Installation
Table of Contents
Pre-requisites
1. Databricks Workspace Requirements
1.1 Databricks Workspace Access
You must have access to a Databricks workspace to install and use Lakebridge:
- Production/Enterprise Workspace: Recommended for production migrations
- Development Workspace: Suitable for testing and development
- Free Databricks Workspace: Available at databricks.com/try-databricks - Perfect for evaluation and learning
For evaluation purposes, using a free Databricks workspace with a Personal Access Token is the fastest way to get started. This combination requires no enterprise approvals and can be set up in minutes.
1.2 Databricks CLI Installation & Configuration
Install Databricks CLI - Ensure that you have the Databricks Command-Line Interface (CLI) installed on your machine. Refer to the installation instructions provided for Linux, MacOS, and Windows, available here.
Installing the Databricks CLI in different OS:
- MacOS & Linux
- Windows
- Linux without brew


#!/usr/bin/env bash
#install dependencies
apt update && apt install -y curl sudo unzip
#install databricks cli
curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/v0.242.0/install.sh | sudo sh
Configure Databricks CLI - Details can be found here.
Authentication Options:
- Personal Access Token (PAT): Recommended for individual users - Generate from User Settings → Developer → Access Tokens
- Service Principal: Recommended for automated/production deployments - Requires admin privileges to create
Profile Configuration:
Additionally, Lakebridge requires the profile used for the Databricks CLI to specify a cluster_id, to do this, you can either:
- Edit your
~/.databrickscfgfile directly and enter acluster_idfor the profile you're using or - The flag
--configure-clustergives you the prompt to select the cluster_id from the available clusters on the workspace specified on the selected profile.
databricks configure --host <host> --configure-cluster --profile <profile_name>
- Alternatively you can use the environment variable
DATABRICKS_CLUSTER_IDto set the cluster id you would want to use for your profile before running thedatabricks configurecommand.
export DATABRICKS_CLUSTER_ID=<cluster_id>
databricks configure --host <host> --profile <profile_name>
Verification: Run databricks clusters list to confirm connectivity
2. Software Requirements
2.1 Python
Version Required: Python between 3.10.1 and 3.13.x (inclusive).
Check Python version on Windows, macOS, and Unix:

Verification: Run python --version to confirm installation
Note: Python 3.14 is not currently supported.
2.2 Java
Version Required: Java 11 or above
- Recommended: OpenJDK 11 or later (available via system package managers)
- Purpose: Required for the Morpheus transpiler component that powers code conversion
- Verification: Run
java -versionto confirm installation
3. Network & Environment Access
The following network endpoints must be accessible from your installation environment:
3.1 GitHub Access
Access to Databricks Labs GitHub repository for downloading Lakebridge.
- Repository: github.com/databrickslabs/lakebridge
- Purpose: Download latest official Lakebridge installation packages
3.2 Maven Central Repository
Access to Maven Central for downloading transpiler plugins and dependencies.
- Repository: central.sonatype.com
- Purpose: Download latest version of the transpiler plugins
3.3 PyPI (Python Package Index)
Access to PyPI for Python package dependencies.
- Repository: pypi.org
- Purpose: Install Python dependencies
If you are operating in a hardened environment with internet restrictions, firewall rules, or security policies, you must whitelist the following resources before installation:
- GitHub:
github.com,raw.githubusercontent.com- For Lakebridge source code - Maven Central:
repo1.maven.org,central.sonatype.com- For transpiler plugins - PyPI:
pypi.org,files.pythonhosted.org- For Python packages - Python Downloads:
python.org- If installing Python - Java Downloads:
oracle.comor OpenJDK mirrors - If installing Java
Action Required: Contact your IT Security, CyberSecOps, or Infrastructure team to request whitelisting. Consider setting up a private repository/artifact mirror for organizations with strict internet access policies.
