Spatial functions
flatten_polygons
- flatten_polygons(col)
Explodes a MultiPolygon geometry into one row per constituent Polygon.
- Parameters:
col (Column) – MultiPolygon Geometry
- Return type:
Column: StringType
- Example:
df = spark.createDataFrame([
{'wkt': 'MULTIPOLYGON (((30 20, 45 40, 10 40, 30 20)), ((15 5, 40 10, 10 20, 5 10, 15 5)))'}
])
df.select(flatten_polygons('wkt')).show(2, False)
+------------------------------------------+
|element |
+------------------------------------------+
|POLYGON ((30 20, 45 40, 10 40, 30 20)) |
|POLYGON ((15 5, 40 10, 10 20, 5 10, 15 5))|
+------------------------------------------+
val df = List(("MULTIPOLYGON (((30 20, 45 40, 10 40, 30 20)), ((15 5, 40 10, 10 20, 5 10, 15 5)))")).toDF("wkt")
df.select(flatten_polygons(col("wkt"))).show(false)
+------------------------------------------+
|element |
+------------------------------------------+
|POLYGON ((30 20, 45 40, 10 40, 30 20)) |
|POLYGON ((15 5, 40 10, 10 20, 5 10, 15 5))|
+------------------------------------------+
SELECT flatten_polygons("'MULTIPOLYGON (((30 20, 45 40, 10 40, 30 20)), ((15 5, 40 10, 10 20, 5 10, 15 5)))'")
+------------------------------------------+
|element |
+------------------------------------------+
|POLYGON ((30 20, 45 40, 10 40, 30 20)) |
|POLYGON ((15 5, 40 10, 10 20, 5 10, 15 5))|
+------------------------------------------+
df <- createDataFrame(data.frame(wkt = 'MULTIPOLYGON (((30 20, 45 40, 10 40, 30 20)), ((15 5, 40 10, 10 20, 5 10, 15 5)))'))
showDF(select(df, flatten_polygons(column("wkt"))), truncate=F)
+------------------------------------------+
|element |
+------------------------------------------+
|POLYGON ((30 20, 45 40, 10 40, 30 20)) |
|POLYGON ((15 5, 40 10, 10 20, 5 10, 15 5))|
+------------------------------------------+
st_area
- st_area(col)
Compute the area of a geometry.
- Parameters:
col (Column) – Geometry
- Return type:
Column: DoubleType
- Example:
df = spark.createDataFrame([{'wkt': 'POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))'}])
df.select(st_area('wkt')).show()
+------------+
|st_area(wkt)|
+------------+
| 550.0|
+------------+
val df = List(("POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))")).toDF("wkt")
df.select(st_area(col("wkt"))).show()
+------------+
|st_area(wkt)|
+------------+
| 550.0|
+------------+
SELECT st_area("POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))")
+------------+
|st_area(wkt)|
+------------+
| 550.0|
+------------+
df <- createDataFrame(data.frame(wkt = "POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))"))
showDF(select(df, st_area(column("wkt"))))
+------------+
|st_area(wkt)|
+------------+
| 550.0|
+------------+
Note
Results of this function are always expressed in the original units of the input geometry.
st_buffer
- st_buffer(col, radius)
Buffer the input geometry by radius
radiusand return a new, buffered geometry. The optional parameter buffer_style_parameters=’quad_segs=# endcap=round|flat|square’ where “#” is the number of line segments used to approximate a quarter circle (default is 8); and endcap style for line features is one of listed (default=”round”)- Parameters:
col (Column) – Geometry
radius (Column (DoubleType)) – Double
buffer_style_parameters (Column (StringType)) – String
- Return type:
Column: Geometry
- Example:
df = spark.createDataFrame([{'wkt': 'POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))'}])
df.select(st_buffer('wkt', lit(2.))).show()
+--------------------+
| st_buffer(wkt, 2.0)|
+--------------------+
|POLYGON ((29.1055...|
+--------------------+
val df = List(("POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))")).toDF("wkt")
df.select(st_buffer(col("wkt"), 2d)).show()
+--------------------+
| st_buffer(wkt, 2.0)|
+--------------------+
|POLYGON ((29.1055...|
+--------------------+
SELECT st_buffer("POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))", 2d)
+--------------------+
| st_buffer(wkt, 2.0)|
+--------------------+
|POLYGON ((29.1055...|
+--------------------+
df <- createDataFrame(data.frame(wkt = "POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))"))
showDF(select(df, st_buffer(column("wkt"), lit(2))))
+--------------------+
| st_buffer(wkt, 2.0)|
+--------------------+
|POLYGON ((29.1055...|
+--------------------+
st_bufferloop
- st_bufferloop(col, innerRadius, outerRadius)
Returns a difference between
st_buffer(col, outerRadius)andst_buffer(col, innerRadius). The resulting geometry is a loop with a width of outerRadius - innerRadius.- Parameters:
col (Column) – Geometry
innerRadius (Column (DoubleType)) – Radius of the resulting geometry hole.
outerRadius (Column (DoubleType)) – Radius of the resulting geometry.
- Return type:
Column: Geometry
- Example:
df = spark.createDataFrame([{'wkt': 'POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))'}])
df.select(st_bufferloop('wkt', lit(2.), lit(2.1)).show()
+-------------------------+
| st_buffer(wkt, 2.0, 2.1)|
+-------------------------+
| POLYGON ((29.1055...|
+-------------------------+
val df = List(("POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))")).toDF("wkt")
df.select(st_bufferloop('wkt', lit(2.), lit(2.1))).show()
+-------------------------+
| st_buffer(wkt, 2.0, 2.1)|
+-------------------------+
| POLYGON ((29.1055...|
+-------------------------+
SELECT st_bufferloop("POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))", 2d, 2.1d)
+-------------------------+
| st_buffer(wkt, 2.0, 2.1)|
+-------------------------+
| POLYGON ((29.1055...|
+-------------------------+
df <- createDataFrame(data.frame(wkt = "POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))"))
showDF(select(df, st_bufferloop('wkt', lit(2.), lit(2.1))))
+-------------------------+
| st_buffer(wkt, 2.0, 2.1)|
+-------------------------+
| POLYGON ((29.1055...|
+-------------------------+
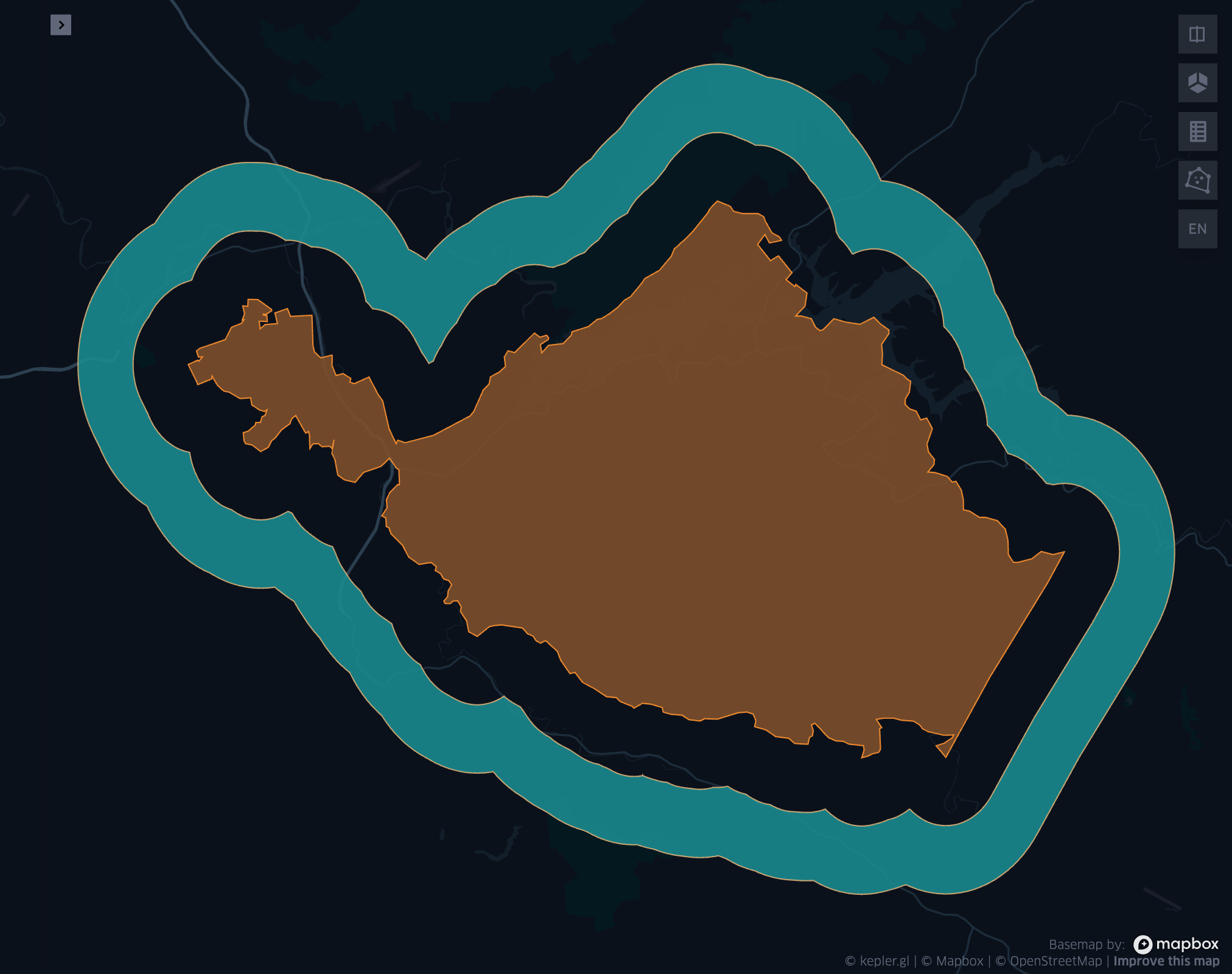
Fig 1. ST_BufferLoop(wkt, 0.02, 0.04)
st_centroid
- st_centroid(col)
Returns the POINT geometry representing the centroid of the input geometry.
