Motivation
Current data quality frameworks often fall short of providing detailed explanations for specific row or column data quality issues and are primarily designed for complete datasets, making integration into streaming workloads difficult. They cannot quarantine invalid data and have compatibility issues with Databricks Runtime.
This project introduces a simple but powerful Python validation framework for assessing the data quality of PySpark DataFrames and Tables. It enables both at-rest validation (post-factum monitoring of already persisted data) and in-transit validation (pre-commit checks before data is written). The validation output includes detailed information on why specific rows and columns have issues, allowing for quicker identification and resolution of data quality problems. The framework offers the ability to quarantine invalid data and investigate quality issues before they escalate.
What makes DQX unique?
✅ Ease of use: DQX is designed to be simple and intuitive, making it easy for various personas — such as data engineers, data scientists, analysts, and business users — to define data quality checks without extensive training.
✅ Detailed information on data quality issues: DQX provides granular insights into data quality problems, allowing users to understand the specific reasons behind data quality failures and reduce troubleshooting time to a minimum.
✅ Streaming support: DQX is built to work seamlessly with both data at-rest and in-transit, enabling real-time data quality validation.
✅ Proactive monitoring: DQX allows you to monitor data quality before writing to the target table, ensuring that only valid data is persisted. Reactive monitoring is also supported.
✅ Custom quality rules: Users can define their own data quality rules easily, making DQX flexible and adaptable to various data quality requirements and domains.
✅ Integration with Databricks: DQX is designed to work seamlessly with Databricks across all engines (Spark Core, Spark Structured Streaming, and Lakeflow Pipelines / DLT) and cluster types (standard and serverless).
✅ Row, Column and Dataset-level rules: DQX supports row-level, column-level and dataset-level data quality checks, allowing for comprehensive validation of data at different granularities.
How DQX works
The core functionality of DQX is to apply data quality checks on PySpark DataFrames. There are two main ways to use it.
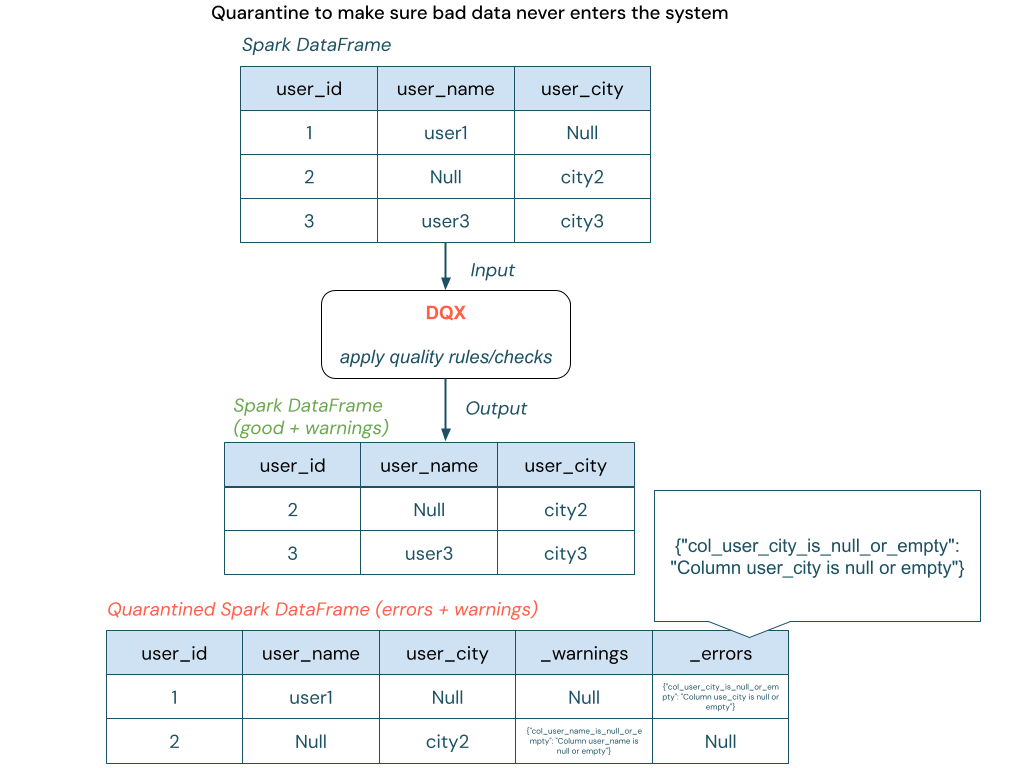
Option 1: Apply checks and quarantine "bad" data.
Apply checks on the DataFrame and quarantine invalid records to ensure "bad" data is never written to the output.
