Workflows
Part of UCX is deployed as Databricks workflows to orchestrate
steps of the migration process. You can view the status of deployed workflows through the
workflows command and rerun failed workflows with the
repair-run command.
Assessment workflow
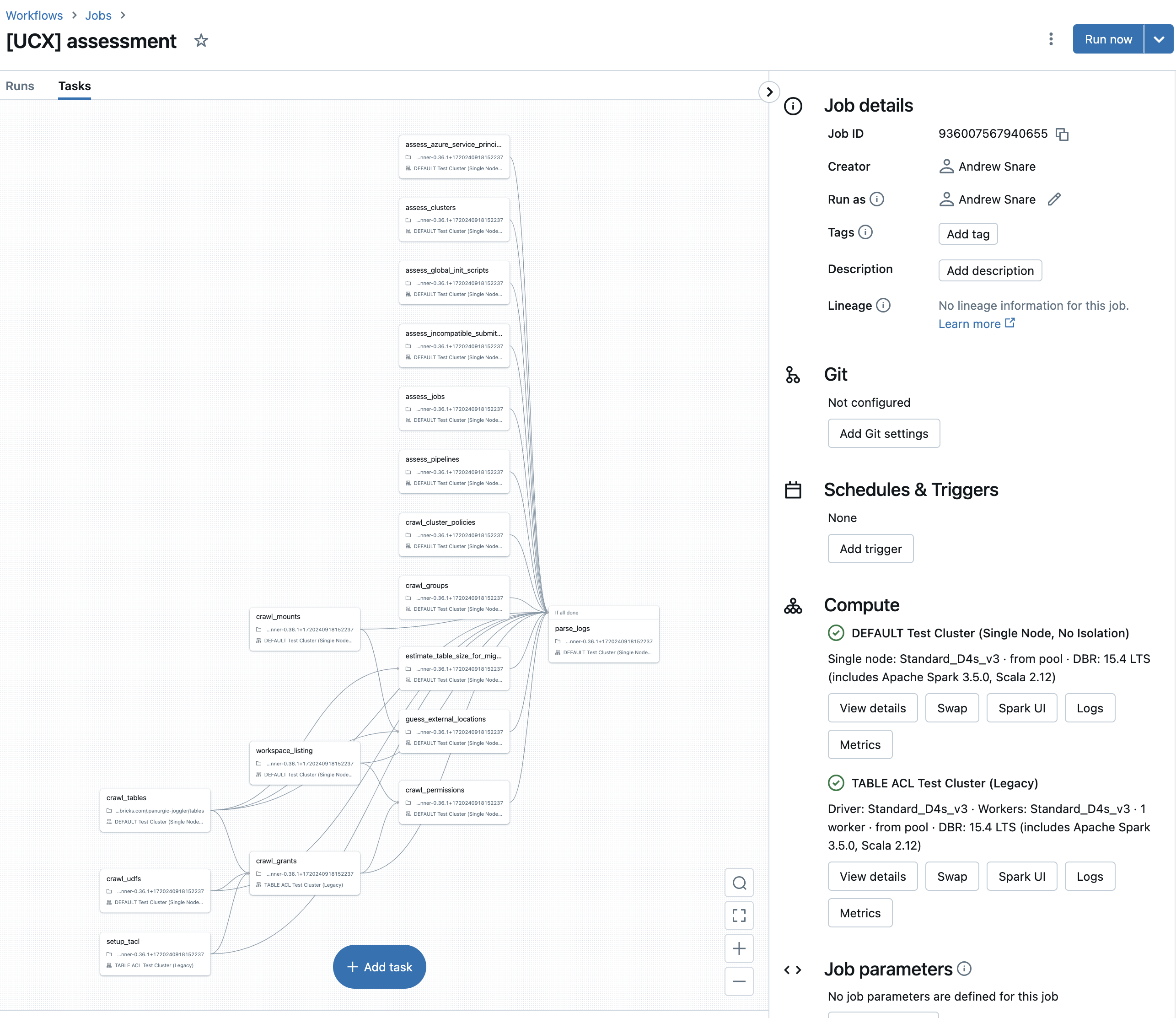
The assessment workflow can be triggered using the Databricks UI or via the
ensure-assessment-run command.
Account groups matching workspace local groups in which UCX is installed need to exist before running assessment.
The account groups can be created in one of three ways:
- Manually created using the "Account Console".
- Using SCIM or other service utilizing the Account API.
- Using the
create-account-groupscommand command.
