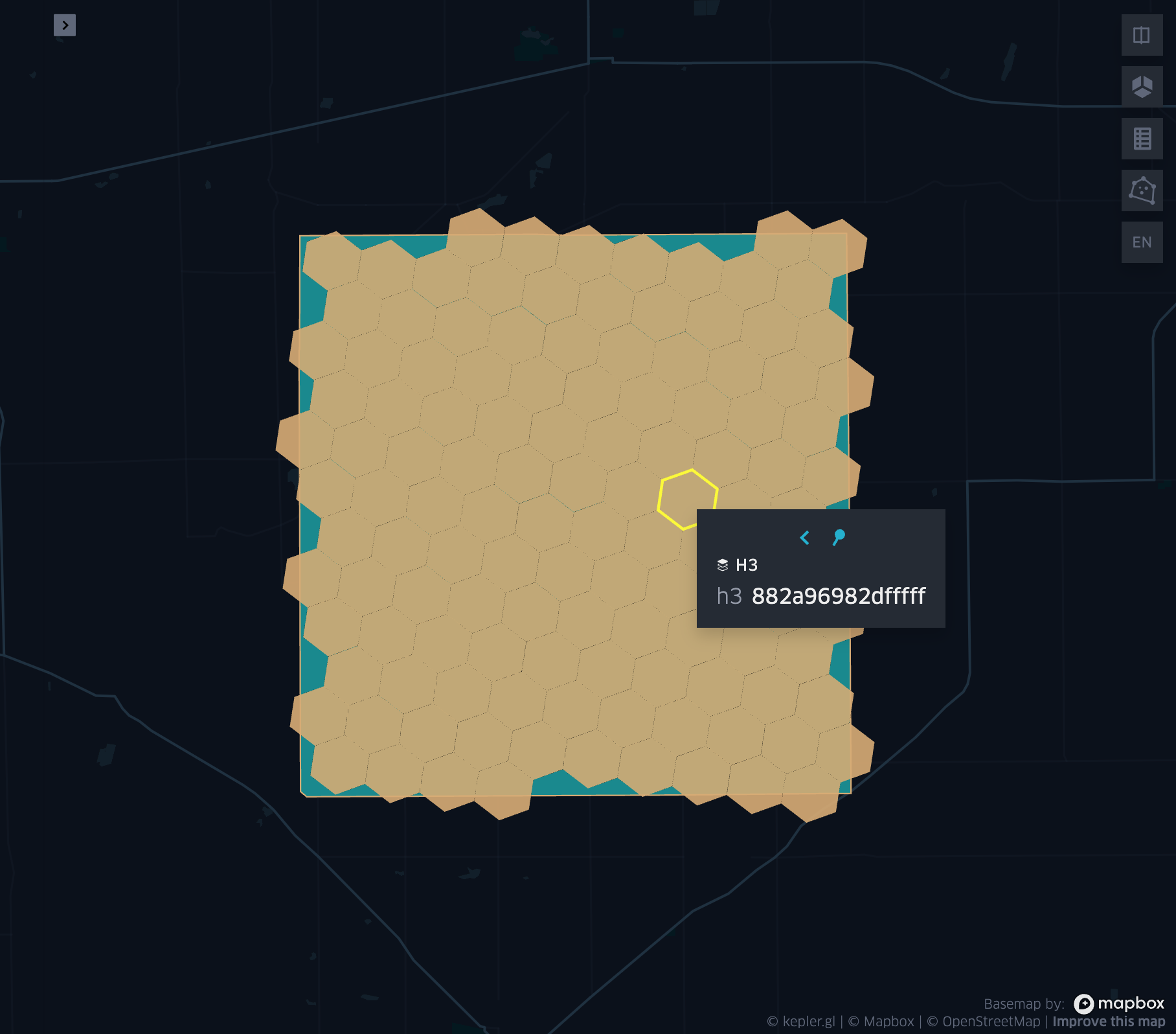
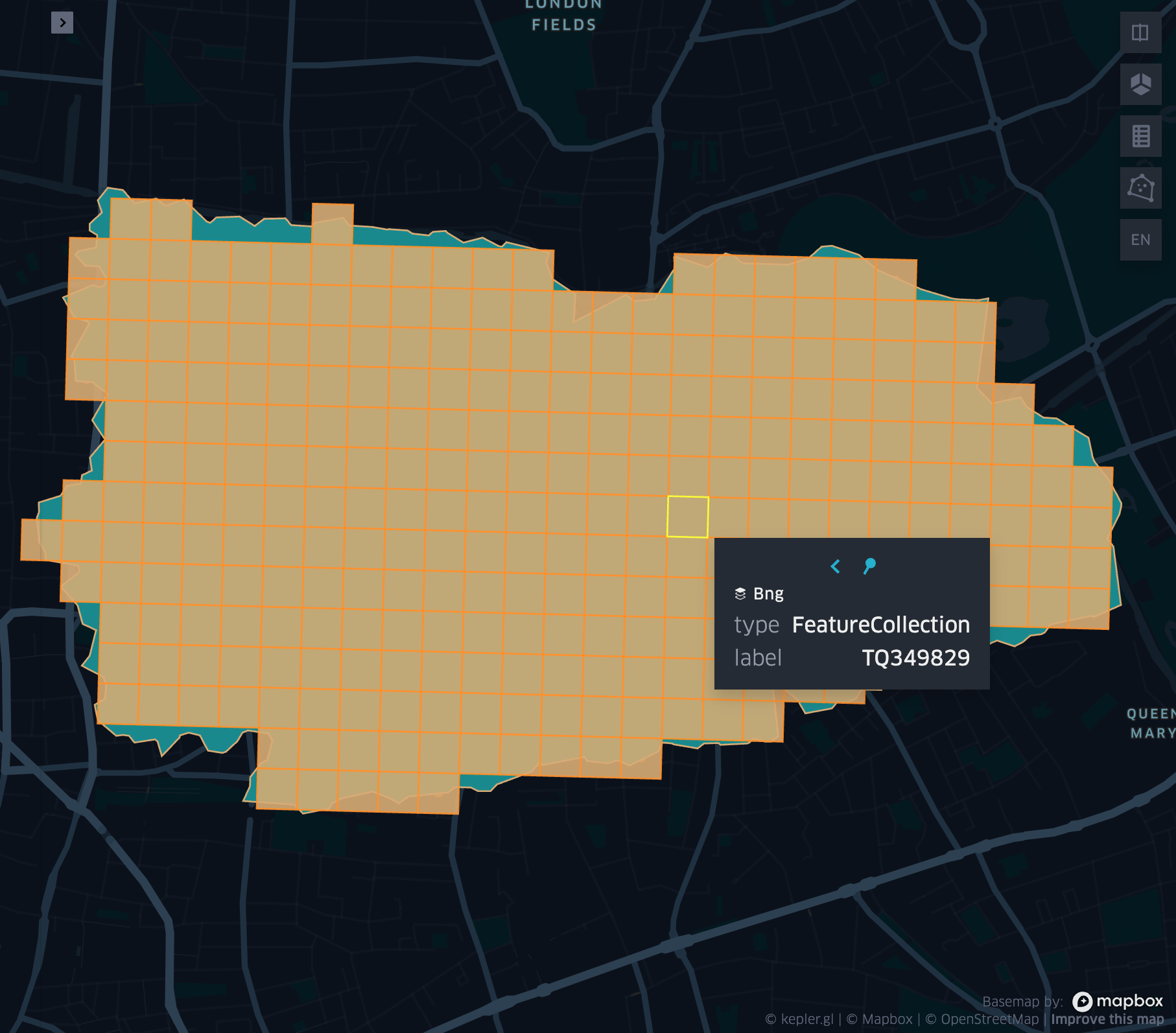
grid_boundaryaswkb
- grid_boundaryaswkb(cellid)
Returns the boundary of the grid cell as a WKB.
- Parameters:
cellid (Column: Union(LongType, StringType)) – Grid cell id
- Example:
df = spark.createDataFrame([{'cellid': 613177664827555839}])
df.select(grid_boundaryaswkb("cellid").show(1, False)
+--------------------------+
|grid_boundaryaswkb(cellid)|
+--------------------------+
|[01 03 00 00 00 00 00 00..|
+--------------------------+
val df = List((613177664827555839)).toDF("cellid")
df.select(grid_boundaryaswkb(col("cellid")).show()
+--------------------------+
|grid_boundaryaswkb(cellid)|
+--------------------------+
|[01 03 00 00 00 00 00 00..|
+--------------------------+
SELECT grid_boundaryaswkb(613177664827555839)
+--------------------------+
|grid_boundaryaswkb(cellid)|
+--------------------------+
|[01 03 00 00 00 00 00 00..|
+--------------------------+
df <- createDataFrame(data.frame(cellid = 613177664827555839))
showDF(select(df, grid_boundaryaswkb(column("cellid")), truncate=F)
+--------------------------+
|grid_boundaryaswkb(cellid)|
+--------------------------+
|[01 03 00 00 00 00 00 00..|
+--------------------------+
grid_boundary
- grid_boundary(cellid, format)
Returns the boundary of the grid cell as a geometry in specified format.
- Parameters:
cellid (Column: Union(LongType, StringType)) – Grid cell id
format (Column: StringType) – Geometry format
- Example:
df = spark.createDataFrame([{'cellid': 613177664827555839}])
df.select(grid_boundary("cellid", "WKT").show(1, False)
+--------------------------+
|grid_boundary(cellid, WKT)|
+--------------------------+
| "POLYGON (( ..."|
+--------------------------+
val df = List((613177664827555839)).toDF("cellid")
df.select(grid_boundary(col("cellid"), lit("WKT").show()
+--------------------------+
|grid_boundary(cellid, WKT)|
+--------------------------+
| "POLYGON (( ..."|
+--------------------------+
SELECT grid_boundary(613177664827555839, "WKT")
+--------------------------+
|grid_boundary(cellid, WKT)|
+--------------------------+
| "POLYGON (( ..."|
+--------------------------+
df <- createDataFrame(data.frame(cellid = 613177664827555839))
showDF(select(df, grid_boundary(column("cellid"), lit("WKT")), truncate=F)
+--------------------------+
|grid_boundary(cellid, WKT)|
+--------------------------+
| "POLYGON (( ..."|
+--------------------------+
grid_tessellate
- grid_tessellate(geometry, resolution, keep_core_geometries)
Cuts the original geometry into several pieces along the grid index borders at the specified resolution.
Returns an array of Mosaic chips covering the input geometry at resolution.
A Mosaic chip is a struct type composed of:
is_core: Identifies if the chip is fully contained within the geometry: Boolean
index_id: Index ID of the configured spatial indexing (default H3): Integer
wkb: Geometry in WKB format equal to the intersection of the index shape and the original geometry: Binary
In contrast to grid_tessellateexplode, grid_tessellate does not explode the list of shapes.
In contrast to grid_polyfill, grid_tessellate fully covers the original geometry even if the index centroid falls outside of the original geometry. This makes it suitable to index lines as well.
- Parameters:
geometry (Column) – Geometry
resolution (Column: Integer) – Index resolution
keep_core_geometries (Column: Boolean) – Whether to keep the core geometries or set them to null
- Return type:
Column: ArrayType[MosaicType]
- Example:
df = spark.createDataFrame([{'wkt': 'MULTIPOLYGON (((30 20, 45 40, 10 40, 30 20)), ((15 5, 40 10, 10 20, 5 10, 15 5)))'}])
df.select(grid_tessellate('wkt', lit(0))).printSchema()
root
|-- grid_tessellate(wkt, 0): mosaic (nullable = true)
| |-- chips: array (nullable = true)
| | |-- element: mosaic_chip (containsNull = true)
| | | |-- is_core: boolean (nullable = true)
| | | |-- index_id: long (nullable = true)
| | | |-- wkb: binary (nullable = true)
df.select(grid_tessellate('wkt', lit(0))).show()
+-----------------------+
|grid_tessellate(wkt, 0)|
+-----------------------+
| {[{false, 5774810...|
+-----------------------+
val df = List(("MULTIPOLYGON (((30 20, 45 40, 10 40, 30 20)), ((15 5, 40 10, 10 20, 5 10, 15 5)))")).toDF("wkt")
df.select(grid_tessellate(col("wkt"), lit(0))).printSchema
root
|-- grid_tessellate(wkt, 0): mosaic (nullable = true)
| |-- chips: array (nullable = true)
| | |-- element: mosaic_chip (containsNull = true)
| | | |-- is_core: boolean (nullable = true)
| | | |-- index_id: long (nullable = true)
| | | |-- wkb: binary (nullable = true)
df.select(grid_tessellate(col("wkt"), lit(0))).show()
+-----------------------+
|grid_tessellate(wkt, 0)|
+-----------------------+
| {[{false, 5774810...|
+-----------------------+
SELECT grid_tessellate("MULTIPOLYGON (((30 20, 45 40, 10 40, 30 20)), ((15 5, 40 10, 10 20, 5 10, 15 5)))", 0)
+-----------------------+
|grid_tessellate(wkt, 0)|
+-----------------------+
| {[{false, 5774810...|
+-----------------------+
df <- createDataFrame(data.frame(wkt = "MULTIPOLYGON (((30 20, 45 40, 10 40, 30 20)), ((15 5, 40 10, 10 20, 5 10, 15 5)))"))
schema(select(df, grid_tessellate(column("wkt"), lit(0L))))
root
|-- grid_tessellate(wkt, 0): mosaic (nullable = true)
| |-- chips: array (nullable = true)
| | |-- element: mosaic_chip (containsNull = true)
| | | |-- is_core: boolean (nullable = true)
| | | |-- index_id: long (nullable = true)
| | | |-- wkb: binary (nullable = true)
showDF(select(df, grid_tessellate(column("wkt"), lit(0L))))
+-----------------------+
|grid_tessellate(wkt, 0)|
+-----------------------+
| {[{false, 5774810...|
+-----------------------+
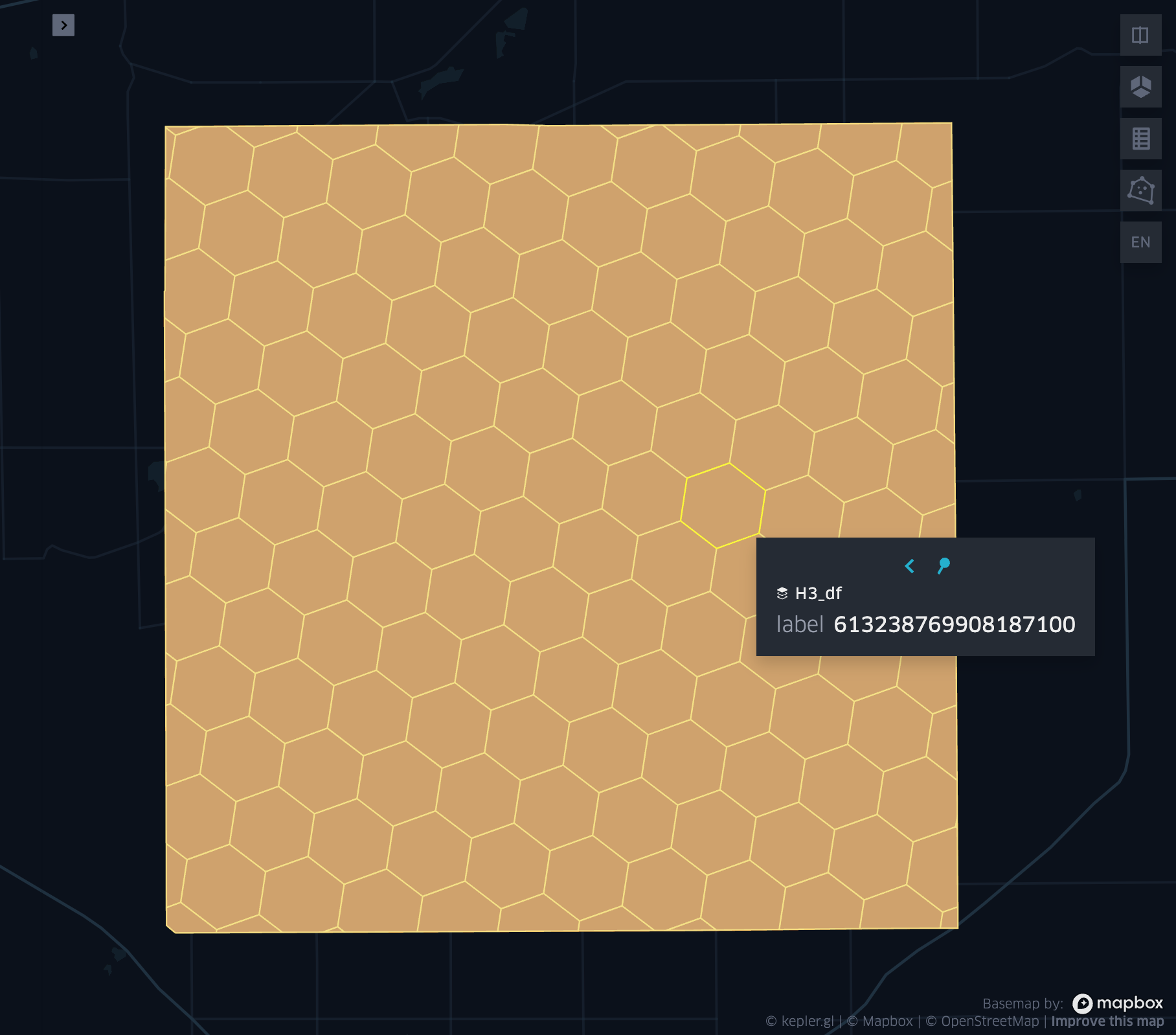
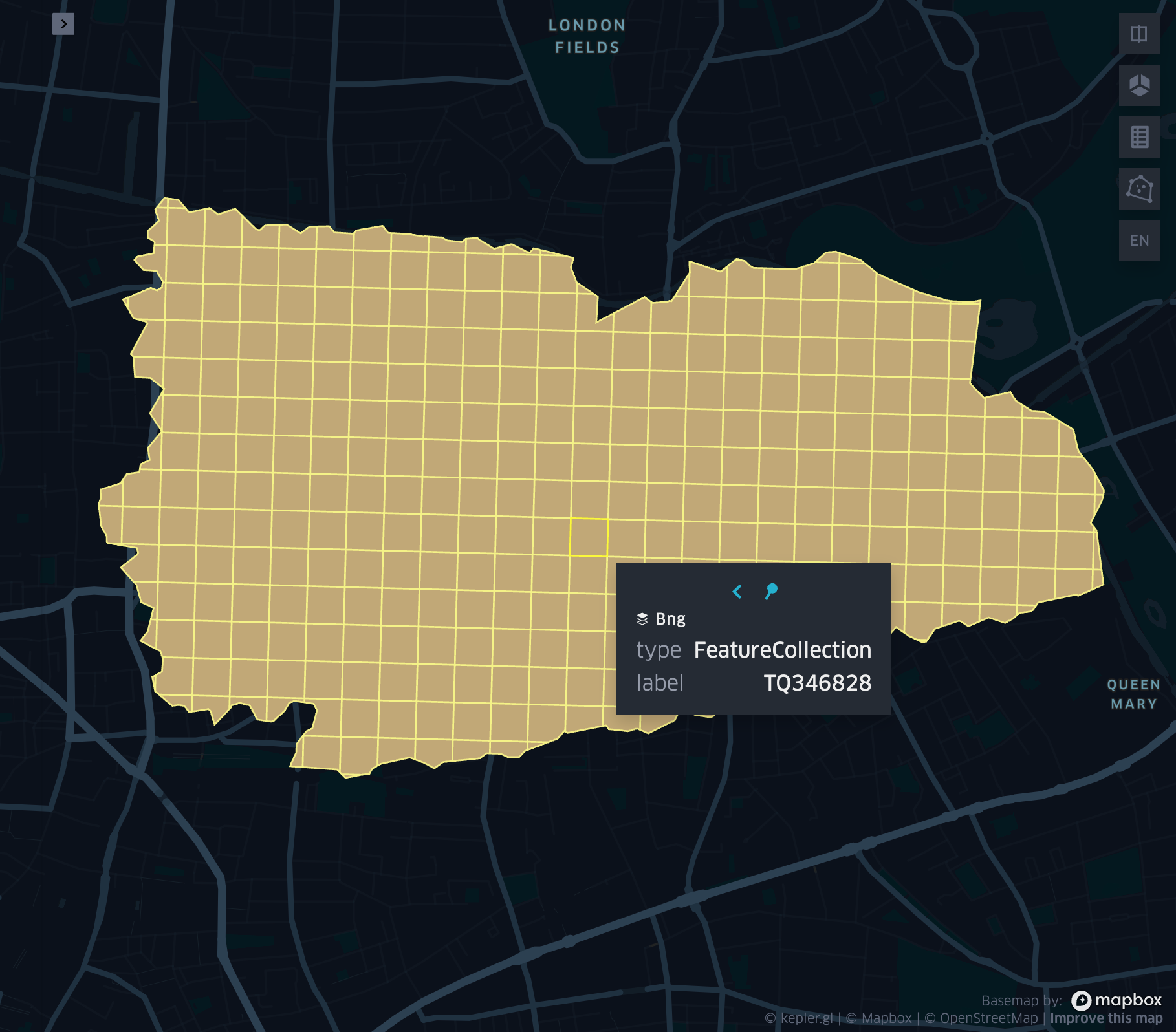
grid_tessellateexplode
- grid_tessellateexplode(geometry, resolution, keep_core_geometries)
Cuts the original geometry into several pieces along the grid index borders at the specified resolution.
Returns the set of Mosaic chips covering the input geometry at resolution.
A Mosaic chip is a struct type composed of:
is_core: Identifies if the chip is fully contained within the geometry: Boolean
index_id: Index ID of the configured spatial indexing (default H3): Integer
wkb: Geometry in WKB format equal to the intersection of the index shape and the original geometry: Binary
In contrast to grid_tessellate, grid_tessellateexplode generates one result row per chip.
In contrast to grid_polyfill, grid_tessellateexplode fully covers the original geometry even if the index centroid falls outside of the original geometry. This makes it suitable to index lines as well.
- Parameters:
geometry (Column) – Geometry
resolution (Column: Integer) – Index resolution
keep_core_geometries (Column: Boolean) – Whether to keep the core geometries or set them to null
- Return type:
Column: MosaicType
- Example:
df = spark.createDataFrame([{'wkt': 'MULTIPOLYGON (((30 20, 45 40, 10 40, 30 20)), ((15 5, 40 10, 10 20, 5 10, 15 5)))'}])
df.select(grid_tessellateexplode('wkt', lit(0))).show()
+-----------------------------------------------+
|is_core| index_id| wkb|
+-------+------------------+--------------------+
| false|577481099093999615|[01 03 00 00 00 0...|
| false|578044049047420927|[01 03 00 00 00 0...|
| false|578782920861286399|[01 03 00 00 00 0...|
| false|577023702256844799|[01 03 00 00 00 0...|
| false|577938495931154431|[01 03 00 00 00 0...|
| false|577586652210266111|[01 06 00 00 00 0...|
| false|577269992861466623|[01 03 00 00 00 0...|
| false|578360708396220415|[01 03 00 00 00 0...|
+-------+------------------+--------------------+
val df = List(("MULTIPOLYGON (((30 20, 45 40, 10 40, 30 20)), ((15 5, 40 10, 10 20, 5 10, 15 5)))")).toDF("wkt")
df.select(grid_tessellateexplode(col("wkt"), lit(0))).show()
+-----------------------------------------------+
|is_core| index_id| wkb|
+-------+------------------+--------------------+
| false|577481099093999615|[01 03 00 00 00 0...|
| false|578044049047420927|[01 03 00 00 00 0...|
| false|578782920861286399|[01 03 00 00 00 0...|
| false|577023702256844799|[01 03 00 00 00 0...|
| false|577938495931154431|[01 03 00 00 00 0...|
| false|577586652210266111|[01 06 00 00 00 0...|
| false|577269992861466623|[01 03 00 00 00 0...|
| false|578360708396220415|[01 03 00 00 00 0...|
+-------+------------------+--------------------+
SELECT grid_tessellateexplode("MULTIPOLYGON (((30 20, 45 40, 10 40, 30 20)), ((15 5, 40 10, 10 20, 5 10, 15 5)))", 0)
+-----------------------------------------------+
|is_core| index_id| wkb|
+-------+------------------+--------------------+
| false|577481099093999615|[01 03 00 00 00 0...|
| false|578044049047420927|[01 03 00 00 00 0...|
| false|578782920861286399|[01 03 00 00 00 0...|
| false|577023702256844799|[01 03 00 00 00 0...|
| false|577938495931154431|[01 03 00 00 00 0...|
| false|577586652210266111|[01 06 00 00 00 0...|
| false|577269992861466623|[01 03 00 00 00 0...|
| false|578360708396220415|[01 03 00 00 00 0...|
+-------+------------------+--------------------+
df <- createDataFrame(data.frame(wkt = 'MULTIPOLYGON (((30 20, 45 40, 10 40, 30 20)), ((15 5, 40 10, 10 20, 5 10, 15 5)))'))
showDF(select(df, grid_tessellateexplode(column("wkt"), lit(0L))))
+-----------------------------------------------+
|is_core| index_id| wkb|
+-------+------------------+--------------------+
| false|577481099093999615|[01 03 00 00 00 0...|
| false|578044049047420927|[01 03 00 00 00 0...|
| false|578782920861286399|[01 03 00 00 00 0...|
| false|577023702256844799|[01 03 00 00 00 0...|
| false|577938495931154431|[01 03 00 00 00 0...|
| false|577586652210266111|[01 06 00 00 00 0...|
| false|577269992861466623|[01 03 00 00 00 0...|
| false|578360708396220415|[01 03 00 00 00 0...|
+-------+------------------+--------------------+
grid_cellarea
- grid_cellarea(cellid)
Returns the area of a given cell in km^2.
- Parameters:
cellid (Column: Long) – Grid cell ID
- Return type:
Column: DoubleType
- Example:
df = spark.createDataFrame([{'grid_cellid': 613177664827555839}])
df.withColumn(grid_cellarea('grid_cellid').alias("area")).show()
+------------------------------------+
| grid_cellid| area|
+--------------------+---------------+
| 613177664827555839| 0.78595419|
+--------------------+---------------+
val df = List((613177664827555839)).toDF("grid_cellid")
df.select(grid_cellarea('grid_cellid').alias("area")).show()
+------------------------------------+
| grid_cellid| area|
+--------------------+---------------+
| 613177664827555839| 0.78595419|
+--------------------+---------------+
SELECT grid_cellarea(613177664827555839)
+------------------------------------+
| grid_cellid| area|
+--------------------+---------------+
| 613177664827555839| 0.78595419|
+--------------------+---------------+
df <- createDataFrame(data.frame(grid_cellid = 613177664827555839))
showDF(select(df, grid_cellarea(column("grid_cellid"))))
+------------------------------------+
| grid_cellid| area|
+--------------------+---------------+
| 613177664827555839| 0.78595419|
+--------------------+---------------+
grid_cellkring
- grid_cellkring(cellid, k)
Returns the k-ring of a given cell.
- Parameters:
cellid (Column: Long) – Grid cell ID
k (Column: Integer) – K-ring size
- Return type:
Column: ArrayType(Long)
- Example:
df = spark.createDataFrame([{'grid_cellid': 613177664827555839}])
df.select(grid_cellkring('grid_cellid', lit(2)).alias("kring")).show()
+-------------------------------------------------------------------+
| grid_cellid| kring|
+--------------------+----------------------------------------------+
| 613177664827555839|[613177664827555839, 613177664825458687, ....]|
+--------------------+----------------------------------------------+
val df = List((613177664827555839)).toDF("grid_cellid")
df.select(grid_cellkring('grid_cellid', lit(2)).alias("kring")).show()
+-------------------------------------------------------------------+
| grid_cellid| kring|
+--------------------+----------------------------------------------+
| 613177664827555839|[613177664827555839, 613177664825458687, ....]|
+--------------------+----------------------------------------------+
SELECT grid_cellkring(613177664827555839, 2)
+-------------------------------------------------------------------+
| grid_cellid| kring|
+--------------------+----------------------------------------------+
| 613177664827555839|[613177664827555839, 613177664825458687, ....]|
+--------------------+----------------------------------------------+
df <- createDataFrame(data.frame(grid_cellid = 613177664827555839))
showDF(select(df, grid_cellkring(column("grid_cellid"), lit(2L))))
+-------------------------------------------------------------------+
| grid_cellid| kring|
+--------------------+----------------------------------------------+
| 613177664827555839|[613177664827555839, 613177664825458687, ....]|
+--------------------+----------------------------------------------+
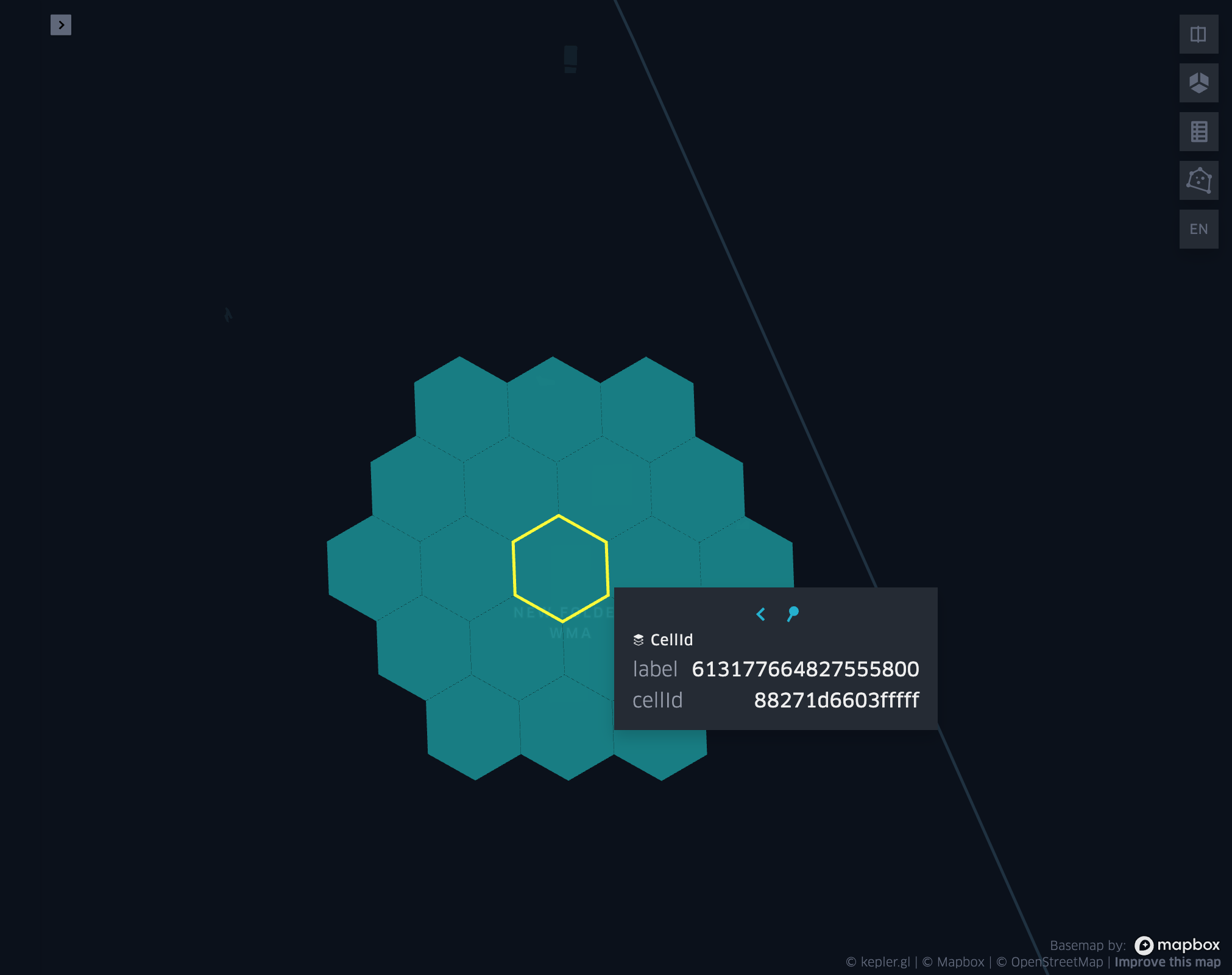
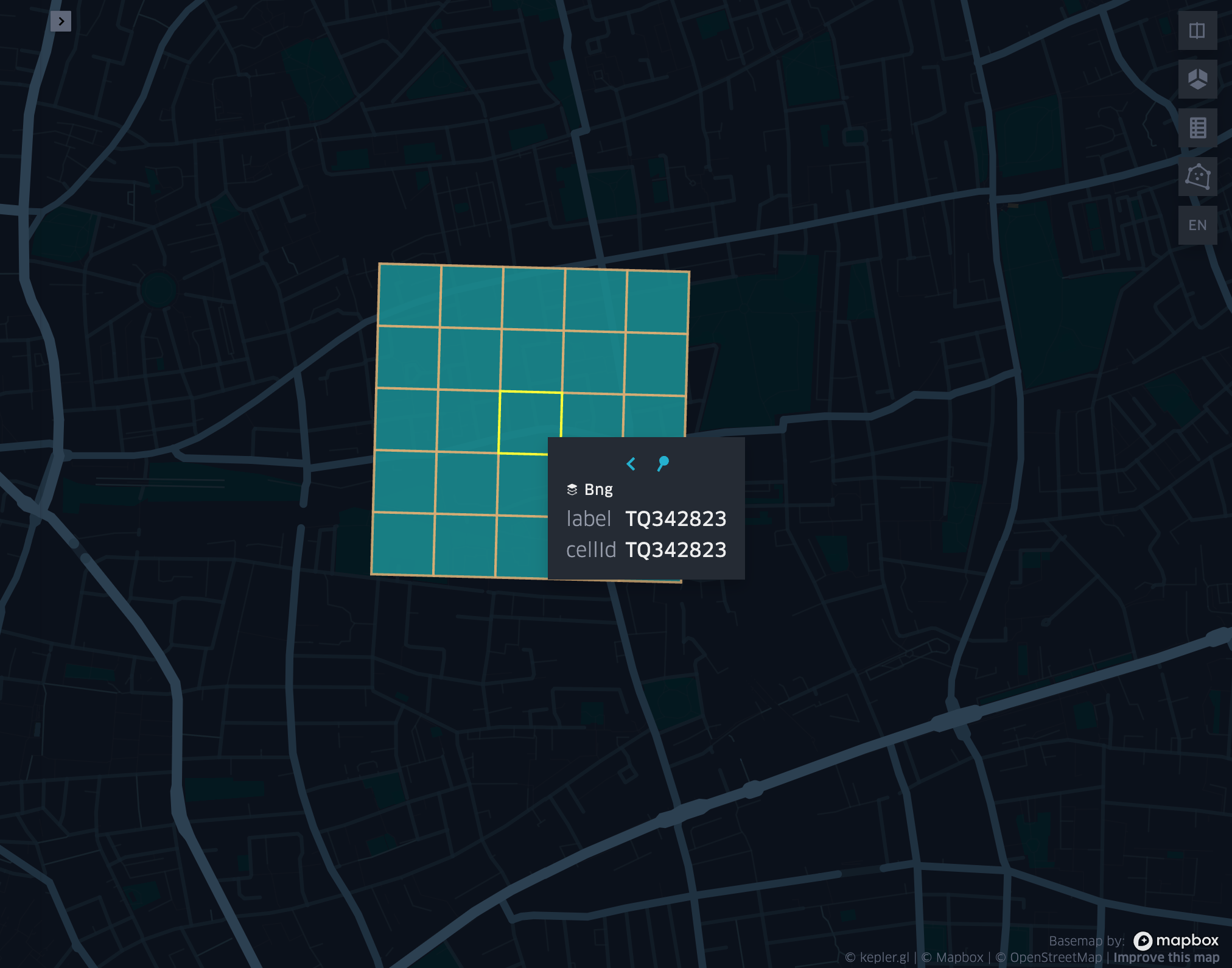
grid_cellkringexplode
- grid_cellkringexplode(cellid, k)
Returns the k-ring of a given cell exploded.
- Parameters:
cellid (Column: Long) – Grid cell ID
k (Column: Integer) – K-ring size
- Return type:
Column: Long
- Example:
df = spark.createDataFrame([{'grid_cellid': 613177664827555839}])
df.select(grid_cellkringexplode('grid_cellid', lit(2)).alias("kring")).show()
+------------------+
| kring|
+------------------+
|613177664827555839|
|613177664825458687|
|613177664831750143|
|613177664884178943|
| ...|
+------------------+
val df = List((613177664827555839)).toDF("grid_cellid")
df.select(grid_cellkringexplode('grid_cellid', lit(2)).alias("kring")).show()
+------------------+
| kring|
+------------------+
|613177664827555839|
|613177664825458687|
|613177664831750143|
|613177664884178943|
| ...|
+------------------+
SELECT grid_cellkringexplode(613177664827555839, 2)
+------------------+
| kring|
+------------------+
|613177664827555839|
|613177664825458687|
|613177664831750143|
|613177664884178943|
| ...|
+------------------+
df <- createDataFrame(data.frame(grid_cellid = 613177664827555839))
showDF(select(df, grid_cellkringexplode(column("grid_cellid"), lit(2L))))
+------------------+
| kring|
+------------------+
|613177664827555839|
|613177664825458687|
|613177664831750143|
|613177664884178943|
| ...|
+------------------+
grid_cell_intersection
- grid_cell_intersection(left_chip, right_chip)
Returns the chip representing the intersection of two chips based on the same grid cell
- Parameters:
left_chip (Column: ChipType(LongType)) – Chip
left_chip – Chip
- Return type:
Column: ChipType(LongType)
- Example:
df = spark.createDataFrame([{"chip": {"is_core": False, "index_id": 590418571381702655, "wkb": ...}})])
df.select(grid_cell_intersection("chip", "chip").alias("intersection")).show()
---------------------------------------------------------+
| intersection |
+--------------------------------------------------------+
|{is_core: false, index_id: 590418571381702655, wkb: ...}|
+--------------------------------------------------------+
val df = List((...)).toDF("chip")
df.select(grid_cell_intersection("chip", "chip").alias("intersection")).show()
---------------------------------------------------------+
| intersection |
+--------------------------------------------------------+
|{is_core: false, index_id: 590418571381702655, wkb: ...}|
+--------------------------------------------------------+
SELECT grid_cell_intersection({"is_core": False, "index_id": 590418571381702655, "wkb": ...})
---------------------------------------------------------+
| intersection |
+--------------------------------------------------------+
|{is_core: false, index_id: 590418571381702655, wkb: ...}|
+--------------------------------------------------------+
df <- createDataFrame(data.frame(...))
showDF(select(df, grid_cell_intersection(column("chip"))))
---------------------------------------------------------+
| intersection |
+--------------------------------------------------------+
|{is_core: false, index_id: 590418571381702655, wkb: ...}|
+--------------------------------------------------------+
grid_cell_union
- grid_cell_union(left_chip, right_chip)
Returns the chip representing the union of two chips based on the same grid cell
- Parameters:
left_chip (Column: ChipType(LongType)) – Chip
left_chip – Chip
- Return type:
Column: ChipType(LongType)
- Example:
df = spark.createDataFrame([{"chip": {"is_core": False, "index_id": 590418571381702655, "wkb": ...}})])
df.select(grid_cell_union("chip", "chip").alias("union")).show()
---------------------------------------------------------+
| union |
+--------------------------------------------------------+
|{is_core: false, index_id: 590418571381702655, wkb: ...}|
+--------------------------------------------------------+
val df = List((...)).toDF("chip")
df.select(grid_cell_union("chip", "chip").alias("union")).show()
---------------------------------------------------------+
| union |
+--------------------------------------------------------+
|{is_core: false, index_id: 590418571381702655, wkb: ...}|
+--------------------------------------------------------+
SELECT grid_cell_union({"is_core": False, "index_id": 590418571381702655, "wkb": ...})
---------------------------------------------------------+
| union |
+--------------------------------------------------------+
|{is_core: false, index_id: 590418571381702655, wkb: ...}|
+--------------------------------------------------------+
df <- createDataFrame(data.frame(...))
showDF(select(df, grid_cell_union(column("chip"))))
---------------------------------------------------------+
| union |
+--------------------------------------------------------+
|{is_core: false, index_id: 590418571381702655, wkb: ...}|
+--------------------------------------------------------+
grid_cellkloop
- grid_cellkloop(cellid, k)
Returns the k loop (hollow ring) of a given cell.
- Parameters:
cellid (Column: Long) – Grid cell ID
k (Column: Integer) – K-loop size
- Return type:
Column: ArrayType(Long)
- Example:
df = spark.createDataFrame([{'grid_cellid': 613177664827555839}])
df.select(grid_cellkloop('grid_cellid', lit(2)).alias("kloop")).show()
+-------------------------------------------------------------------+
| grid_cellid| kloop|
+--------------------+----------------------------------------------+
| 613177664827555839|[613177664827555839, 613177664825458687, ....]|
+--------------------+----------------------------------------------+
val df = List((613177664827555839)).toDF("grid_cellid")
df.select(grid_cellkloop('grid_cellid', lit(2)).alias("kloop")).show()
+-------------------------------------------------------------------+
| grid_cellid| kloop|
+--------------------+----------------------------------------------+
| 613177664827555839|[613177664827555839, 613177664825458687, ....]|
+--------------------+----------------------------------------------+
SELECT grid_cellkloop(613177664827555839, 2)
+-------------------------------------------------------------------+
| grid_cellid| kloop|
+--------------------+----------------------------------------------+
| 613177664827555839|[613177664827555839, 613177664825458687, ....]|
+--------------------+----------------------------------------------+
df <- createDataFrame(data.frame(grid_cellid = 613177664827555839))
showDF(select(df, grid_cellkloop(column("grid_cellid"), lit(2L))))
+-------------------------------------------------------------------+
| grid_cellid| kloop|
+--------------------+----------------------------------------------+
| 613177664827555839|[613177664827555839, 613177664825458687, ....]|
+--------------------+----------------------------------------------+
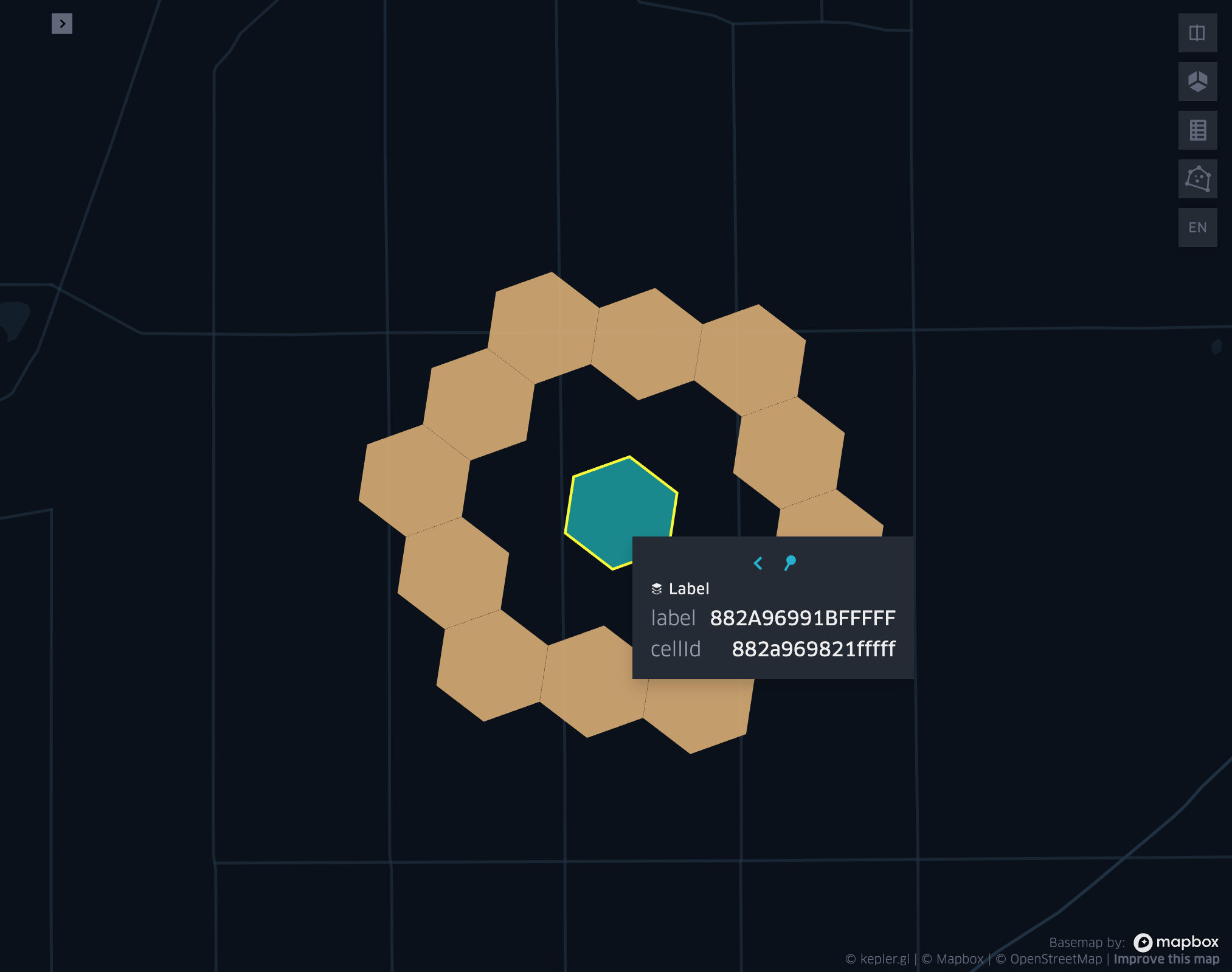
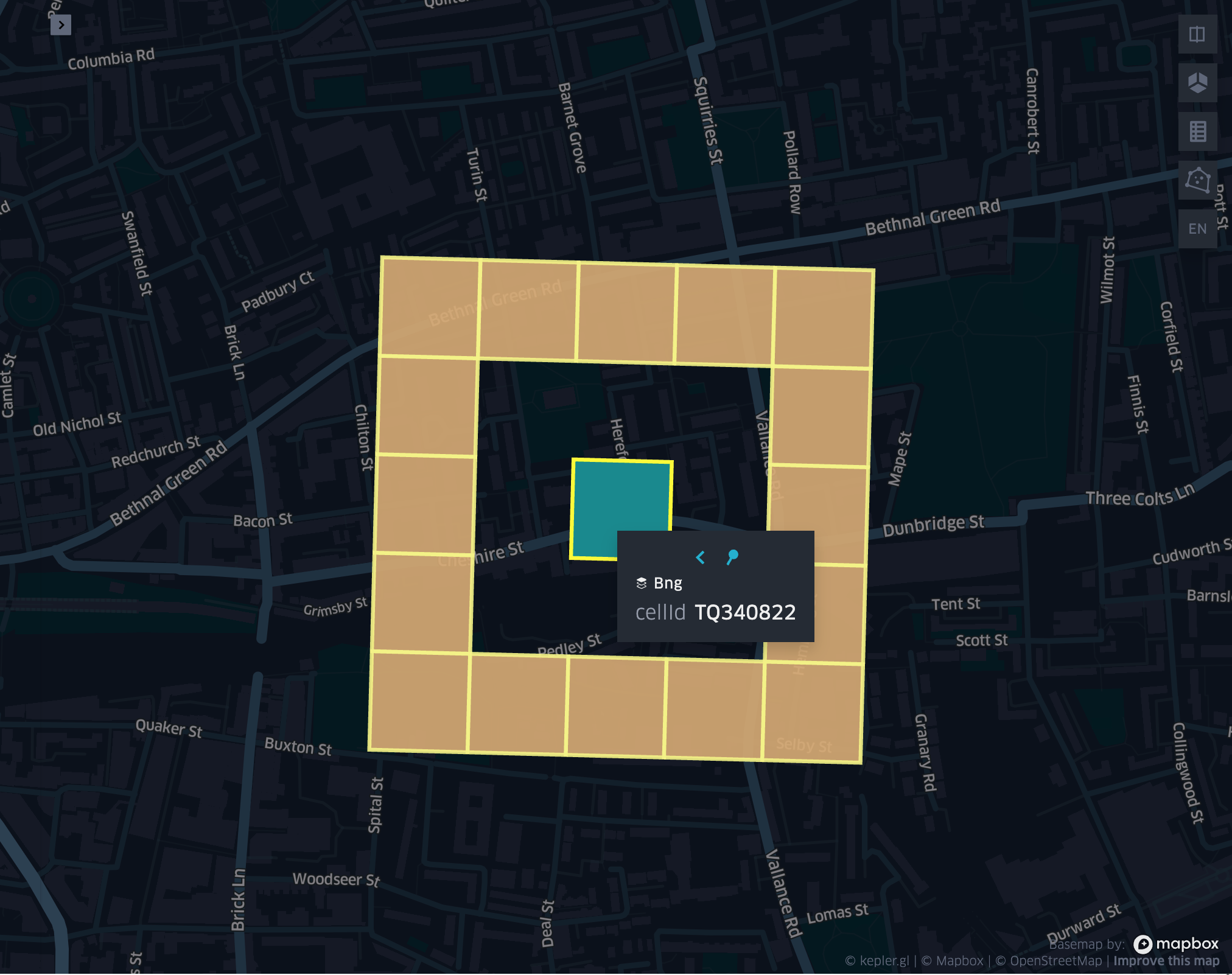
grid_cellkloopexplode
- grid_cellkloopexplode(cellid, k)
Returns the k loop (hollow ring) of a given cell exploded.
- Parameters:
cellid (Column: Long) – Grid cell ID
k (Column: Integer) – K-loop size
- Return type:
Column: Long
- Example:
df = spark.createDataFrame([{'grid_cellid': 613177664827555839}])
df.select(grid_cellkloopexplode('grid_cellid', lit(2)).alias("kloop")).show()
+------------------+
| kloop|
+------------------+
|613177664827555839|
|613177664825458687|
|613177664831750143|
|613177664884178943|
| ...|
+------------------+
val df = List((613177664827555839)).toDF("grid_cellid")
df.select(grid_cellkloopexplode('grid_cellid', lit(2)).alias("kloop")).show()
+------------------+
| kloop|
+------------------+
|613177664827555839|
|613177664825458687|
|613177664831750143|
|613177664884178943|
| ...|
+------------------+
SELECT grid_cellkloopexplode(613177664827555839, 2)
+------------------+
| kloop|
+------------------+
|613177664827555839|
|613177664825458687|
|613177664831750143|
|613177664884178943|
| ...|
+------------------+
df <- createDataFrame(data.frame(grid_cellid = 613177664827555839))
showDF(select(df, grid_cellkloopexplode(column("grid_cellid"), lit(2L))))
+------------------+
| kloop|
+------------------+
|613177664827555839|
|613177664825458687|
|613177664831750143|
|613177664884178943|
| ...|
+------------------+
grid_geometrykring
- grid_geometrykring(geometry, resolution, k)
Returns the k-ring of a given geometry respecting the boundary shape.
- Parameters:
geometry (Column) – Geometry to be used
resolution (Column: Integer) – Resolution of the index used to calculate the k-ring
k (Column: Integer) – K-ring size
- Return type:
Column: ArrayType(Long)
- Example:
df = spark.createDataFrame([{'geometry': "MULTIPOLYGON (((30 20, 45 40, 10 40, 30 20)), ((15 5, 40 10, 10 20, 5 10, 15 5)))"}])
df.select(grid_geometrykring('geometry', lit(8), lit(1)).alias("kring")).show()
+-------------------------------------------------------------------+
| geometry| kring|
+--------------------+----------------------------------------------+
| "MULTIPOLYGON(..."|[613177664827555839, 613177664825458687, ....]|
+--------------------+----------------------------------------------+
val df = List((613177664827555839)).toDF("geometry")
df.select(grid_geometrykring('geometry', lit(8), lit(1)).alias("kring")).show()
+-------------------------------------------------------------------+
| geometry| kring|
+--------------------+----------------------------------------------+
| "MULTIPOLYGON(..."|[613177664827555839, 613177664825458687, ....]|
+--------------------+----------------------------------------------+
SELECT grid_geometrykring('MULTIPOLYGON (((30 20, 45 40, 10 40, 30 20)), ((15 5, 40 10, 10 20, 5 10, 15 5)))', 8, 1)
+-------------------------------------------------------------------+
| geometry| kring|
+--------------------+----------------------------------------------+
| "MULTIPOLYGON(..."|[613177664827555839, 613177664825458687, ....]|
+--------------------+----------------------------------------------+
df <- createDataFrame(data.frame(geometry = 613177664827555839))
showDF(select(df, grid_geometrykring('geometry', lit(8L), lit(1L))))
+-------------------------------------------------------------------+
| geometry| kring|
+--------------------+----------------------------------------------+
| "MULTIPOLYGON(..."|[613177664827555839, 613177664825458687, ....]|
+--------------------+----------------------------------------------+
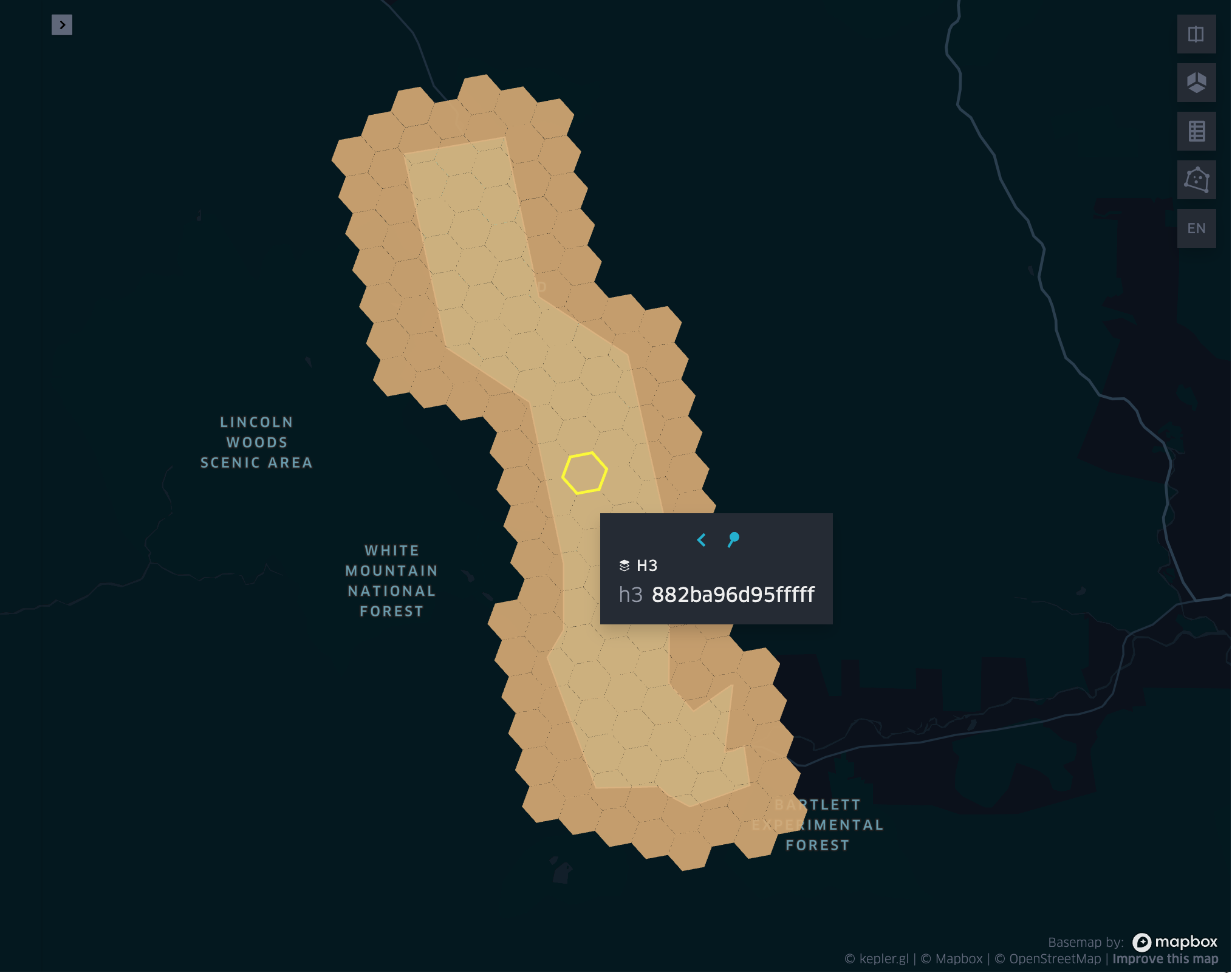
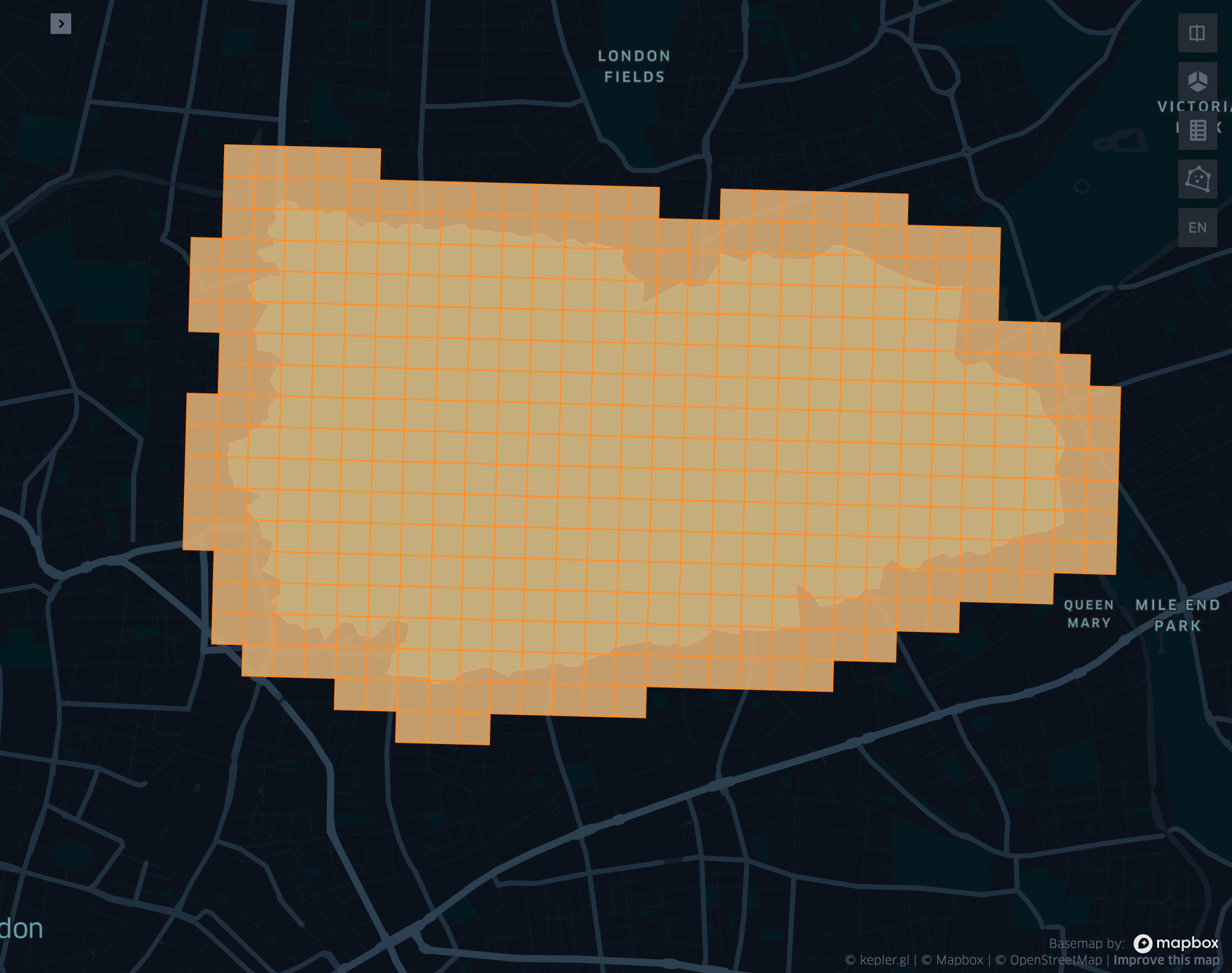
grid_geometrykringexplode
- grid_geometrykringexplode(geometry, resolution, k)
Returns the k-ring of a given geometry exploded.
- Parameters:
geometry (Column) – Geometry to be used
resolution (Column: Integer) – Resolution of the index used to calculate the k-ring
k (Column: Integer) – K-ring size
- Return type:
Column: Long
- Example:
df = spark.createDataFrame([{'geometry': "MULTIPOLYGON (((30 20, 45 40, 10 40, 30 20)), ((15 5, 40 10, 10 20, 5 10, 15 5)))"}])
df.select(grid_geometrykringexplode('geometry', lit(8), lit(2)).alias("kring")).show()
+------------------+
| kring|
+------------------+
|613177664827555839|
|613177664825458687|
|613177664831750143|
|613177664884178943|
| ...|
+------------------+
val df = List(("MULTIPOLYGON (((30 20, 45 40, 10 40, 30 20)), ((15 5, 40 10, 10 20, 5 10, 15 5)))")).toDF("geometry")
df.select(grid_geometrykringexplode('geometry', lit(8), lit(2)).alias("kring")).show()
+------------------+
| kring|
+------------------+
|613177664827555839|
|613177664825458687|
|613177664831750143|
|613177664884178943|
| ...|
+------------------+
SELECT grid_geometrykringexplode("MULTIPOLYGON (((30 20, 45 40, 10 40, 30 20)), ((15 5, 40 10, 10 20, 5 10, 15 5)))", 8, 2)
+------------------+
| kring|
+------------------+
|613177664827555839|
|613177664825458687|
|613177664831750143|
|613177664884178943|
| ...|
+------------------+
df <- createDataFrame(data.frame(geometry = "MULTIPOLYGON (((30 20, 45 40, 10 40, 30 20)), ((15 5, 40 10, 10 20, 5 10, 15 5)))"))
showDF(select(df, grid_cellkringexplode(column("geometry"), lit(8L), lit(2L))))
+------------------+
| kring|
+------------------+
|613177664827555839|
|613177664825458687|
|613177664831750143|
|613177664884178943|
| ...|
+------------------+
grid_geometrykloop
- grid_geometrykloop(geometry, resolution, k)
Returns the k-loop (hollow ring) of a given geometry.
- Parameters:
geometry (Column) – Geometry to be used
resolution (Column: Integer) – Resolution of the index used to calculate the k loop
k (Column: Integer) – K-Loop size
- Return type:
Column: ArrayType(Long)
- Example:
df = spark.createDataFrame([{'geometry': "MULTIPOLYGON (((30 20, 45 40, 10 40, 30 20)), ((15 5, 40 10, 10 20, 5 10, 15 5)))"}])
df.select(grid_geometrykloop('geometry', lit(2)).alias("kloop")).show()
+-------------------------------------------------------------------+
| geometry| kloop|
+--------------------+----------------------------------------------+
| MULTIPOLYGON ((...|[613177664827555839, 613177664825458687, ....]|
+--------------------+----------------------------------------------+
val df = List(("MULTIPOLYGON (((30 20, 45 40, 10 40, 30 20)), ((15 5, 40 10, 10 20, 5 10, 15 5)))")).toDF("geometry")
df.select(grid_cellkloop('geometry', lit(2)).alias("kloop")).show()
+-------------------------------------------------------------------+
| geometry| kloop|
+--------------------+----------------------------------------------+
| MULTIPOLYGON ((...|[613177664827555839, 613177664825458687, ....]|
+--------------------+----------------------------------------------+
SELECT grid_cellkloop("MULTIPOLYGON (((30 20, 45 40, 10 40, 30 20)), ((15 5, 40 10, 10 20, 5 10, 15 5)))", 2)
+-------------------------------------------------------------------+
| geometry| kloop|
+--------------------+----------------------------------------------+
| MULTIPOLYGON ((...|[613177664827555839, 613177664825458687, ....]|
+--------------------+----------------------------------------------+
df <- createDataFrame(data.frame(geometry = "MULTIPOLYGON (((30 20, 45 40, 10 40, 30 20)), ((15 5, 40 10, 10 20, 5 10, 15 5)))"))
showDF(select(df, grid_cellkloop(column("geometry"), lit(2L))))
+-------------------------------------------------------------------+
| geometry| kloop|
+--------------------+----------------------------------------------+
| MULTIPOLYGON ((...|[613177664827555839, 613177664825458687, ....]|
+--------------------+----------------------------------------------+
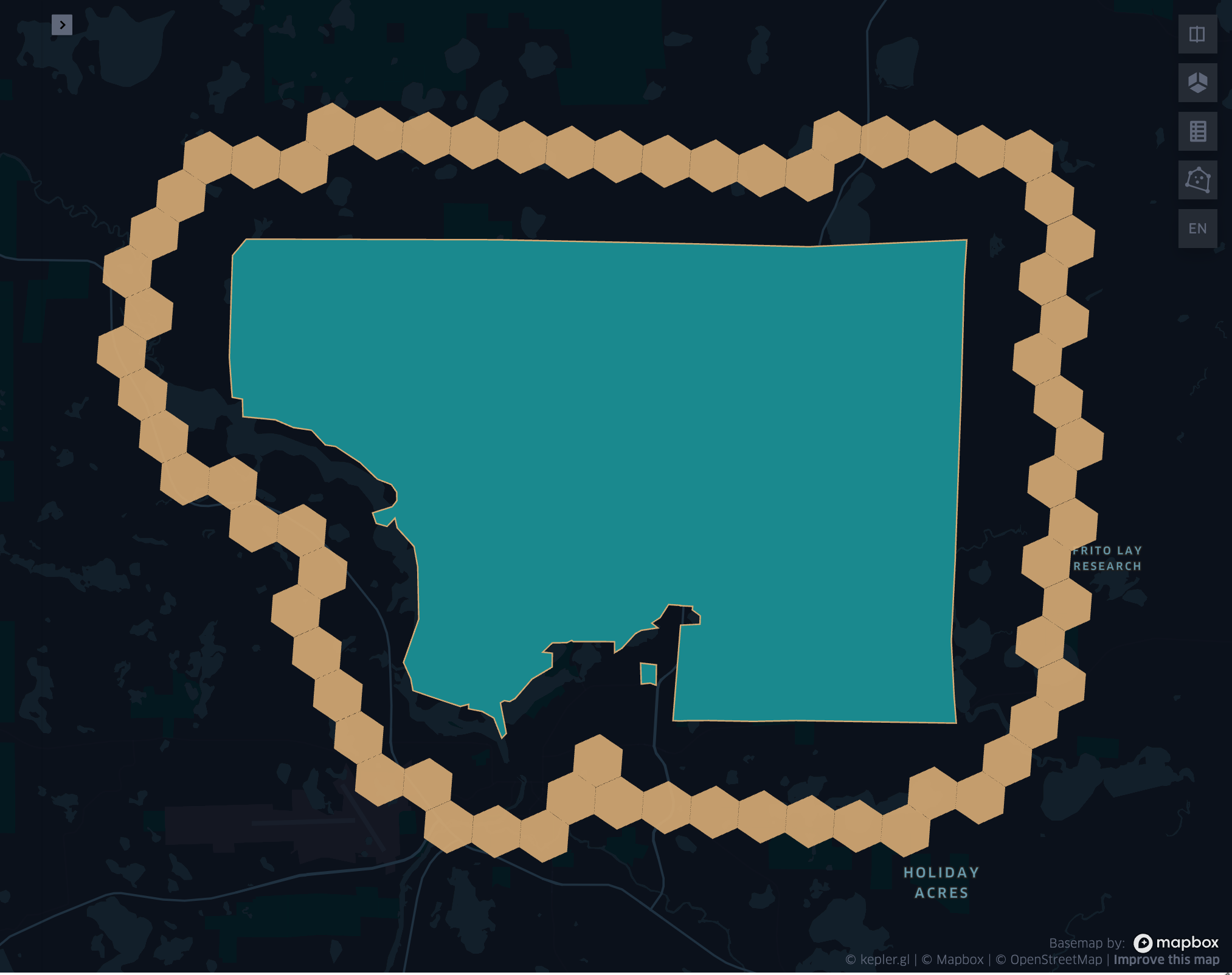
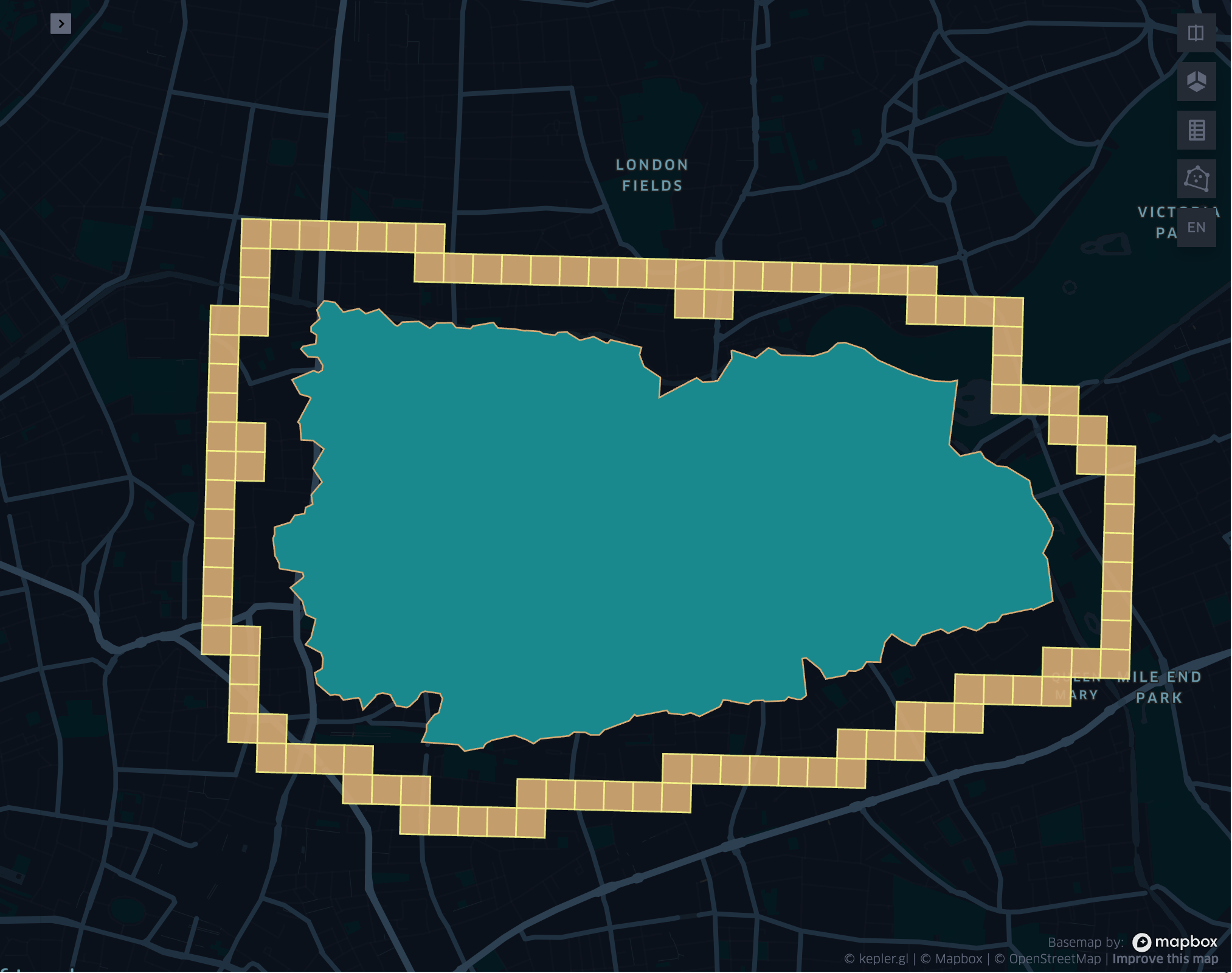
grid_geometrykloopexplode
- grid_geometrykloopexplode(geometry, resolution, k)
Returns the k loop (hollow ring) of a given geometry exploded.
- Parameters:
geometry (Column) – Geometry to be used
resolution (Column: Integer) – Resolution of the index used to calculate the k loop
k (Column: Integer) – K-loop size
- Return type:
Column: Long
- Example:
df = spark.createDataFrame([{'geometry': "MULTIPOLYGON (((30 20, 45 40, 10 40, 30 20)), ((15 5, 40 10, 10 20, 5 10, 15 5)))"}])
df.select(grid_geometrykloopexplode('geometry', lit(8), lit(2)).alias("kloop")).show()
+------------------+
| kloop|
+------------------+
|613177664827555839|
|613177664825458687|
|613177664831750143|
|613177664884178943|
| ...|
+------------------+
val df = List(("MULTIPOLYGON (((30 20, 45 40, 10 40, 30 20)), ((15 5, 40 10, 10 20, 5 10, 15 5)))")).toDF("geometry")
df.select(grid_geometrykloopexplode('geometry', lit(8), lit(2)).alias("kloop")).show()
+------------------+
| kloop|
+------------------+
|613177664827555839|
|613177664825458687|
|613177664831750143|
|613177664884178943|
| ...|
+------------------+
SELECT grid_geometrykloopexplode("MULTIPOLYGON (((30 20, 45 40, 10 40, 30 20)), ((15 5, 40 10, 10 20, 5 10, 15 5)))", 8, 2)
+------------------+
| kloop|
+------------------+
|613177664827555839|
|613177664825458687|
|613177664831750143|
|613177664884178943|
| ...|
+------------------+
df <- createDataFrame(data.frame(geometry = "MULTIPOLYGON (((30 20, 45 40, 10 40, 30 20)), ((15 5, 40 10, 10 20, 5 10, 15 5)))"))
showDF(select(df, grid_geometrykloopexplode(column("geometry"), lit(8L), lit(2L))))
+------------------+
| kloop|
+------------------+
|613177664827555839|
|613177664825458687|
|613177664831750143|
|613177664884178943|
| ...|
+------------------+
mosaic_explode [Deprecated]
- mosaic_explode(geometry, resolution, keep_core_geometries)
This is an alias for grid_tessellateexplode
mosaicfill [Deprecated]
- mosaicfill(geometry, resolution, keep_core_geometries)
This is an alias for grid_tessellate
point_index_geom [Deprecated]
- point_index_geom(point, resolution)
This is an alias for grid_pointascellid
point_index_lonlat [Deprecated]
- point_index_lonlat(point, resolution)
This is an alias for grid_longlatascellid
polyfill [Deprecated]
- polyfill(geom, resolution)
This is an alias for grid_polyfill