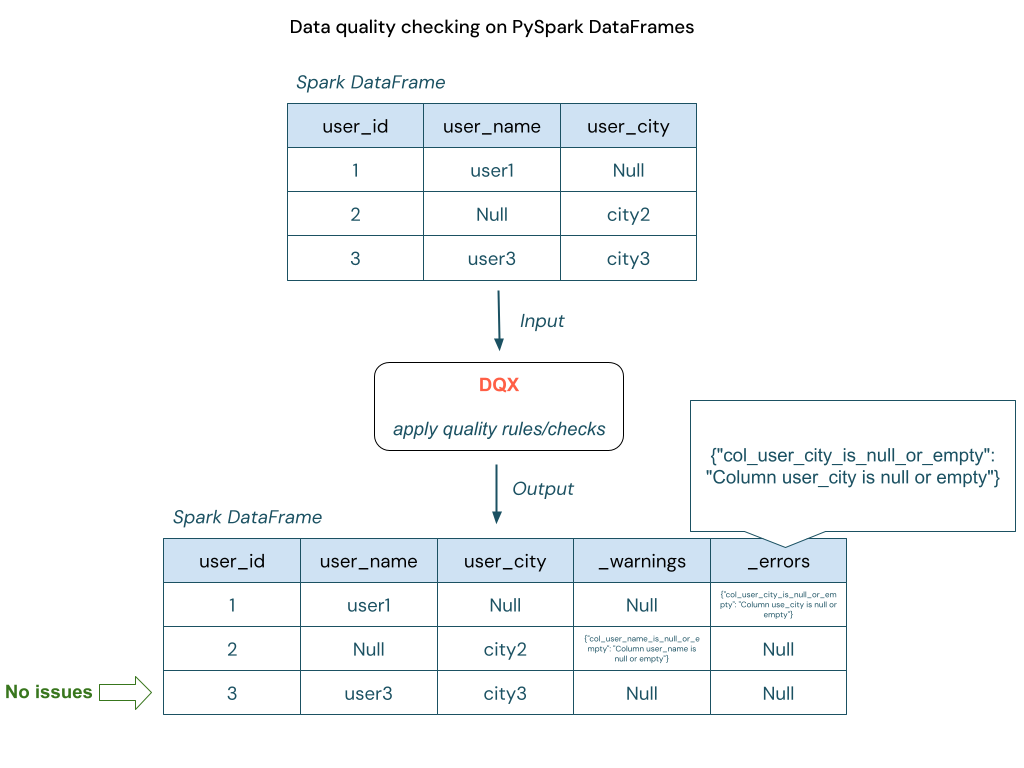
Option 2: Apply checks and annotate "bad" data.
Apply checks on the DataFrame and annotate invalid records as additional columns.
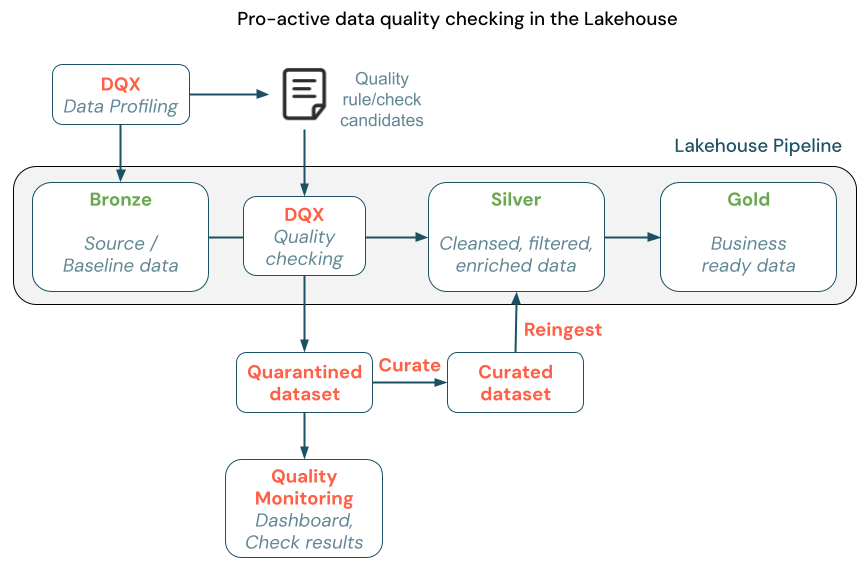
DQX usage in the Lakehouse Architecture
In the Lakehouse architecture, data validation should occur as new data enters the curated layer, preventing bad data from propagating to downstream layers. Additionally, ongoing data quality monitoring between layers is crucial to detect degradation, while monitoring in the gold layer ensures high-quality outputs for end-users and business decisions.
With DQX, you can implement Dead-Letter pattern to quarantine invalid data and re-ingest it after curation to ensure data quality constraints are met.
There are 2 options for applying the quality checks in the Lakehouse architecture:
Pre-commit validation
Apply DQX checks before writing data to the target table, ensuring only valid data is persisted. This requires DQX usage as a library and code-level integration with the data pipelines.
Post-factum monitoring
Run DQX checks on already persisted data as a background process to identify and flag invalid records. This does not require code-level integration with the data pipelines and can be implemented as a separate monitoring workflow.

When to use DQX
DQX is a robust framework designed to define, validate, and enforce data quality rules within Databricks environments. Consider using DQX when you need:
- Granular Validation: Perform row, column and dataset-level quality checks.
- Custom Quality Rules: Define and enforce tailored data quality rules specific to your business needs.
- Data in-transit checking: Monitor and validate data before data is saved.
- Data Quarantining: Isolate and manage bad data to prevent it from affecting downstream processes.
For detecting anomalies of already persisted data (post-factum monitoring), you might also consider using Databricks Lakehouse Monitoring together with DQX.
DQX seamlessly integrates with other Databricks tools and frameworks such as:
- Lakeflow Pipelines (formerly DLT) to apply quality checks in the Lakeflow pipelines or to profile input data and generate Lakeflow expectation candidates.
- dbt to apply DQX quality checks on the output of dbt models.
- dlt-meta framework to apply data quality checks on the output of transformations.