The assessment workflow retrieves - or crawls - details of workspace assets
and securable objects in the Hive metastore
relevant for upgrading to UC to assess the compatibility with UC. The crawl_ tasks retrieve assess and objects. The
assess_ tasks assess the compatibility with UC. The output of each task is stored in the
inventory database so that it can be used for further analysis and decision-making through
the assessment report.
crawl_tables: This task retrieves table definitions from the Hive metastore and persists the definitions in thetablestable. The definitions include information such as:- Database/schema name
- Table name
- Table type
- Table location
crawl_udfs: This task retrieves UDF definitions from the Hive metastore and persists the definitions in theudfstable.setup_tacl: (Optimization) This task starts thetacljob cluster in parallel to other tasks.crawl_grants: This task retrieves privileges you can grant on Hive objects and persists the privilege definitions in thegrantstable The retrieved permission definitions include information such as:- Securable object: schema, table, view, (anonymous) function or any file.
- Principal: user, service principal or group
- Action type: grant, revoke or deny
estimate_table_size_for_migration: This task analyzes the Delta table retrieved bycrawl_tablesto retrieve an estimate of their size and persists the table sizes in thetable_sizetable. The table size support the decision for using theSYNCorCLONEtable migration strategy.crawl_mounts: This task retrieves mount point definitions and persists the definitions in themountstable.guess_external_locations: This task guesses shared mount path prefixes of external tables retrieved bycrawl_tablesthat use mount points and persists the locations in theexternal_locationstable. The goal is to identify the to-be created UC external locations.assess_jobs: This task retrieves the job definitions and persists the definitions in thejobstable. Job definitions may require updating to become UC compatible.assess_clusters: This task retrieves the clusters definitions and persists the definitions in theclusterstable. Cluster definitions may require updating to become UC compatible.assess_pipelines: This task retrieves the Delta Live Tables (DLT) pipelines definitions and persists the definitions in thepipelinestable. DLT definitions may require updating to become UC compatible.assess_incompatible_submit_runs: This task retrieves job runs, also known as job submit runs, and persists the definitions in thesubmit_runstable. Incompatibility with UC is assessed:- Databricks runtime should be version 11.3 or above
- Access mode should be set.
crawl_cluster_policies: This tasks retrieves cluster policies and persists the policies in thepoliciestable. Incompatibility with UC is assessed:- Databricks runtime should be version 11.3 or above
assess_azure_service_principals: This tasks retrieves Azure service principal authentications information from Spark configurations to access storage accounts and persists these configuration information inazure_service_principalstable. The Spark configurations from the following places are retrieved:- Clusters configurations
- Cluster policies
- Job cluster configurations
- Pipeline configurations
- Warehouse configuration
assess_global_init_scripts: This task retrieves global init scripts and persists references to the scripts in theglobal_init_scriptstable. Again, Azure service principal authentication information might be given in those scripts.workspace_listing: This tasks lists workspace files recursively to compile a collection of directories, notebooks, files, repos and libraries. The task uses multi-threading to parallelize the listing process for speeding up execution on big workspaces.crawl_permissions: This tasks retrieves workspace-local groups permissions and persists these permissions in thepermissionstable.crawl_groups: This tasks retrieves workspace-local groups and persists these permissions in thegroupstable.assess_dashboards: This task retrieves the dashboards to analyze their queries for migration problems