- Parameters:
col (Column) – Geometry
- Return type:
Column: Geometry
- Example:
df = spark.createDataFrame([{'wkt': 'POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))'}])
df.select(st_centroid('wkt')).show()
+---------------------------------------------+
|st_centroid(wkt) |
+---------------------------------------------+
|POINT (25.454545454545453, 26.96969696969697)|
+---------------------------------------------+
val df = List(("POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))")).toDF("wkt")
df.select(st_centroid(col("wkt"))).show()
+---------------------------------------------+
|st_centroid(wkt) |
+---------------------------------------------+
|POINT (25.454545454545453, 26.96969696969697)|
+---------------------------------------------+
SELECT st_centroid("POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))")
+---------------------------------------------+
|st_centroid(wkt) |
+---------------------------------------------+
|POINT (25.454545454545453, 26.96969696969697)|
+---------------------------------------------+
df <- createDataFrame(data.frame(wkt = "POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))"))
showDF(select(df, st_centroid(column("wkt"))), truncate=F)
+---------------------------------------------+
|st_centroid(wkt) |
+---------------------------------------------+
|POINT (25.454545454545453, 26.96969696969697)|
+---------------------------------------------+
st_concavehull
- st_concavehull(col, concavity, <has_holes>)
Compute the concave hull of a geometry or multi-geometry object. It uses concavity and has_holes to determine the concave hull. Param concavity is the fraction of the difference between the longest and shortest edge lengths in the Delaunay Triangulation. If set to 1, this is the same as the convex hull. If set to 0, it produces maximum concaveness. Param has_holes is a boolean that determines whether the concave hull can have holes. If set to true, the concave hull can have holes. If set to false, the concave hull will not have holes.
- Parameters:
col (Column) – The input geometry
concavity (Column (DoubleType)) – The concavity of the hull
has_holes (Column (BooleanType)) – Whether the hull has holes, default false
- Return type:
Column
- Example:
df = spark.createDataFrame([{'wkt': 'MULTIPOINT ((10 40), (40 30), (20 20), (30 10))'}])
df.select(st_concavehull('wkt'), lit(0.1))).show(1, False)
+---------------------------------------------+
|st_concavehull(wkt, 0.1) |
+---------------------------------------------+
|POLYGON ((10 40, 20 20, 30 10, 40 30, 10 40))|
+---------------------------------------------+
val df = List(("MULTIPOINT ((10 40), (40 30), (20 20), (30 10))")).toDF("wkt")
df.select(st_concavehull(col("wkt"), lit(0.1))).show(false)
+---------------------------------------------+
|st_concavehull(wkt, 0.1) |
+---------------------------------------------+
|POLYGON ((10 40, 20 20, 30 10, 40 30, 10 40))|
+---------------------------------------------+
SELECT st_convexhull("MULTIPOINT ((10 40), (40 30), (20 20), (30 10))", 0.1)
+---------------------------------------------+
|st_concavehull(wkt, 0.1) |
+---------------------------------------------+
|POLYGON ((10 40, 20 20, 30 10, 40 30, 10 40))|
+---------------------------------------------+
df <- createDataFrame(data.frame(wkt = "MULTIPOINT ((10 40), (40 30), (20 20), (30 10))"))
showDF(select(df, st_concavehull(column("wkt"), lit(0.1))))
+---------------------------------------------+
|st_concavehull(wkt, 0.1) |
+---------------------------------------------+
|POLYGON ((10 40, 20 20, 30 10, 40 30, 10 40))|
+---------------------------------------------+
st_convexhull
- st_convexhull(col)
Compute the convex hull of a geometry or multi-geometry object.
- Parameters:
col (Column) – Geometry
- Return type:
Column
- Example:
df = spark.createDataFrame([{'wkt': 'MULTIPOINT ((10 40), (40 30), (20 20), (30 10))'}])
df.select(st_convexhull('wkt')).show(1, False)
+---------------------------------------------+
|st_convexhull(wkt) |
+---------------------------------------------+
|POLYGON ((10 40, 20 20, 30 10, 40 30, 10 40))|
+---------------------------------------------+
val df = List(("MULTIPOINT ((10 40), (40 30), (20 20), (30 10))")).toDF("wkt")
df.select(st_convexhull(col("wkt"))).show(false)
+---------------------------------------------+
|st_convexhull(wkt) |
+---------------------------------------------+
|POLYGON ((10 40, 20 20, 30 10, 40 30, 10 40))|
+---------------------------------------------+
SELECT st_convexhull("MULTIPOINT ((10 40), (40 30), (20 20), (30 10))")
+---------------------------------------------+
|st_convexhull(wkt) |
+---------------------------------------------+
|POLYGON ((10 40, 20 20, 30 10, 40 30, 10 40))|
+---------------------------------------------+
df <- createDataFrame(data.frame(wkt = "MULTIPOINT ((10 40), (40 30), (20 20), (30 10))"))
showDF(select(df, st_convexhull(column("wkt"))))
+---------------------------------------------+
|st_convexhull(wkt) |
+---------------------------------------------+
|POLYGON ((10 40, 20 20, 30 10, 40 30, 10 40))|
+---------------------------------------------+
st_difference
- st_difference(left_geom, right_geom)
Returns the point set difference of the left and right geometry.
- Parameters:
left_geom (Column) – Geometry
right_geom (Column) – Geometry
- Rtype Column:
Geometry
- Example:
df = spark.createDataFrame([{'left': 'POLYGON ((10 10, 20 10, 20 20, 10 20, 10 10))', 'right': 'POLYGON ((15 15, 25 15, 25 25, 15 25, 15 15))'}])
df.select(st_difference(col('left'), col('right'))).show()
+-----------------------------------------------------------+
| st_difference(left, right) |
+-----------------------------------------------------------+
|POLYGON ((10 10, 20 10, 20 15, 15 15, 15 20, 10 20, 10 10))|
+-----------------------------------------------------------+
val df = List(("POLYGON ((10 10, 20 10, 20 20, 10 20, 10 10))", "POLYGON ((15 15, 25 15, 25 25, 15 25, 15 15))")).toDF("left", "right")
df.select(st_difference(col('left'), col('right'))).show()
+-----------------------------------------------------------+
| st_difference(left, right) |
+-----------------------------------------------------------+
|POLYGON ((10 10, 20 10, 20 15, 15 15, 15 20, 10 20, 10 10))|
+-----------------------------------------------------------+
SELECT st_difference("POLYGON ((10 10, 20 10, 20 20, 10 20, 10 10))", "POLYGON ((15 15, 25 15, 25 25, 15 25, 15 15))")
+-----------------------------------------------------------+
| st_difference(left, right) |
+-----------------------------------------------------------+
|POLYGON ((10 10, 20 10, 20 15, 15 15, 15 20, 10 20, 10 10))|
+-----------------------------------------------------------+
df <- createDataFrame(data.frame(p1 = "POLYGON ((10 10, 20 10, 20 20, 10 20, 10 10))", p2 = "POLYGON ((15 15, 25 15, 25 25, 15 25, 15 15))"))
showDF(select(df, st_difference(column("p1"), column("p2"))), truncate=F)
+-----------------------------------------------------------+
| st_difference(left, right) |
+-----------------------------------------------------------+
|POLYGON ((10 10, 20 10, 20 15, 15 15, 15 20, 10 20, 10 10))|
+-----------------------------------------------------------+
st_dimension
- st_dimension(col)
Compute the dimension of the geometry.
- Parameters:
col (Column) – Geometry
- Return type:
Column: IntegerType
- Example:
df = spark.createDataFrame([{'wkt': 'POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))'}])
df.select(st_dimension('wkt')).show()
+-----------------+
|st_dimension(wkt)|
+-----------------+
| 2|
+-----------------+
val df = List("POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))").toDF("wkt")
df.select(st_dimension(col("wkt"))).show()
+-----------------+
|st_dimension(wkt)|
+-----------------+
| 2|
+-----------------+
SELECT st_dimension("POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))")
+-----------------+
|st_dimension(wkt)|
+-----------------+
| 2|
+-----------------+
df <- createDataFrame(data.frame(wkt = "POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))"))
showDF(select(df, st_dimension(column("wkt"))))
+-----------------+
|st_dimension(wkt)|
+-----------------+
| 2|
+-----------------+
st_distance
- st_distance(geom1, geom2)
Compute the euclidean distance between
geom1andgeom2.- Parameters:
geom1 (Column) – Geometry
geom2 (Column) – Geometry
- Return type:
Column: DoubleType
- Example:
df = spark.createDataFrame([{'point': 'POINT (5 5)', 'poly': 'POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))'}])
df.select(st_distance('poly', 'point')).show()
+------------------------+
|st_distance(poly, point)|
+------------------------+
| 15.652475842498529|
+------------------------+
val df = List(("POINT (5 5)", "POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))")).toDF("point", "poly")
df.select(st_distance(col("poly"), col("point"))).show()
+------------------------+
|st_distance(poly, point)|
+------------------------+
| 15.652475842498529|
+------------------------+
SELECT st_distance("POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))", "POINT (5 5)")
+------------------------+
|st_distance(poly, point)|
+------------------------+
| 15.652475842498529|
+------------------------+
df <- createDataFrame(data.frame(point = c( "POINT (5 5)"), poly = "POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))"))
showDF(select(df, st_distance(column("poly"), column("point"))))
+------------------------+
|st_distance(poly, point)|
+------------------------+
| 15.652475842498529|
+------------------------+
Note
Results of this euclidean distance function are always expressed in the original units of the input geometries, e.g. for WGS84 (SRID 4326) units are degrees.
st_dump
- st_dump(col)
Explodes a multi-geometry into one row per constituent geometry.