3.4 Private Repository Hosting (Optional)
For organizations with restricted internet access or security requirements:
- Purpose: Internal hosting and distribution of Lakebridge components
- Options: Artifactory, Nexus
- Benefits: Control over versions, security scanning, compliance validation
Pre-Installation Checklist
Verify all prerequisites before proceeding:
- ☐ Databricks workspace access confirmed (production, dev, or free trial)
- ☐ Databricks CLI installed on your machine
- ☐ Databricks CLI configured with PAT or Service Principal for your workspace
- ☐ CLI connectivity verified (
databricks clusters listsucceeds) - ☐ Python between 3.10.1 and 3.13.x (inclusive) installed and verified (
python --version) - ☐ Java 11+ installed and verified (
java -version) - ☐ Network access to GitHub confirmed
- ☐ Network access to Maven Central confirmed
- ☐ Network access to PyPI confirmed
- ☐ (If applicable) All required resources whitelisted in restricted environments
- ☐ (If applicable) Private repository configured for package hosting
Install Lakebridge
Upon completing the environment setup, install Lakebridge by executing the following command:
databricks labs install lakebridge
This will install Lakebridge using the workspace details set in the DEFAULT profile. If you want to install it using a different profile, you can specify the profile name using the --profile flag.
databricks labs install lakebridge --profile <profile_name>
To view all the profiles available, you can run the following command:
databricks auth profiles

Verify Installation
Verify the successful installation by executing the provided command; confirmation of a successful installation is indicated when the displayed output aligns with the example below:
Command:
databricks labs lakebridge --help
Should output:
Code Transpiler and Data Reconciliation tool for Accelerating Data onboarding to Databricks from EDW, CDW and other ETL sources.
Usage:
databricks labs lakebridge [command]
Available Commands:
aggregates-reconcile Reconcile source and target data residing on Databricks using aggregated metrics
analyze Analyze existing non-Databricks database or ETL sources
configure-database-profiler Configure database profiler
configure-reconcile Configure 'reconcile' dependencies
describe-transpile Describe installed transpilers
install-transpile Install & optionally configure 'transpile' dependencies
reconcile Reconcile source and target data residing on Databricks
transpile Transpile SQL/ETL sources to Databricks-compatible code
Flags:
-h, --help help for lakebridge
Global Flags:
--debug enable debug logging
-o, --output type output type: text or json (default text)
-p, --profile string ~/.databrickscfg profile
-t, --target string bundle target to use (if applicable)
Use "databricks labs lakebridge [command] --help" for more information about a command.
Install Transpile
Upon completing the environment setup, you can install the out of the box transpilers by executing the following command. This command will also prompt for the required configuration elements so that you don't need to include them in your command-line call every time.
databricks labs lakebridge install-transpile

Override the default[Bladebridge] config:
There is an option for you to override the default config file that Lakebridge uses for converting source code from dialects like datastage, synapse,
oracle etc. During installation you may use your own custom config file and Lakebridge will override the config with the one you would provide. You can only setup this
override during installation.
Specify the config file to override the default[Bladebridge] config during installation:
Specify the config file to override the default[Bladebridge] config - press <enter> for none (default: <none>): <local_full_path>/custom_<source>2databricks.json
Verify Installation
Verify the successful installation by executing the provided command; confirmation of a successful installation is indicated when the displayed output aligns with the example output:
Command:
databricks labs lakebridge transpile --help
Should output:
Transpile SQL/ETL sources to Databricks-compatible code
Usage:
databricks labs lakebridge transpile [flags]
Flags:
--catalog-name name (Optional) Catalog name, only used when validating converted code
--error-file-path path (Optional) Local path where a log of conversion errors (if any) will be written
-h, --help help for transpile
--input-source path (Optional) Local path of the sources to be convert
--output-folder path (Optional) Local path where converted code will be written
--overrides-file path (Optional) Local path of a file containing transpiler overrides, if supported by the transpiler in use
--schema-name name (Optional) Schema name, only used when validating converted code
--skip-validation string (Optional) Whether to skip validating the output ('true') after conversion or not ('false')
--source-dialect string (Optional) The source dialect to use when performing conversion
--target-technology string (Optional) Target technology to use for code generation, if supported by the transpiler in use
--transpiler-config-path path (Optional) Local path to the configuration file of the transpiler to use for conversion
Global Flags:
--debug enable debug logging
-o, --output type output type: text or json (default text)
-p, --profile string ~/.databrickscfg profile
-t, --target string bundle target to use (if applicable)
Configure Reconcile
Once you're ready to reconcile your data, you need to configure the reconcile module.
databricks labs lakebridge configure-reconcile
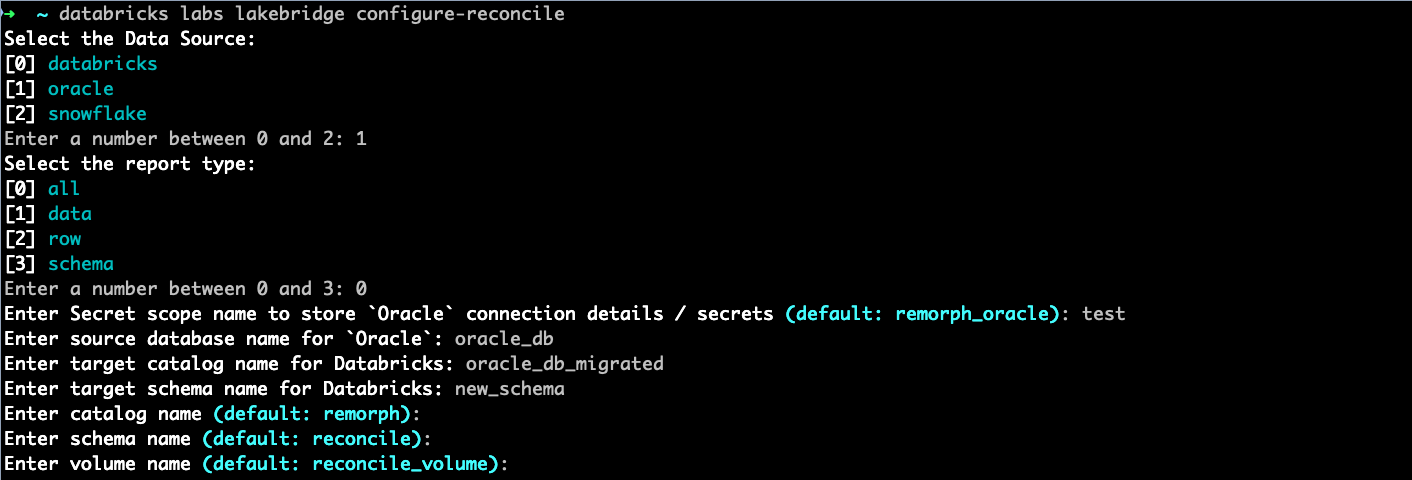
SQL Warehouse for Reconcile
While configuring the reconcile properties, lakebridge by default creates a SQL warehouse. lakebridge uses user profile to authenticate to any Databricks resource and hence
if the user running this command doesn't have permission to create SQL warehouse, the configure-reconcile would fail. In this case users can provide the
warehouse_id of an already created SQL warehouse that they have atleast CAN_USE permission on in the databricks profile (~/.databrickscfg) using which they
are running the lakebridge commands and lakebridge would use that warehouse to complete the reconcile configuration instead of trying to create a new one.
This is how the profile would look like:
[profile-name]
host = <your-workspace-url>
...
warehouse_id = <your-warehouse-id>
Verify Configuration
Verify the successful configuration by executing the provided command; confirmation of a successful configuration is indicated when the displayed output aligns with the example screenshot provided:
Command:
databricks labs lakebridge reconcile --help
Should output:
Reconcile source and target data residing on Databricks
Usage:
databricks labs lakebridge reconcile [flags]
Flags:
-h, --help help for reconcile
Global Flags:
--debug enable debug logging
-o, --output type output type: text or json (default text)
-p, --profile string ~/.databrickscfg profile
-t, --target string bundle target to use (if applicable)