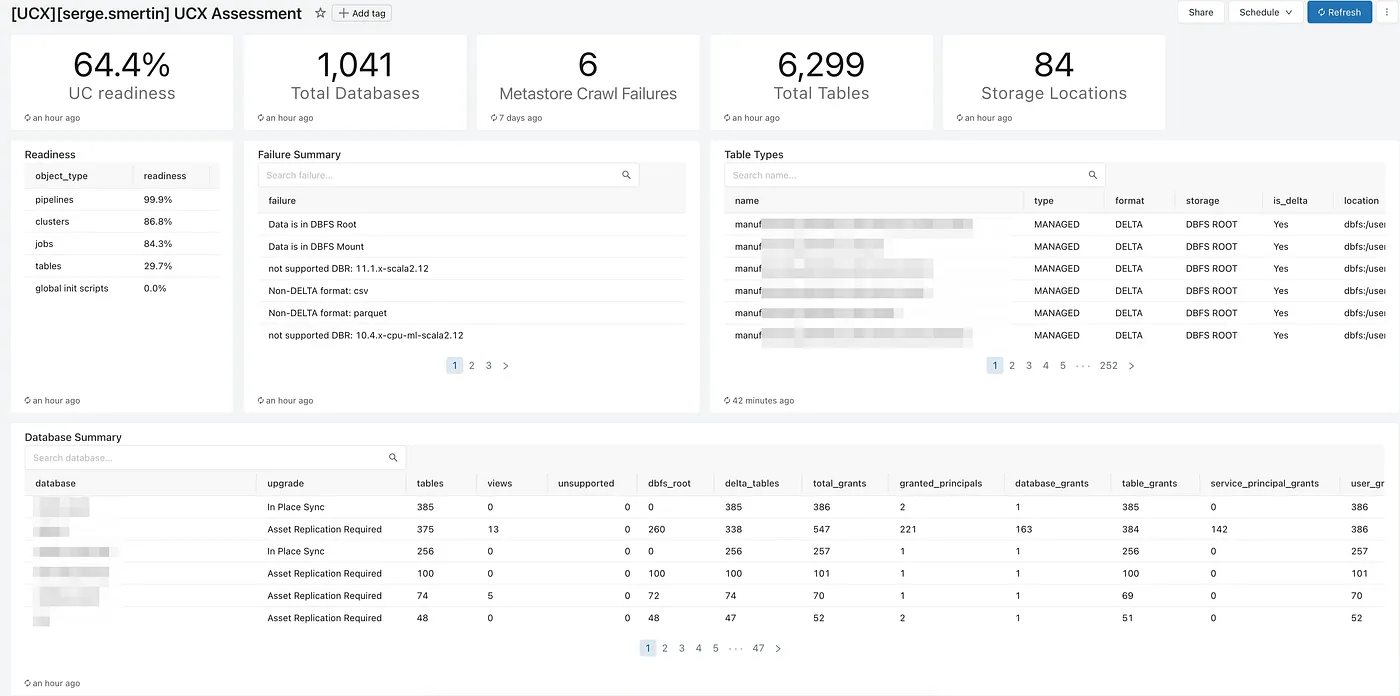
After UCX assessment workflow finished, see the assessment dashboard for findings and recommendations. See this guide for more details.
Proceed to the group migration workflow below or go back to the migration process diagram.
⚠️ Caution: To fully refresh the UCX assessment workflow and overwrite existing results, set the force_refresh parameter to true (or True). For large workspaces, this process can be time-consuming and resource-intensive. Only use this option if a complete reassessment is absolutely necessary. Alternatively, you can re run assessment using the command with the
force-refreshparameter set totrueto overwrite existing results.
Workflow assessment
This task retrieves the jobs to analyze their notebooks and files for migration problems. This will run for workflows that ran within the last 30 days. To analyze all workflows run the migration-progress-experimental workflow.
Group migration workflow
You are required to complete the assessment workflow before starting the group migration workflow.
The group migration workflow does NOT CREATE account groups. In contrast to account groups, the (legacy)
workspace-local groups cannot be assigned to additional workspaces or granted access to data in a Unity Catalog
metastore.
A Databricks admin assigns account groups to workspaces
using identity federation
to manage groups from a single place: your Databricks account. We expect UCX users to create account groups
centrally while most other Databricks resources that UCX touches are scoped to a single workspace.
For extra confidence, run validate-groups-membership command before running the
group migration. If you do not have account groups matching groups in the workspace in which UCX is installed, you can
run create-account-groups command before running the assessment and group migration workflow.
The group migration workflow is designed to migrate workspace-local groups to account-level groups. It verifies if the necessary groups are available to the workspace with the correct permissions, and removes unnecessary groups and permissions. The group migration workflow depends on the output of the assessment workflow, thus, should only be executed after a successful run of the assessment workflow. The group migration workflow may be executed multiple times.
verify_metastore_attached: Verifies if a metastore is attached. Account level groups are only available when a metastore is attached. Seeassign-metastorecommand.rename_workspace_local_groups: This task renames workspace-local groups by adding aucx-renamed-prefix. This step is taken to avoid conflicts with account groups that may have the same name as workspace-local groups.reflect_account_groups_on_workspace: This task adds matching account groups to this workspace. The matching account groups must exist for this step to be successful. This step is necessary to ensure that the account groups are available in the workspace for assigning permissions.apply_permissions_to_account_groups: This task assigns the full set of permissions of the original group to the account-level one. This step is necessary to ensure that the account-level groups have the necessary permissions to manage the entities in the workspace. It covers workspace-local permissions for all entities including:- Legacy Table ACLs
- Entitlements
- AWS instance profiles
- Clusters
- Cluster policies
- Instance Pools
- Databricks SQL warehouses
- Delta Live Tables
- Jobs
- MLflow experiments
- MLflow registry
- SQL Dashboards & Queries
- SQL Alerts
- Token and Password usage permissions
- Secret Scopes
- Notebooks
- Directories
- Repos
- Files
validate_groups_permissions: This task validates that all the crawled permissions are applied correctly to the destination groups.