- Parameters:
col (Column) – The input multi-geometry
- Return type:
Column
- Example:
df = spark.createDataFrame([{'wkt': 'MULTIPOINT ((10 40), (40 30), (20 20), (30 10))'}])
df.select(st_dump('wkt')).show(5, False)
+-------------+
|element |
+-------------+
|POINT (10 40)|
|POINT (40 30)|
|POINT (20 20)|
|POINT (30 10)|
+-------------+
val df = List(("MULTIPOINT ((10 40), (40 30), (20 20), (30 10))")).toDF("wkt")
df.select(st_dump(col("wkt"))).show(false)
+-------------+
|element |
+-------------+
|POINT (10 40)|
|POINT (40 30)|
|POINT (20 20)|
|POINT (30 10)|
+-------------+
SELECT st_dump("MULTIPOINT ((10 40), (40 30), (20 20), (30 10))")
+-------------+
|element |
+-------------+
|POINT (10 40)|
|POINT (40 30)|
|POINT (20 20)|
|POINT (30 10)|
+-------------+
df <- createDataFrame(data.frame(wkt = "MULTIPOINT ((10 40), (40 30), (20 20), (30 10))"))
showDF(select(df, st_dump(column("wkt"))))
+-------------+
|element |
+-------------+
|POINT (10 40)|
|POINT (40 30)|
|POINT (20 20)|
|POINT (30 10)|
+-------------+
st_envelope
- st_envelope(col)
Returns the minimum bounding box of the input geometry, as a geometry. This bounding box is defined by the rectangular polygon with corner points
(x_min, y_min),(x_max, y_min),(x_min, y_max),(x_max, y_max).- Parameters:
col (Column) – Geometry
- Return type:
Column
- Example:
df = spark.createDataFrame([{'wkt': 'POLYGON ((10 10, 20 10, 15 20, 10 10))'}])
df.select(st_envelope('wkt')).show()
+-----------------------------------------------+
| st_envelope(wkt) |
+-----------------------------------------------+
| POLYGON ((10 10, 20 10, 20 20, 10 20, 10 10)) |
+-----------------------------------------------+
df = List(("POLYGON ((10 10, 20 10, 15 20, 10 10))")).toDF("wkt")
df.select(st_envelope('wkt')).show()
+-----------------------------------------------+
| st_envelope(wkt) |
+-----------------------------------------------+
| POLYGON ((10 10, 20 10, 20 20, 10 20, 10 10)) |
+-----------------------------------------------+
SELECT st_envelope("POLYGON ((10 10, 20 10, 15 20, 10 10))")
+-----------------------------------------------+
| st_envelope(wkt) |
+-----------------------------------------------+
| POLYGON ((10 10, 20 10, 20 20, 10 20, 10 10)) |
+-----------------------------------------------+
df <- createDataFrame(data.frame(wkt = "POLYGON ((10 10, 20 10, 15 20, 10 10))")
showDF(select(df, st_envelope(column("wkt"))), truncate=F)
+-----------------------------------------------+
| st_envelope(wkt) |
+-----------------------------------------------+
| POLYGON ((10 10, 20 10, 20 20, 10 20, 10 10)) |
+-----------------------------------------------+
st_geometrytype
- st_geometrytype(col)
Returns the type of the input geometry (“POINT”, “LINESTRING”, “POLYGON” etc.).
- Parameters:
col (Column) – Geometry
- Return type:
Column: StringType
- Example:
df = spark.createDataFrame([{'wkt': 'POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))'}])
df.select(st_geometrytype('wkt')).show()
+--------------------+
|st_geometrytype(wkt)|
+--------------------+
| POLYGON|
+--------------------+
val df = List(("POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))")).toDF("wkt")
df.select(st_geometrytype(col("wkt"))).show()
+--------------------+
|st_geometrytype(wkt)|
+--------------------+
| POLYGON|
+--------------------+
SELECT st_geometrytype("POLYGON((0 0, 10 0, 10 10, 0 10, 0 0), (15 15, 15 20, 20 20, 20 15, 15 15))")
+--------------------+
|st_geometrytype(wkt)|
+--------------------+
| POLYGON|
+--------------------+
df <- createDataFrame(data.frame(wkt = "POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))"))
showDF(select(df, st_geometrytype(column("wkt"))), truncate=F)
+--------------------+
|st_geometrytype(wkt)|
+--------------------+
| POLYGON|
+--------------------+
st_hasvalidcoordinates
- st_hasvalidcoordinates(col, crs, which)
Checks if all points in
geomare valid with respect to crs bounds. CRS bounds can be provided either as bounds or as reprojected_bounds.- Parameters:
col (Column) – Geometry
crs (Column) – CRS name (EPSG ID), e.g. “EPSG:2192”
which (Column) – Check against geographic
"bounds"or geometric"reprojected_bounds"bounds.
- Return type:
Column: IntegerType
- Example:
df = spark.createDataFrame([{'wkt': 'POLYGON((5.84 45.64, 5.92 45.64, 5.89 45.81, 5.79 45.81, 5.84 45.64))'}])
df.select(st_hasvalidcoordinates(col('wkt'), lit('EPSG:2192'), lit('bounds'))).show()
+----------------------------------------------+
|st_hasvalidcoordinates(wkt, EPSG:2192, bounds)|
+----------------------------------------------+
| true|
+----------------------------------------------+
val df = List(("POLYGON((5.84 45.64, 5.92 45.64, 5.89 45.81, 5.79 45.81, 5.84 45.64))")).toDF("wkt")
df.select(st_hasvalidcoordinates(col("wkt"), lit("EPSG:2192"), lit("bounds"))).show()
+----------------------------------------------+
|st_hasvalidcoordinates(wkt, EPSG:2192, bounds)|
+----------------------------------------------+
| true|
+----------------------------------------------+
SELECT st_hasvalidcoordinates("POLYGON((5.84 45.64, 5.92 45.64, 5.89 45.81, 5.79 45.81, 5.84 45.64))", "EPSG:2192", "bounds")
+----------------------------------------------+
|st_hasvalidcoordinates(wkt, EPSG:2192, bounds)|
+----------------------------------------------+
| true|
+----------------------------------------------+
df <- createDataFrame(data.frame(wkt = "POLYGON((5.84 45.64, 5.92 45.64, 5.89 45.81, 5.79 45.81, 5.84 45.64))"))
showDF(select(df, st_hasvalidcoordinates(column("wkt"), lit("EPSG:2192"), lit("bounds"))), truncate=F)
+----------------------------------------------+
|st_hasvalidcoordinates(wkt, EPSG:2192, bounds)|
+----------------------------------------------+
|true |
+----------------------------------------------+
st_haversine
- st_haversine(lat1, lng1, lat2, lng2)
Compute the haversine distance between lat1/lng1 and lat2/lng2.
- Parameters:
lat1 (Column) – DoubleType
lng1 (Column) – DoubleType
lat2 (Column) – DoubleType
lng2 (Column) – DoubleType
- Return type:
Column: DoubleType
- Example:
df = spark.createDataFrame([{'lat1': 0.0, 'lng1': 90.0, 'lat2': 0.0, 'lng2': 0.0}])
df.select(st_distance('lat1', 'lng1', 'lat2', 'lng2')).show()
+------------------------------------+
|st_haversine(lat1, lng1, lat2, lng2)|
+------------------------------------+
| 10007.55722101796|
+------------------------------------+
val df = List((0.0, 90.0, 0.0, 0.0)).toDF("lat1", "lng1", "lat2", "lng2")
df.select(st_haversine(col("lat1"), col("lng1"), col("lat2"), col("lng2"))).show()
+------------------------------------+
|st_haversine(lat1, lng1, lat2, lng2)|
+------------------------------------+
| 10007.55722101796|
+------------------------------------+
SELECT st_haversine(0.0, 90.0, 0.0, 0.0)
+------------------------------------+
|st_haversine(lat1, lng1, lat2, lng2)|
+------------------------------------+
| 10007.55722101796|
+------------------------------------+
df <- createDataFrame(data.frame(lat1 = c(0.0), lng1 = c(90.0), lat2 = c(0.0), lng2 = c(0.0)))
showDF(select(df, st_haversine(column("lat1"), column("lng1"), column("lat2"), column("lng2"))))
+------------------------------------+
|st_haversine(lat1, lng1, lat2, lng2)|
+------------------------------------+
| 10007.55722101796|
+------------------------------------+
Note
Results of this function are always expressed in km, while the input lat/lng pairs are expected to be in degrees. The radius used (in km) is 6371.0088.
st_interpolateelevation
- st_interpolateelevation(pointsArray, linesArray, mergeTolerance, snapTolerance, splitPointFinder, origin, xWidth, yWidth, xSize, ySize)
Compute interpolated elevations across a grid of points described by:
origin: a point geometry describing the bottom-left corner of the grid,xWidthandyWidth: the number of points in the grid in x and y directions,xSizeandySize: the space between grid points in the x and y directions.
- Note:
To generate a grid from a “top-left”
origin, use a negative value forySize.
The underlying algorithm first creates a surface mesh by triangulating
pointsArray(includinglinesArrayas a set of constraint lines) then determines where each point in the grid would lie on the surface mesh. Finally, it interpolates the elevation of that point based on the surrounding triangle’s vertices.As with
st_triangulate, there are two ‘tolerance’ parameters for the algorithm:mergeTolerancesets the point merging tolerance of the triangulation algorithm, i.e. before the initial triangulation is performed, nearby points inpointsArraycan be merged in order to speed up the triangulation process. A value of zero means all points are considered for triangulation.snapTolerancesets the tolerance for post-processing the results of the triangulation, i.e. matching the vertices of the output triangles to input points / lines. This is necessary as the algorithm often returns null height / Z values. Setting this to a large value may result in the incorrect Z values being assigned to the output triangle vertices (especially whenlinesArraycontains very densely spaced segments). Setting this value to zero may result in the output triangle vertices being assigned a null Z value.
Both tolerance parameters are expressed in the same units as the projection of the input point geometries.
Additionally, you have control over the algorithm used to find split points on the constraint lines. The recommended default option here is the “NONENCROACHING” algorithm. You can also use the “MIDPOINT” algorithm if you find the constraint fitting process fails to converge. For full details of these options see the JTS reference here.
This is a generator expression and the resulting DataFrame will contain one row per point of the grid.
- Parameters:
pointsArray (Column (ArrayType(Geometry))) – Array of geometries respresenting the points to be triangulated
linesArray (Column (ArrayType(Geometry))) – Array of geometries respresenting the lines to be used as constraints
mergeTolerance (Column (DoubleType)) – A tolerance used to coalesce points in close proximity to each other before performing triangulation.
snapTolerance (Column (DoubleType)) – A snapping tolerance used to relate created points to their corresponding lines for elevation interpolation.
origin (Column (Geometry)) – A point geometry describing the bottom-left corner of the grid.
splitPointFinder (Column (StringType)) – Algorithm used for finding split points on constraint lines. Options are “NONENCROACHING” and “MIDPOINT”.
xWidth (Column (IntegerType)) – The number of points in the grid in x direction.
yWidth (Column (IntegerType)) – The number of points in the grid in y direction.
xSize (Column (DoubleType)) – The spacing between each point on the grid’s x-axis.
ySize (Column (DoubleType)) – The spacing between each point on the grid’s y-axis.
- Return type:
Column (Geometry)
- Example:
df = (
spark.createDataFrame(
[
["POINT Z (2 1 0)"],
["POINT Z (3 2 1)"],
["POINT Z (1 3 3)"],
["POINT Z (0 2 2)"],
],
["wkt"],
)
.groupBy()
.agg(collect_list("wkt").alias("masspoints"))
.withColumn("breaklines", array(lit("LINESTRING EMPTY")))
.withColumn("origin", st_geomfromwkt(lit("POINT (0.6 1.8)")))
.withColumn("xWidth", lit(12))
.withColumn("yWidth", lit(6))
.withColumn("xSize", lit(0.1))
.withColumn("ySize", lit(0.1))
)
df.select(
st_interpolateelevation(
"masspoints", "breaklines", lit(0.0), lit(0.01),
"origin", "xWidth", "yWidth", "xSize", "ySize",
split_point_finder="NONENCROACHING"
)
).show(4, truncate=False)
+--------------------------------------------------+
|geom |
+--------------------------------------------------+
|POINT Z(1.4 2.1 1.6666666666666665) |
|POINT Z(1.5 2 1.5) |
|POINT Z(1.4 1.9000000000000001 1.4000000000000001)|
|POINT Z(0.9 2 1.7) |
+--------------------------------------------------+
val df = Seq(
Seq(
"POINT Z (2 1 0)", "POINT Z (3 2 1)",
"POINT Z (1 3 3)", "POINT Z (0 2 2)"
)
)
.toDF("masspoints")
.withColumn("breaklines", array().cast(ArrayType(StringType)))
.withColumn("origin", st_geomfromwkt(lit("POINT (0.6 1.8)")))
.withColumn("xWidth", lit(12))
.withColumn("yWidth", lit(6))
.withColumn("xSize", lit(0.1))
.withColumn("ySize", lit(0.1))
df.select(
st_interpolateelevation(
$"masspoints", $"breaklines",
lit(0.0), lit(0.01), lit("NONENCROACHING"),
$"origin", $"xWidth", $"yWidth", $"xSize", $"ySize"
)
).show(4, false)
+--------------------------------------------------+
|geom |
+--------------------------------------------------+
|POINT Z(1.4 2.1 1.6666666666666665) |
|POINT Z(1.5 2 1.5) |
|POINT Z(1.4 1.9000000000000001 1.4000000000000001)|
|POINT Z(0.9 2 1.7) |
+--------------------------------------------------+
SELECT
ST_INTERPOLATEELEVATION(
ARRAY(
"POINT Z (2 1 0)",
"POINT Z (3 2 1)",
"POINT Z (1 3 3)",
"POINT Z (0 2 2)"
),
ARRAY("LINESTRING EMPTY"),
DOUBLE(0.0), DOUBLE(0.01), "NONENCROACHING",
"POINT (0.6 1.8)", 12, 6, DOUBLE(0.1), DOUBLE(0.1)
)
+--------------------------------------------------+
|geom |
+--------------------------------------------------+
|POINT Z(1.4 2.1 1.6666666666666665) |
|POINT Z(1.5 2 1.5) |
|POINT Z(1.4 1.9000000000000001 1.4000000000000001)|
|POINT Z(0.9 2 1.7) |
+--------------------------------------------------+
sdf <- createDataFrame(
data.frame(
points = c(
"POINT Z (3 2 1)", "POINT Z (2 1 0)",
"POINT Z (1 3 3)", "POINT Z (0 2 2)"
)
)
)
sdf <- agg(groupBy(sdf), masspoints = collect_list(column("points")))
sdf <- withColumn(sdf, "breaklines", expr("array('LINESTRING EMPTY')"))
sdf <- select(sdf, st_interpolateelevation(
column("masspoints"), column("breaklines"),
lit(0.0), lit(0.01), lit("NONENCROACHING"),
lit("POINT (0.6 1.8)"), lit(12L), lit(6L), lit(0.1), lit(0.1)
)
)
showDF(sdf, n=4, truncate=F)
+--------------------------------------------------+
|geom |
+--------------------------------------------------+
|POINT Z(1.4 2.1 1.6666666666666665) |
|POINT Z(1.5 2 1.5) |
|POINT Z(1.4 1.9000000000000001 1.4000000000000001)|
|POINT Z(0.9 2 1.7) |
+--------------------------------------------------+
st_intersection
- st_intersection(geom1, geom2)
Returns a geometry representing the intersection of
left_geomandright_geom. Also, see st_intersection_agg function.- Parameters:
geom1 (Column) – Geometry
geom2 (Column) – Geometry
- Return type:
Column
- Example:
df = spark.createDataFrame([{'p1': 'POLYGON ((0 0, 0 3, 3 3, 3 0))', 'p2': 'POLYGON ((2 2, 2 4, 4 4, 4 2))'}])
df.select(st_intersection(col('p1'), col('p2'))).show(1, False)
+-----------------------------------+
|st_intersection(p1, p2) |
+-----------------------------------+
|POLYGON ((2 2, 3 2, 3 3, 2 3, 2 2))|
+-----------------------------------+
val df = List(("POLYGON ((0 0, 0 3, 3 3, 3 0))", "POLYGON ((2 2, 2 4, 4 4, 4 2))")).toDF("p1", "p2")
df.select(st_intersection(col("p1"), col("p2"))).show(false)
+-----------------------------------+
|st_intersection(p1, p2) |
+-----------------------------------+
|POLYGON ((2 2, 3 2, 3 3, 2 3, 2 2))|
+-----------------------------------+
SELECT st_intersection("POLYGON ((0 0, 0 3, 3 3, 3 0))", "POLYGON ((2 2, 2 4, 4 4, 4 2))")
+-----------------------------------+
|st_intersection(p1, p2) |
+-----------------------------------+
|POLYGON ((2 2, 3 2, 3 3, 2 3, 2 2))|
+-----------------------------------+
df <- createDataFrame(data.frame(p1 = "POLYGON ((0 0, 0 3, 3 3, 3 0))", p2 = "POLYGON ((2 2, 2 4, 4 4, 4 2))"))
showDF(select(df, st_intersection(column("p1"), column("p2"))), truncate=F)
+-----------------------------------+
|st_intersection(p1, p2) |
+-----------------------------------+
|POLYGON ((2 2, 3 2, 3 3, 2 3, 2 2))|
+-----------------------------------+
st_isvalid
- st_isvalid(col)
Returns
trueif the geometry is valid.- Parameters:
col (Column) – Geometry
- Return type:
Column: BooleanType
- Example:
df = spark.createDataFrame([{'wkt': 'POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))'}])
df.select(st_isvalid('wkt')).show()
+---------------+
|st_isvalid(wkt)|
+---------------+
| true|
+---------------+
df = spark.createDataFrame([{
'wkt': 'POLYGON((0 0, 10 0, 10 10, 0 10, 0 0), (15 15, 15 20, 20 20, 20 15, 15 15))'
}])
df.select(st_isvalid('wkt')).show()
+---------------+
|st_isvalid(wkt)|
+---------------+
| false|
+---------------+
val df = List(("POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))")).toDF("wkt")
df.select(st_isvalid(col("wkt"))).show()
+---------------+
|st_isvalid(wkt)|
+---------------+
| true|
+---------------+
val df = List(("POLYGON((0 0, 10 0, 10 10, 0 10, 0 0), (15 15, 15 20, 20 20, 20 15, 15 15))")).toDF("wkt")
df.select(st_isvalid(col("wkt"))).show()
+---------------+
|st_isvalid(wkt)|
+---------------+
| false|
+---------------+
SELECT st_isvalid("POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))")
+---------------+
|st_isvalid(wkt)|
+---------------+
| true|
+---------------+
SELECT st_isvalid("POLYGON((0 0, 10 0, 10 10, 0 10, 0 0), (15 15, 15 20, 20 20, 20 15, 15 15))")
+---------------+
|st_isvalid(wkt)|
+---------------+
| false|
+---------------+
df <- createDataFrame(data.frame(wkt = "POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))"))
showDF(select(df, st_isvalid(column("wkt"))), truncate=F)
+---------------+
|st_isvalid(wkt)|
+---------------+
| true|
+---------------+
df <- createDataFrame(data.frame(wkt = "POLYGON((0 0, 10 0, 10 10, 0 10, 0 0), (15 15, 15 20, 20 20, 20 15, 15 15))"))
showDF(select(df, st_isvalid(column("wkt"))), truncate=F)
+---------------+
|st_isvalid(wkt)|
+---------------+
| false|
+---------------+
st_length
- st_length(col)
Compute the length of a geometry.
- Parameters:
col (Column) – Geometry
- Return type:
Column: DoubleType
- Example:
df = spark.createDataFrame([{'wkt': 'POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))'}])
df.select(st_length('wkt')).show()
+-----------------+
| st_length(wkt)|
+-----------------+
|96.34413615167959|
+-----------------+
val df = List(("POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))")).toDF("wkt")
df.select(st_length(col("wkt"))).show()
+-----------------+
| st_length(wkt)|
+-----------------+
|96.34413615167959|
+-----------------+
SELECT st_length("POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))")
+-----------------+
| st_length(wkt)|
+-----------------+
|96.34413615167959|
+-----------------+
df <- createDataFrame(data.frame(wkt = "POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))"))
showDF(select(df, st_length(column("wkt"))))
+-----------------+
| st_length(wkt)|
+-----------------+
|96.34413615167959|
+-----------------+
Note
Results of this function are always expressed in the original units of the input geometry.
Note
Alias for st_perimeter.
st_numpoints
- st_numpoints(col)
Returns the number of points in
geom.- Parameters:
col (Column) – Geometry
- Return type:
Column: IntegerType
- Example:
df = spark.createDataFrame([{'wkt': 'POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))'}])
df.select(st_numpoints('wkt')).show()
+-----------------+
|st_numpoints(wkt)|
+-----------------+
| 5|
+-----------------+
val df = List(("POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))")).toDF("wkt")
df.select(st_numpoints(col("wkt"))).show()
+-----------------+
|st_numpoints(wkt)|
+-----------------+
| 5|
+-----------------+
SELECT st_numpoints("POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))")
+-----------------+
|st_numpoints(wkt)|
+-----------------+
| 5|
+-----------------+
df <- createDataFrame(data.frame(wkt = "POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))"))
showDF(select(df, st_numpoints(column("wkt"))))
+-----------------+
|st_numpoints(wkt)|
+-----------------+
| 5|
+-----------------+
st_perimeter
- st_perimeter(col)
Compute the perimeter length of a geometry.
- Parameters:
col (Column) – Geometry
- Return type:
Column: DoubleType
- Example:
df = spark.createDataFrame([{'wkt': 'POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))'}])
df.select(st_perimeter('wkt')).show()
+-----------------+
|st_perimeter(wkt)|
+-----------------+
|96.34413615167959|
+-----------------+
val df = List(("POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))")).toDF("wkt")
df.select(st_perimeter(col("wkt"))).show()
+-----------------+
|st_perimeter(wkt)|
+-----------------+
|96.34413615167959|
+-----------------+
SELECT st_perimeter("POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))")
+-----------------+
|st_perimeter(wkt)|
+-----------------+
|96.34413615167959|
+-----------------+
df <- createDataFrame(data.frame(wkt = "POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))"))
showDF(select(df, st_perimeter(column("wkt"))))
+-----------------+
|st_perimeter(wkt)|
+-----------------+
|96.34413615167959|
+-----------------+
Note
Results of this function are always expressed in the original units of the input geometry.
Note
Alias for st_length.
st_rotate
- st_rotate(col, td)
Rotates
geomusing the rotational factortd.- Parameters:
col (Column) – Geometry
td (Column (DoubleType)) – Rotation (in radians)
- Return type:
Column
- Example:
from math import pi
df = spark.createDataFrame([{'wkt': 'POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))'}])
df.select(st_rotate('wkt', lit(pi))).show(1, False)
+-------------------------------------------------------+
|st_rotate(wkt, 3.141592653589793) |
+-------------------------------------------------------+
|POLYGON ((-30 -10, -40 -40, -20 -40, -10 -20, -30 -10))|
+-------------------------------------------------------+
import math.Pi
val df = List(("POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))")).toDF("wkt")
df.select(st_rotate(col("wkt"), lit(Pi))).show(false)
+-------------------------------------------------------+
|st_rotate(wkt, 3.141592653589793) |
+-------------------------------------------------------+
|POLYGON ((-30 -10, -40 -40, -20 -40, -10 -20, -30 -10))|
+-------------------------------------------------------+
SELECT st_rotate("POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))", pi())
+-------------------------------------------------------+
|st_rotate(wkt, 3.141592653589793) |
+-------------------------------------------------------+
|POLYGON ((-30 -10, -40 -40, -20 -40, -10 -20, -30 -10))|
+-------------------------------------------------------+
df <- createDataFrame(data.frame(wkt = "POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))"))
showDF(select(df, st_rotate(column("wkt"), lit(pi))), truncate=F)
+-------------------------------------------------------+
|st_rotate(wkt, 3.141592653589793) |
+-------------------------------------------------------+
|POLYGON ((-30 -10, -40 -40, -20 -40, -10 -20, -30 -10))|
+-------------------------------------------------------+
st_scale
- st_scale(col, xd, yd)
Scales
geomusing the scaling factorsxdandyd.- Parameters:
col (Column) – Geometry
xd (Column (DoubleType)) – Scale factor in the x-direction
yd (Column (DoubleType)) – Scale factor in the y-direction
- Return type:
Column
- Example:
df = spark.createDataFrame([{'wkt': 'POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))'}])
df.select(st_scale('wkt', lit(0.5), lit(2))).show(1, False)
+--------------------------------------------+
|st_scale(wkt, 0.5, 2) |
+--------------------------------------------+
|POLYGON ((15 20, 20 80, 10 80, 5 40, 15 20))|
+--------------------------------------------+
val df = List(("POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))")).toDF("wkt")
df.select(st_scale(col("wkt"), lit(0.5), lit(2.0))).show(false)
+--------------------------------------------+
|st_scale(wkt, 0.5, 2) |
+--------------------------------------------+
|POLYGON ((15 20, 20 80, 10 80, 5 40, 15 20))|
+--------------------------------------------+
SELECT st_scale("POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))", 0.5d, 2.0d)
+--------------------------------------------+
|st_scale(wkt, 0.5, 2) |
+--------------------------------------------+
|POLYGON ((15 20, 20 80, 10 80, 5 40, 15 20))|
+--------------------------------------------+
df <- createDataFrame(data.frame(wkt = "POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))"))
showDF(select(df, st_scale(column('wkt'), lit(0.5), lit(2))), truncate=F)
+--------------------------------------------+
|st_scale(wkt, 0.5, 2) |
+--------------------------------------------+
|POLYGON ((15 20, 20 80, 10 80, 5 40, 15 20))|
+--------------------------------------------+
st_setsrid
- st_setsrid(col, srid)
Sets the Coordinate Reference System well-known identifier (SRID) for
geom.- Parameters:
col (Column) – Geometry
srid (Column (IntegerType)) – The spatial reference identifier of
geom, expressed as an integer, e.g.4326for EPSG:4326 / WGS84
- Return type:
Column
- Example:
df = spark.createDataFrame([{'wkt': 'MULTIPOINT ((10 40), (40 30), (20 20), (30 10))'}])
df.select(st_setsrid(st_geomfromwkt('wkt'), lit(4326))).show(1)
+---------------------------------+
|st_setsrid(convert_to(wkt), 4326)|
+---------------------------------+
| {2, 4326, [[[10.0...|
+---------------------------------+
val df = List("MULTIPOINT ((10 40), (40 30), (20 20), (30 10))").toDF("wkt")
df.select(st_setsrid(st_geomfromwkt(col("wkt")), lit(4326))).show
+---------------------------------+
|st_setsrid(convert_to(wkt), 4326)|
+---------------------------------+
| {2, 4326, [[[10.0...|
+---------------------------------+
select st_setsrid(st_geomfromwkt("MULTIPOINT ((10 40), (40 30), (20 20), (30 10))"), 4326)
+---------------------------------+
|st_setsrid(convert_to(wkt), 4326)|
+---------------------------------+
| {2, 4326, [[[10.0...|
+---------------------------------+
df <- createDataFrame(data.frame(wkt = "MULTIPOINT ((10 40), (40 30), (20 20), (30 10))"))
showDF(select(df, st_setsrid(st_geomfromwkt(column("wkt")), lit(4326L))))
+---------------------------------+
|st_setsrid(convert_to(wkt), 4326)|
+---------------------------------+
| {2, 4326, [[[10.0...|
+---------------------------------+
Note
st_setsrid does not transform the coordinates of geom,
rather it tells Mosaic the SRID in which the current coordinates are expressed.
Changed in 0.4 series
st_srid, st_setsrid, and st_transform operate best on Mosaic Internal Geometry across language bindings, so recommend calling st_geomfromwkt or st_geomfromwkb to convert from WKT and WKB.
You can convert back after the transform, e.g. using st_astext or st_asbinary.
Alternatively, you can use st_updatesrid to transform WKB, WKB, GeoJSON, or Mosaic Internal Geometry
by specifying the srcSRID and dstSRID.
st_simplify
- st_simplify(col, tol)
Returns the simplified geometry.
- Parameters:
col (Column) – Geometry
tol (Column) – Tolerance
- Return type:
Column: Geometry
- Example:
df = spark.createDataFrame([{'wkt': 'LINESTRING (0 1, 1 2, 2 1, 3 0)'}])
df.select(st_simplify('wkt', 1.0)).show()
+----------------------------+
| st_simplify(wkt, 1.0) |
+----------------------------+
| LINESTRING (0 1, 1 2, 3 0) |
+----------------------------+
df = List(("LINESTRING (0 1, 1 2, 2 1, 3 0)")).toDF("wkt")
df.select(st_simplify('wkt', 1.0)).show()
+----------------------------+
| st_simplify(wkt, 1.0) |
+----------------------------+
| LINESTRING (0 1, 1 2, 3 0) |
+----------------------------+
SELECT st_simplify("LINESTRING (0 1, 1 2, 2 1, 3 0)", 1.0)
+----------------------------+
| st_simplify(wkt, 1.0) |
+----------------------------+
| LINESTRING (0 1, 1 2, 3 0) |
+----------------------------+
df <- createDataFrame(data.frame(wkt = "LINESTRING (0 1, 1 2, 2 1, 3 0)")
showDF(select(df, st_simplify(column("wkt"), 1.0)), truncate=F)
+----------------------------+
| st_simplify(wkt, 1.0) |
+----------------------------+
| LINESTRING (0 1, 1 2, 3 0) |
+----------------------------+
st_srid
- st_srid(col)
Looks up the Coordinate Reference System well-known identifier (SRID) for
geom.- Parameters:
col (Column) – Geometry
- Return type:
Column
- Example:
json_geom = '{"type":"MultiPoint","coordinates":[[10,40],[40,30],[20,20],[30,10]],"crs":{"type":"name","properties":{"name":"EPSG:4326"}}}'
df = spark.createDataFrame([{'json': json_geom}])
df.select(st_srid(st_geomfromgeojson('json'))).show(1)
+--------------------------------------------+
| st_srid(st_geomfromgeojson(as_json(json))) |
+--------------------------------------------+
| 4326 |
+--------------------------------------------+
val df =
List("""{"type":"MultiPoint","coordinates":[[10,40],[40,30],[20,20],[30,10]],"crs":{"type":"name","properties":{"name":"EPSG:4326"}}}""")
.toDF("json")
df.select(st_srid(st_geomfromgeojson(col("json")))).show(1)
+--------------------------------------------+
| st_srid(st_geomfromgeojson(as_json(json))) |
+--------------------------------------------+
| 4326 |
+--------------------------------------------+
select st_srid(as_json('{"type":"MultiPoint","coordinates":[[10,40],[40,30],[20,20],[30,10]],"crs":{"type":"name","properties":{"name":"EPSG:4326"}}}'))
+--------------------------------------------+
| st_srid(st_geomfromgeojson(as_json(...))) |
+--------------------------------------------+
| 4326 |
+--------------------------------------------+
json_geom <- '{"type":"MultiPoint","coordinates":[[10,40],[40,30],[20,20],[30,10]],"crs":{"type":"name","properties":{"name":"EPSG:4326"}}}'
df <- createDataFrame(data.frame(json=json_geom))
showDF(select(df, st_srid(st_geomfromgeojson(column('json')))))
+--------------+
| st_srid(...) |
+--------------+
| 4326 |
+--------------+
Note
Changed in 0.4 series
st_srid, st_setsrid, and st_transform operate best on Mosaic Internal Geometry across language bindings, so recommend calling st_geomfromwkt or st_geomfromwkb to convert from WKT and WKB.
You can convert back after the transform, e.g. using st_astext or st_asbinary.
Alternatively, you can use st_updatesrid to transform WKB, WKB, GeoJSON, or Mosaic Internal Geometry
by specifying the srcSRID and dstSRID.
st_transform
- st_transform(col, srid)
Transforms the horizontal (XY) coordinates of
geomfrom the current reference system to that described bysrid. Recommend use of Mosaic Internal Geometry for the transform, then convert to desired interchange format [WKB, WKT, GeoJSON] afterwards.- Parameters:
col (Column) – Geometry
srid (Column (IntegerType)) – Target spatial reference system for
geom, expressed as an integer, e.g.3857for EPSG:3857 / Pseudo-Mercator
- Return type:
Column
- Example:
df = (
spark.createDataFrame([{'wkt': 'MULTIPOINT ((10 40), (40 30), (20 20), (30 10))'}])
.withColumn('geom', st_setsrid(st_geomfromwkt('wkt'), lit(4326)))
)
df.select(st_astext(st_transform('geom', lit(3857)))).show(1, False)
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|convert_to(st_transform(geom, 3857)) |
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|MULTIPOINT ((1113194.9079327357 4865942.279503176), (4452779.631730943 3503549.843504374), (2226389.8158654715 2273030.926987689), (3339584.723798207 1118889.9748579597))|
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
val df = List("MULTIPOINT ((10 40), (40 30), (20 20), (30 10))").toDF("wkt")
.withColumn("geom", st_setsrid(st_geomfromwkt(col("wkt")), lit(4326)))
df.select(st_astext(st_transform(col("geom"), lit(3857)))).show(1, false)
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|convert_to(st_transform(geom, 3857)) |
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|MULTIPOINT ((1113194.9079327357 4865942.279503176), (4452779.631730943 3503549.843504374), (2226389.8158654715 2273030.926987689), (3339584.723798207 1118889.9748579597))|
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
select st_astext(st_transform(st_setsrid(st_geomfromwkt("MULTIPOINT ((10 40), (40 30), (20 20), (30 10))"), 4326) as geom, 3857))
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|convert_to(st_transform(geom, 3857)) |
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|MULTIPOINT ((1113194.9079327357 4865942.279503176), (4452779.631730943 3503549.843504374), (2226389.8158654715 2273030.926987689), (3339584.723798207 1118889.9748579597))|
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
df <- createDataFrame(data.frame(wkt = "MULTIPOINT ((10 40), (40 30), (20 20), (30 10))"))
df <- withColumn(df, 'geom', st_setsrid(st_geomfromwkt(column('wkt')), lit(4326L)))
showDF(select(df, st_astext(st_transform(column('geom'), lit(3857L)))), truncate=F)
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|convert_to(st_transform(geom, 3857)) |
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|MULTIPOINT ((1113194.9079327357 4865942.279503176), (4452779.631730943 3503549.843504374), (2226389.8158654715 2273030.926987689), (3339584.723798207 1118889.9748579597))|
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
Note
If geom does not have an associated SRID, use st_setsrid to set this before calling st_transform.
Changed in 0.4 series
st_srid, st_setsrid, and st_transform operate best on Mosaic Internal Geometry across language bindings, so recommend calling st_geomfromwkt or st_geomfromwkb to convert from WKT and WKB.
You can convert back after the transform, e.g. using st_astext or st_asbinary.
Alternatively, you can use st_updatesrid to transform WKB, WKB, GeoJSON, or Mosaic Internal Geometry
by specifying the srcSRID and dstSRID.
st_triangulate
- st_triangulate(pointsArray, linesArray, mergeTolerance, snapTolerance, splitPointFinder)
Performs a conforming Delaunay triangulation using the points in
pointsArrayincludinglinesArrayas constraint / break lines.There are two ‘tolerance’ parameters for the algorithm.
mergeTolerancesets the point merging tolerance of the triangulation algorithm, i.e. before the initial triangulation is performed, nearby points inpointsArraycan be merged in order to speed up the triangulation process. A value of zero means all points are considered for triangulation.snapTolerancesets the tolerance for post-processing the results of the triangulation, i.e. matching the vertices of the output triangles to input points / lines. This is necessary as the algorithm often returns null height / Z values. Setting this to a large value may result in the incorrect Z values being assigned to the output triangle vertices (especially whenlinesArraycontains very densely spaced segments). Setting this value to zero may result in the output triangle vertices being assigned a null Z value.
Both tolerance parameters are expressed in the same units as the projection of the input point geometries.
Additionally, you have control over the algorithm used to find split points on the constraint lines. The recommended default option here is the “NONENCROACHING” algorithm. You can also use the “MIDPOINT” algorithm if you find the constraint fitting process fails to converge. For full details of these options see the JTS reference here.
This is a generator expression and the resulting DataFrame will contain one row per triangle returned by the algorithm.
- Parameters:
pointsArray (Column (ArrayType(Geometry))) – Array of geometries respresenting the points to be triangulated
linesArray (Column (ArrayType(Geometry))) – Array of geometries respresenting the lines to be used as constraints
mergeTolerance (Column (DoubleType)) – A tolerance used to coalesce points in close proximity to each other before performing triangulation.
snapTolerance (Column (DoubleType)) – A snapping tolerance used to relate created points to their corresponding lines for elevation interpolation.
splitPointFinder (Column (StringType)) – Algorithm used for finding split points on constraint lines. Options are “NONENCROACHING” and “MIDPOINT”.
- Return type:
Column (Geometry)
- Example:
df = (
spark.createDataFrame(
[
["POINT Z (2 1 0)"],
["POINT Z (3 2 1)"],
["POINT Z (1 3 3)"],
["POINT Z (0 2 2)"],
],
["wkt"],
)
.groupBy()
.agg(collect_list("wkt").alias("masspoints"))
.withColumn("breaklines", array(lit("LINESTRING EMPTY")))
.withColumn("triangles", st_triangulate("masspoints", "breaklines", lit(0.0), lit(0.01), "NONENCROACHING"))
)
df.show(2, False)
+---------------------------------------+
|triangles |
+---------------------------------------+
|POLYGON Z((0 2 2, 2 1 0, 1 3 3, 0 2 2))|
|POLYGON Z((1 3 3, 2 1 0, 3 2 1, 1 3 3))|
+---------------------------------------+
val df = Seq(
Seq(
"POINT Z (2 1 0)", "POINT Z (3 2 1)",
"POINT Z (1 3 3)", "POINT Z (0 2 2)"
)
)
.toDF("masspoints")
.withColumn("breaklines", array().cast(ArrayType(StringType)))
.withColumn("triangles",
st_triangulate(
$"masspoints", $"breaklines",
lit(0.0), lit(0.01), lit("NONENCROACHING")
)
)
df.select(st_astext($"triangles")).show(2, false)
+------------------------------+
|st_astext(triangles) |
+------------------------------+
|POLYGON ((0 2, 2 1, 1 3, 0 2))|
|POLYGON ((1 3, 2 1, 3 2, 1 3))|
+------------------------------+
SELECT
ST_TRIANGULATE(
ARRAY(
"POINT Z (2 1 0)",
"POINT Z (3 2 1)",
"POINT Z (1 3 3)",
"POINT Z (0 2 2)"
),
ARRAY("LINESTRING EMPTY"),
DOUBLE(0.0), DOUBLE(0.01),
"NONENCROACHING"
)
+---------------------------------------+
|triangles |
+---------------------------------------+
|POLYGON Z((0 2 2, 2 1 0, 1 3 3, 0 2 2))|
|POLYGON Z((1 3 3, 2 1 0, 3 2 1, 1 3 3))|
+---------------------------------------+
sdf <- createDataFrame(
data.frame(
points = c(
"POINT Z (3 2 1)", "POINT Z (2 1 0)",
"POINT Z (1 3 3)", "POINT Z (0 2 2)"
)
)
)
sdf <- agg(groupBy(sdf), masspoints = collect_list(column("points")))
sdf <- withColumn(sdf, "breaklines", expr("array('LINESTRING EMPTY')"))
result <- select(sdf, st_triangulate(
column("masspoints"), column("breaklines"),
lit(0.0), lit(0.01), lit("NONENCROACHING")
)
showDF(result, truncate=F)
+---------------------------------------+
|triangles |
+---------------------------------------+
|POLYGON Z((0 2 2, 2 1 0, 1 3 3, 0 2 2))|
|POLYGON Z((1 3 3, 2 1 0, 3 2 1, 1 3 3))|
+---------------------------------------+
st_translate
- st_translate(col, xd, yd)
Translates
geomto a new location using the distance parametersxdandyd.- Parameters:
col (Column) – Geometry
xd (Column (DoubleType)) – Offset in the x-direction
yd (Column (DoubleType)) – Offset in the y-direction
- Return type:
Column
- Example:
df = spark.createDataFrame([{'wkt': 'MULTIPOINT ((10 40), (40 30), (20 20), (30 10))'}])
df.select(st_translate('wkt', lit(10), lit(-5))).show(1, False)
+----------------------------------------------+
|st_translate(wkt, 10, -5) |
+----------------------------------------------+
|MULTIPOINT ((20 35), (50 25), (30 15), (40 5))|
+----------------------------------------------+
val df = List(("MULTIPOINT ((10 40), (40 30), (20 20), (30 10))")).toDF("wkt")
df.select(st_translate(col("wkt"), lit(10d), lit(-5d))).show(false)
+----------------------------------------------+
|st_translate(wkt, 10, -5) |
+----------------------------------------------+
|MULTIPOINT ((20 35), (50 25), (30 15), (40 5))|
+----------------------------------------------+
SELECT st_translate("MULTIPOINT ((10 40), (40 30), (20 20), (30 10))", 10d, -5d)
+----------------------------------------------+
|st_translate(wkt, 10, -5) |
+----------------------------------------------+
|MULTIPOINT ((20 35), (50 25), (30 15), (40 5))|
+----------------------------------------------+
df <- createDataFrame(data.frame(wkt = "MULTIPOINT ((10 40), (40 30), (20 20), (30 10))"))
showDF(select(df, st_translate(column('wkt'), lit(10), lit(-5))))
+----------------------------------------------+
|st_translate(wkt, 10, -5) |
+----------------------------------------------+
|MULTIPOINT ((20 35), (50 25), (30 15), (40 5))|
+----------------------------------------------+
st_unaryunion
- st_unaryunion(col)
Returns a geometry that represents the point set union of the given geometry
- Parameters:
col (Column) – Geometry
- Return type:
Column: Geometry
- Example:
df = spark.createDataFrame([{'wkt': 'MULTIPOLYGON (((10 10, 20 10, 20 20, 10 20, 10 10)), ((15 15, 25 15, 25 25, 15 25, 15 15)))'}])
df.select(st_unaryunion('wkt')).show()
+-------------------------------------------------------------------------+
| st_unaryunion(wkt, 2.0) |
+-------------------------------------------------------------------------+
|POLYGON ((20 15, 20 10, 10 10, 10 20, 15 20, 15 25, 25 25, 25 15, 20 15))|
+-------------------------------------------------------------------------+
val df = List(("MULTIPOLYGON (((10 10, 20 10, 20 20, 10 20, 10 10)), ((15 15, 25 15, 25 25, 15 25, 15 15)))")).toDF("wkt")
df.select(st_unaryunion(col("wkt"))).show()
+-------------------------------------------------------------------------+
| st_unaryunion(wkt, 2.0) |
+-------------------------------------------------------------------------+
|POLYGON ((20 15, 20 10, 10 10, 10 20, 15 20, 15 25, 25 25, 25 15, 20 15))|
+-------------------------------------------------------------------------+
SELECT st_unaryunion("MULTIPOLYGON (((10 10, 20 10, 20 20, 10 20, 10 10)), ((15 15, 25 15, 25 25, 15 25, 15 15)))")
+-------------------------------------------------------------------------+
| st_unaryunion(wkt, 2.0) |
+-------------------------------------------------------------------------+
|POLYGON ((20 15, 20 10, 10 10, 10 20, 15 20, 15 25, 25 25, 25 15, 20 15))|
+-------------------------------------------------------------------------+
df <- createDataFrame(data.frame(wkt = "MULTIPOLYGON (((10 10, 20 10, 20 20, 10 20, 10 10)), ((15 15, 25 15, 25 25, 15 25, 15 15)))")
showDF(select(df, st_unaryunion(column("wkt"))), truncate=F)
+-------------------------------------------------------------------------+
| st_unaryunion(wkt, 2.0) |
+-------------------------------------------------------------------------+
|POLYGON ((20 15, 20 10, 10 10, 10 20, 15 20, 15 25, 25 25, 25 15, 20 15))|
+-------------------------------------------------------------------------+
st_union
- st_union(left_geom, right_geom)
Returns the point set union of the input geometries. Also, see st_union_agg function.
- Parameters:
left_geom (Column) – Geometry
right_geom (Column) – Geometry
- Return type:
Column: Geometry
- Example:
df = spark.createDataFrame([{'left': 'POLYGON ((10 10, 20 10, 20 20, 10 20, 10 10))', 'right': 'POLYGON ((15 15, 25 15, 25 25, 15 25, 15 15))'}])
df.select(st_union(col('left'), col('right'))).show()
+-------------------------------------------------------------------------+
| st_union(left, right) |
+-------------------------------------------------------------------------+
|POLYGON ((20 15, 20 10, 10 10, 10 20, 15 20, 15 25, 25 25, 25 15, 20 15))|
+-------------------------------------------------------------------------+
val df = List(("POLYGON ((10 10, 20 10, 20 20, 10 20, 10 10))", "POLYGON ((15 15, 25 15, 25 25, 15 25, 15 15))")).toDF("left", "right")
df.select(st_union(col('left'), col('right'))).show()
+-------------------------------------------------------------------------+
| st_union(left, right) |
+-------------------------------------------------------------------------+
|POLYGON ((20 15, 20 10, 10 10, 10 20, 15 20, 15 25, 25 25, 25 15, 20 15))|
+-------------------------------------------------------------------------+
SELECT st_union("POLYGON ((10 10, 20 10, 20 20, 10 20, 10 10))", "POLYGON ((15 15, 25 15, 25 25, 15 25, 15 15))")
+-------------------------------------------------------------------------+
| st_union(left, right) |
+-------------------------------------------------------------------------+
|POLYGON ((20 15, 20 10, 10 10, 10 20, 15 20, 15 25, 25 25, 25 15, 20 15))|
+-------------------------------------------------------------------------+
df <- createDataFrame(data.frame(p1 = "POLYGON ((10 10, 20 10, 20 20, 10 20, 10 10))", p2 = "POLYGON ((15 15, 25 15, 25 25, 15 25, 15 15))"))
showDF(select(df, st_union(column("p1"), column("p2"))), truncate=F)
+-------------------------------------------------------------------------+
| st_union(left, right) |
+-------------------------------------------------------------------------+
|POLYGON ((20 15, 20 10, 10 10, 10 20, 15 20, 15 25, 25 25, 25 15, 20 15))|
+-------------------------------------------------------------------------+
st_updatesrid
- st_updatesrid(geom, srcSRID, destSRID)
Updates the SRID of the input geometry
geomfromsrcSRIDtodestSRID. Geometry can be any supported [WKT, WKB, GeoJSON, Mosaic Internal Geometry].Transformed geometry is returned in the same format provided.
- Parameters:
geom (Column) – Geometry to update the SRID
srcSRID (Column: Integer) – Original SRID
destSRID (Column: Integer) – New SRID
- Return type:
Column
- Example:
spark.createDataFrame([
["""POLYGON ((12.1773911 66.2559307, 12.1773712 66.2558954, 12.177202 66.2557779, 12.1770325 66.2557476, 12.1769472 66.2557593,
12.1769162 66.2557719, 12.1769186 66.2557965, 12.1770058 66.2558191, 12.1771788 66.2559348, 12.1772692 66.2559828,
12.1773634 66.2559793, 12.1773911 66.2559307))"""]], ["geom_wkt"])\
.select(mos.st_updatesrid("geom_wkt", F.lit(4326), F.lit(3857))).display()
+---------------------------------------------------------------+
| st_updatesrid(geom_wkt, CAST(4326 AS INT), CAST(3857 AS INT)) |
+---------------------------------------------------------------+
| POLYGON ((1355580.9764425415 9947245.380472444, ... )) |
+---------------------------------------------------------------+
val df = List("""POLYGON ((12.1773911 66.2559307, 12.1773712 66.2558954, 12.177202 66.2557779, 12.1770325 66.2557476,
12.1769472 66.2557593, 12.1769162 66.2557719, 12.1769186 66.2557965, 12.1770058 66.2558191, 12.1771788 66.2559348,
12.1772692 66.2559828, 12.1773634 66.2559793, 12.1773911 66.2559307))""").toDF("geom_wkt")
df.select(st_updatesrid(col("geom_wkt"), lit(4326), lit(3857))).show
+---------------------------------------------------------------+
| st_updatesrid(geom_wkt, CAST(4326 AS INT), CAST(3857 AS INT)) |
+---------------------------------------------------------------+
| POLYGON ((1355580.9764425415 9947245.380472444, ... )) |
+---------------------------------------------------------------+
select st_updatesrid(geom_wkt, 4326, 3857)
from (
select """POLYGON ((12.1773911 66.2559307, 12.1773712 66.2558954, 12.177202 66.2557779, 12.1770325 66.2557476,
12.1769472 66.2557593, 12.1769162 66.2557719, 12.1769186 66.2557965, 12.1770058 66.2558191, 12.1771788 66.2559348,
12.1772692 66.2559828, 12.1773634 66.2559793, 12.1773911 66.2559307))""" as geom_wkt
)
+---------------------------------------------------------------+
| st_updatesrid(geom_wkt, CAST(4326 AS INT), CAST(3857 AS INT)) |
+---------------------------------------------------------------+
| POLYGON ((1355580.9764425415 9947245.380472444, ... )) |
+---------------------------------------------------------------+
df <- createDataFrame(data.frame(geom_wkt = "POLYGON (( ... ))"))
showDF(select(df, st_updatesrid(column("wkt"), lit(4326L), lit(3857L))), truncate=F)
+---------------------------------------------------------------+
| st_updatesrid(geom_wkt, CAST(4326 AS INT), CAST(3857 AS INT)) |
+---------------------------------------------------------------+
| POLYGON ((1355580.9764425415 9947245.380472444, ... )) |
+---------------------------------------------------------------+
st_x
- st_x(col)
Returns the x coordinate of the centroid point of the input geometry.
- Parameters:
col (Column) – Geometry
- Return type:
Column: DoubleType
- Example:
df = spark.createDataFrame([{'wkt': 'POINT (30 10)'}])
df.select(st_x('wkt')).show()
+-----------------+
|st_x(wkt) |
+-----------------+
| 30.0|
+-----------------+
val df = List(("POINT (30 10)")).toDF("wkt")
df.select(st_x(col("wkt"))).show()
+-----------------+
|st_x(wkt) |
+-----------------+
| 30.0|
+-----------------+
SELECT st_x("POINT (30 10)")
+-----------------+
|st_x(wkt) |
+-----------------+
| 30.0|
+-----------------+
df <- createDataFrame(data.frame(wkt = "POINT (30 10)"))
showDF(select(df, st_x(column("wkt"))), truncate=F)
+-----------------+
|st_x(wkt) |
+-----------------+
| 30.0|
+-----------------+
st_xmax
- st_xmax(col)
Returns the largest x coordinate in the input geometry.
- Parameters:
col (Column) – Geometry
- Return type:
Column: DoubleType
- Example:
df = spark.createDataFrame([{'wkt': 'POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))'}])
df.select(st_xmax('wkt')).show()
+-----------------+
|st_minmaxxyz(wkt)|
+-----------------+
| 40.0|
+-----------------+
val df = List(("POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))")).toDF("wkt")
df.select(st_xmax(col("wkt"))).show()
+-----------------+
|st_minmaxxyz(wkt)|
+-----------------+
| 40.0|
+-----------------+
SELECT st_xmax("POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))")
+-----------------+
|st_minmaxxyz(wkt)|
+-----------------+
| 40.0|
+-----------------+
df <- createDataFrame(data.frame(wkt = "POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))"))
showDF(select(df, st_xmax(column("wkt"))), truncate=F)
+-----------------+
|st_minmaxxyz(wkt)|
+-----------------+
| 40.0|
+-----------------+
st_xmin
- st_xmin(col)
Returns the smallest x coordinate in the input geometry.
- Parameters:
col (Column) – Geometry
- Return type:
Column: DoubleType
- Example:
df = spark.createDataFrame([{'wkt': 'POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))'}])
df.select(st_xmin('wkt')).show()
+-----------------+
|st_minmaxxyz(wkt)|
+-----------------+
| 10.0|
+-----------------+
val df = List(("POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))")).toDF("wkt")
df.select(st_xmin(col("wkt"))).show()
+-----------------+
|st_minmaxxyz(wkt)|
+-----------------+
| 10.0|
+-----------------+
SELECT st_xmin("POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))")
+-----------------+
|st_minmaxxyz(wkt)|
+-----------------+
| 10.0|
+-----------------+
df <- createDataFrame(data.frame(wkt = "POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))"))
showDF(select(df, st_xmin(column("wkt"))), truncate=F)
+-----------------+
|st_minmaxxyz(wkt)|
+-----------------+
| 10.0|
+-----------------+
st_y
- st_y(col)
Returns the y coordinate of the centroid point of the input geometry.
- Parameters:
col (Column) – Geometry
- Return type:
Column: DoubleType
- Example:
df = spark.createDataFrame([{'wkt': 'POINT (30 10)'}])
df.select(st_y('wkt')).show()
+-----------------+
|st_y(wkt) |
+-----------------+
| 10.0|
+-----------------+
val df = List(("POINT (30 10)")).toDF("wkt")
df.select(st_y(col("wkt"))).show()
+-----------------+
|st_y(wkt) |
+-----------------+
| 10.0|
+-----------------+
SELECT st_y("POINT (30 10)")
+-----------------+
|st_y(wkt) |
+-----------------+
| 10.0|
+-----------------+
df <- createDataFrame(data.frame(wkt = "POINT (30 10)"))
showDF(select(df, st_y(column("wkt"))), truncate=F)
+-----------------+
|st_y(wkt) |
+-----------------+
| 10.0|
+-----------------+
st_ymax
- st_ymax(col)
Returns the largest y coordinate in the input geometry.
- Parameters:
col (Column) – Geometry
- Return type:
Column: DoubleType
- Example:
df = spark.createDataFrame([{'wkt': 'POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))'}])
df.select(st_ymax('wkt')).show()
+-----------------+
|st_minmaxxyz(wkt)|
+-----------------+
| 40.0|
+-----------------+
val df = List(("POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))")).toDF("wkt")
df.select(st_ymax(col("wkt"))).show()
+-----------------+
|st_minmaxxyz(wkt)|
+-----------------+
| 40.0|
+-----------------+
SELECT st_ymax("POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))")
+-----------------+
|st_minmaxxyz(wkt)|
+-----------------+
| 40.0|
+-----------------+
df <- createDataFrame(data.frame(wkt = "POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))"))
showDF(select(df, st_ymax(column("wkt"))), truncate=F)
+-----------------+
|st_minmaxxyz(wkt)|
+-----------------+
| 40.0|
+-----------------+
st_ymin
- st_ymin(col)
Returns the smallest y coordinate in the input geometry.
- Parameters:
col (Column) – Geometry
- Return type:
Column: DoubleType
- Example:
df = spark.createDataFrame([{'wkt': 'POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))'}])
df.select(st_ymin('wkt')).show()
+-----------------+
|st_minmaxxyz(wkt)|
+-----------------+
| 10.0|
+-----------------+
val df = List(("POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))")).toDF("wkt")
df.select(st_ymin(col("wkt"))).show()
+-----------------+
|st_minmaxxyz(wkt)|
+-----------------+
| 10.0|
+-----------------+
SELECT st_ymin("POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))")
+-----------------+
|st_minmaxxyz(wkt)|
+-----------------+
| 10.0|
+-----------------+
df <- createDataFrame(data.frame(wkt = "POLYGON ((30 10, 40 40, 20 40, 10 20, 30 10))"))
showDF(select(df, st_ymin(column("wkt"))), truncate=F)
+-----------------+
|st_minmaxxyz(wkt)|
+-----------------+
| 10.0|
+-----------------+
st_z
- st_z(col)
Returns the z coordinate of an arbitrary point of the input geometry geom.
- Parameters:
col (Column) – Point Geometry
- Return type:
Column: DoubleType
- Example:
df = spark.createDataFrame([{'wkt': 'POINT (30 10 20)'}])
df.select(st_z('wkt')).show()
+-----------------+
|st_z(wkt) |
+-----------------+
| 20.0|
+-----------------+
val df = List(("POINT (30 10 20)")).toDF("wkt")
df.select(st_z(col("wkt"))).show()
+-----------------+
|st_z(wkt) |
+-----------------+
| 20.0|
+-----------------+
SELECT st_z("POINT (30 10 20)")
+-----------------+
|st_z(wkt) |
+-----------------+
| 20.0|
+-----------------+
df <- createDataFrame(data.frame(wkt = "POINT (30 10 20)"))
showDF(select(df, st_z(column("wkt"))), truncate=F)
+-----------------+
|st_z(wkt) |
+-----------------+
| 20.0|
+-----------------+
st_zmax
- st_zmax(col)
Returns the largest z coordinate in the input geometry.
- Parameters:
col (Column) – Geometry
- Return type:
Column: DoubleType
- Example:
df = spark.createDataFrame([{'wkt': 'POINT (30 10 20)'}])
df.select(st_zmax('wkt')).show()
+-----------------+
|st_minmaxxyz(wkt)|
+-----------------+
| 20.0|
+-----------------+
val df = List(("POINT (30 10 20)")).toDF("wkt")
df.select(st_zmax(col("wkt"))).show()
+-----------------+
|st_minmaxxyz(wkt)|
+-----------------+
| 20.0|
+-----------------+
SELECT st_zmax("POINT (30 10 20)")
+-----------------+
|st_minmaxxyz(wkt)|
+-----------------+
| 20.0|
+-----------------+
df <- createDataFrame(data.frame(wkt = "POINT (30 10 20)"))
showDF(select(df, st_zmax(column("wkt"))), truncate=F)
+-----------------+
|st_minmaxxyz(wkt)|
+-----------------+
| 20.0|
+-----------------+
st_zmin
- st_zmin(col)
Returns the smallest z coordinate in the input geometry.
- Parameters:
col (Column) – Geometry
- Return type:
Column: DoubleType
- Example:
df = spark.createDataFrame([{'wkt': 'POINT (30 10 20)'}])
df.select(st_zmin('wkt')).show()
+-----------------+
|st_minmaxxyz(wkt)|
+-----------------+
| 20.0|
+-----------------+
val df = List(("POINT (30 10 20)")).toDF("wkt")
df.select(st_zmin(col("wkt"))).show()
+-----------------+
|st_minmaxxyz(wkt)|
+-----------------+
| 20.0|
+-----------------+
SELECT st_zmin("POINT (30 10 20)")
+-----------------+
|st_minmaxxyz(wkt)|
+-----------------+
| 20.0|
+-----------------+
df <- createDataFrame(data.frame(wkt = "POINT (30 10 20)"))
showDF(select(df, st_zmin(column("wkt"))), truncate=F)
+-----------------+
|st_minmaxxyz(wkt)|
+-----------------+
| 20.0|
+-----------------+