After successfully running the group migration workflow:
- Remove workspace-level backup groups along with their permissions.
- Proceed to the table migration process.
For additional information see:
- The detailed design of thie group migration workflow.
- The migration process diagram showing the group migration workflow in context of the whole migration process.
Remove workspace local backup groups
Run this workflow only after the group migration workflow
The remove-workspace-local-backup-groups removes the now renamed and redundant workspace-local groups along with their
permissions. Run this workflow after confirming that the group migration is successful for all the groups involved.
Running this workflow is optional but recommended to keep the workspace clean.
Table migration workflows
This section lists the workflows that migrate tables and views. See this section for deciding which workflow to run and additional context for migrating tables.
Migrate tables
The general table migration workflow migrate-tables migrates all tables and views using default strategies.
migrate_external_tables_sync: This step migrates the external tables that are supported bySYNCcommand.migrate_dbfs_root_delta_tables: This step migrates delta tables stored in DBFS root using theDEEP CLONEcommand.migrate_dbfs_root_non_delta_tables: This step migrates non-delta tables stored in DBFS root using theCREATE TABLE AS SELECT * FROMcommand.migrate_views: This step migrates views using theCREATE VIEWcommand.update_migration_status: Refresh the migration status of all data objects.
Migrate external Hive SerDe tables
The experimental table migration workflow migrate-external-hiveserde-tables-in-place-experimental migrates tables that
support the SYNC AS EXTERNAL command.
migrate_hive_serde_in_place: This step migrates the Hive SerDe tables that are supported bySYNC AS EXTERNALcommand.migrate_views: This step migrates views using theCREATE VIEWcommand.update_migration_status: Refresh the migration status of all data objects.
Migrate external tables CTAS
The table migration workflow migrate-external-tables-ctas migrates tables with the CREATE TABLE AS SELECT * FROM
command.
migrate_other_external_ctasThis step migrates the Hive Serde tables using theCREATE TABLE AS SELECT * FROMcommand.migrate_hive_serde_ctas: This step migrates the Hive Serde tables using theCREATE TABLE AS SELECT * FROMcommand.migrate_views: This step migrates views using theCREATE VIEWcommand.update_migration_status: Refresh the migration status of all data objects.
Post-migration data reconciliation workflow
The migrate-data-reconciliation workflow validates the integrity of the migrated tables and persists its results in
the recon_results table. The workflow compares the following between the migrated Hive metastore and its UC
counterpart table:
Schema: See this result in theschema_matchescolumn.Column by column: See this result in thecolumn_comparisoncolumn.Row counts: If the row count is within the reconciliation threshold (defaults to 5%), thedata_matchescolumn is set totrue, otherwise it is set tofalse.Rows: If thecompare_rowsflag is set totrue, rows are compared using a hash comparison. Number of missing rows are stored in thesource_missing_countandtarget_missing_countcolumn, respectively.
The output is processed and displayed in the migration dashboard using the in reconciliation_results view.

[LEGACY] Scan tables in mounts Workflow
Always run this workflow AFTER the assessment has finished
- This experimental workflow attempts to find all Tables inside mount points that are present on your workspace.
- If you do not run this workflow, then
migrate-tables-in-mounts-experimentalwon't do anything. - It writes all results to
hive_metastore.<inventory_database>.tables, you can query those tables found by filtering on database values that starts withmounted_ - This command is incremental, meaning that each time you run it, it will overwrite the previous tables in mounts found.
- Current format are supported:
- DELTA - PARQUET - CSV - JSON
- Also detects partitioned DELTA and PARQUET
- You can configure these workflows with the following options available on conf.yml:
- include_mounts : A list of mount points to scans, by default the workflow scans for all mount points
- exclude_paths_in_mount : A list of paths to exclude in all mount points
- include_paths_in_mount : A list of paths to include in all mount points
[LEGACY] Migrate tables in mounts Workflow
- An experimental workflow that migrates tables in mount points using a
CREATE TABLEcommand, optinally sets a default tables owner if provided indefault_table_ownerconf parameter. - You must do the following in order to make this work:
- run the Assessment workflow
- run the scan tables in mounts workflow
- run the
create-table-mappingcommand- or manually create a
mapping.csvfile in Workspace -> Applications -> ucx
- or manually create a
[EXPERIMENTAL] Migration Progress Workflow
The migration-progress-experimental workflow populates the tables visualized in the
migration progress dashboard by updating a subset of the inventory tables
to track Unity Catalog compatability of Hive and workspace objects that need to be migrated. It runs automatically once a day, but can also be triggered manually.
The following pre-requisites need to be fulfilled before the workflow will run successfully: